
摘 要: 使用Intel Parallel Amplifier高性能工具,針對模糊C均值聚類算法在多核平臺的性能問題,找出串行程序的熱點(diǎn)和并發(fā)性,提出并行化設(shè)計(jì)方案。基于Intel并行庫TBB(線程構(gòu)建模塊)和OpenMP運(yùn)行時庫函數(shù),對多核平臺下的串行程序進(jìn)行循環(huán)并行化和任務(wù)分配的并行化設(shè)計(jì)。
關(guān)鍵詞: 多核;并行化;模糊C均值算法;Intel Parallel Amplifier;OpenMP
多核處理器的迅速發(fā)展,使得多核化不斷全面普及。為了應(yīng)對計(jì)算機(jī)硬件的發(fā)展要求,盡可能利用多核資源,就要設(shè)計(jì)出相應(yīng)的并行化應(yīng)用程序。多核平臺下的并行化有多種方案,利用英特爾推出的高性能分析工具Intel Parallel Amplifier對串行應(yīng)用程序進(jìn)行性能分析,尋出熱點(diǎn)實(shí)現(xiàn)并行化是其中的一種方法。
模糊C均值聚類算法(FCM)是一種常用的聚類算法,在大規(guī)模數(shù)據(jù)分析、數(shù)據(jù)挖掘、模式識別、圖像處理等領(lǐng)域有著非常廣泛的應(yīng)用。它是給定分類數(shù),通過優(yōu)化目標(biāo)函數(shù)得到樣本點(diǎn)對聚類中心的隸屬度,尋找樣本點(diǎn)的最佳分類方案。本文將多核技術(shù)應(yīng)用到模糊C均值聚類并行算法的設(shè)計(jì)中,把目標(biāo)函數(shù)迭代的過程和處理數(shù)據(jù)的過程并行化,提高聚類過程的效率及多核處理器的利用率。實(shí)驗(yàn)結(jié)果表明,本方法減少了程序的運(yùn)行時間,顯示了多核編程的高效性。
1 模糊C均值聚類算法(FCM)
模糊C均值聚類算法[1]的基本思想是確定每個樣本數(shù)據(jù)隸屬于某個聚類的程度,把隸屬程度相似的樣本數(shù)據(jù)歸為一個聚類。FCM把n個樣本集合X={x1,x2,...,xn}分為c個模糊組,并且求每組的聚類中心Ci(i=1,2,…c),使得目標(biāo)函數(shù)最小,該算法是優(yōu)化目標(biāo)函數(shù)的迭代過程。這個過程從一個隨機(jī)的隸屬度矩陣開始,確定聚類中心計(jì)算目標(biāo)函數(shù),通過迭代過程達(dá)到樣本分類。
初始化:給定樣本數(shù)n,聚類數(shù)c∈[2,n],模糊度m=2,迭代停止閾值?棕。

(4)如果目標(biāo)函數(shù)的改變量小于?棕,停止算法,否者重復(fù)(2)直到改變量小于?棕。為了確保FMC得到一個最優(yōu)解,要不斷調(diào)整隸屬度矩陣,需多次運(yùn)行該算法。
2 多核技術(shù)與工具軟件
2.1 Intel Parallel Amplifier高性能工具
Intel Parallel Amplifier是英特爾在2009年發(fā)布的高性能工具[2],界面設(shè)計(jì)友好,操作簡單方便。開發(fā)人員只需要運(yùn)行工具就可對串行程序進(jìn)行分析,研究分析結(jié)果進(jìn)行并行化設(shè)計(jì),確保多核的完全利用。IPA(Intel Parallel Amplifier)有以下三種類型的性能分析。
(1)熱點(diǎn)(Hotspot)分析:運(yùn)行熱點(diǎn)分析可收集到不同類型的數(shù)據(jù),確定應(yīng)用程序運(yùn)行消耗的時間,以及識別出最耗時的函數(shù)。在執(zhí)行程序時,IPA通過數(shù)據(jù)收集器定期采樣,并在操作系統(tǒng)的協(xié)作下中斷程序收集數(shù)據(jù)。它通過獲取整個程序各個CPU核心的指令指針(IP)采樣,計(jì)算出每個函數(shù)的運(yùn)行時間,再用調(diào)用棧采樣為程序創(chuàng)建調(diào)用關(guān)系樹。
(2)并發(fā)性(Concurrency)分析:運(yùn)行并發(fā)性分析可確定應(yīng)用程序是否有效地利用了所有可執(zhí)行核,識別出最有可能并行化的串行代碼。它與熱點(diǎn)分析一樣收集數(shù)據(jù)信息,但是要比熱點(diǎn)分析多,除了一般的程序運(yùn)行數(shù)據(jù),還有所有可執(zhí)行核的工作情況。最理想的情況是執(zhí)行程序的線程數(shù)等于處理器的可執(zhí)行核數(shù),也就是完全利用(Fully Utilized)。
(3)鎖定和等待(Locks and Waits)分析:在前兩種分析的基礎(chǔ)上,運(yùn)行鎖定和等待分析,可獲得更多的程序運(yùn)行數(shù)據(jù)。
為了測試程序并行優(yōu)化的效果,IPA提供了“比較結(jié)果(Compare Results)”的功能,用來比較串行程序和并行程序性能差別。
2.2 TBB線程構(gòu)建模塊
TBB線程構(gòu)建模塊(Intel Thread Building Blocks)是基于GPLv2開源的、用來實(shí)現(xiàn)并行語義的C++模板庫[3]。TBB提供了高性能可擴(kuò)展的算法,面向任務(wù)編程,支持任何ISO C++編譯器,具有很好的可移植性。本文將Intel并行庫TBB的tbb_block_rang2d和tbb_parallel_for配合使用,前者的作用是對一個二維的半開區(qū)間進(jìn)行可遞歸的粒度劃分;后者的作用可以實(shí)現(xiàn)負(fù)載均衡的并行執(zhí)行固定數(shù)目獨(dú)立循環(huán)迭代體。
2.3 OpenMP并行編程模型
OpenMP是為共享內(nèi)存以及分布式共享內(nèi)存設(shè)計(jì)的多線程并行編程應(yīng)用接口,包含了一套編譯語句以及一個函數(shù)庫,是一個編譯指令和庫函數(shù)的集合[4]。OpenMP也可以用于多核處理器并行程序設(shè)計(jì)中。在OpenMP中線程的創(chuàng)建是通過編譯指導(dǎo)語句實(shí)現(xiàn)的,本文采用sections和section命令。sections被稱作工作分區(qū)編碼,它定義了一個工作分區(qū),然后由section將工作區(qū)劃分成幾個不同的工作段,每個工作段都由多核處理器的每個執(zhí)行核并行執(zhí)行。
3 C均值聚類算法的并行優(yōu)化設(shè)計(jì)
3.1 基本流程
C均值聚類算法串行程序的并行化設(shè)計(jì)可分為以下幾個階段:首先用IPA高性能工具得到熱點(diǎn)函數(shù)的花費(fèi)時間和并行情況,分析串行程序的可并行性[5];然后運(yùn)用TBB和OpenMP進(jìn)行并行優(yōu)化設(shè)計(jì);最后使用IPA的Compare Results功能進(jìn)行比較,測試并行程序的性能效果。基本流程如圖1所示。
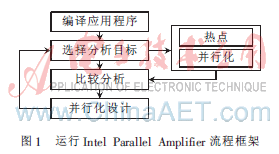
3.2 熱點(diǎn)定位
通過“Hotspot”可以獲得熱點(diǎn)函數(shù)所花費(fèi)的時間,調(diào)用棧信息可以得到它被不同函數(shù)調(diào)用花費(fèi)的時間。IPA采集的數(shù)據(jù)為程序段花費(fèi)的總時間、CPU運(yùn)行的時間、CPU空閑時間、處理器的核數(shù)、執(zhí)行程序的線程數(shù)等。找到熱點(diǎn)函數(shù)后,打開源代碼,分析哪些代碼花費(fèi)處理器時間最多。
3.3 并發(fā)性分析
Concurrency分析可以得到熱點(diǎn)函數(shù)在執(zhí)行過程中各個其他任務(wù)并行執(zhí)行的情況,以及各個線程的任務(wù)分配情況。IPA并發(fā)性分析不僅包含熱點(diǎn)采集的時間數(shù)據(jù),更重要的是程序的并發(fā)狀態(tài)。它用5種不同狀態(tài)(Idle、Poor、Ok、Ideal、Over)表示并發(fā)性的情況。在多核平臺下,理想的狀態(tài)應(yīng)該達(dá)到Ok以上,也就是說當(dāng)熱點(diǎn)函數(shù)運(yùn)行時,其他線程同時工作在處理器上,這樣可以提高多核資源的利用率。
3.4 串行程序優(yōu)化
通過分析源代碼,可以對串行程序進(jìn)行如圖2所示的并行優(yōu)化。
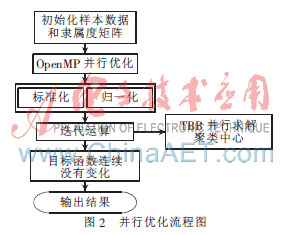
(1)因?yàn)殡`屬度矩陣的歸一化和樣本矩陣的標(biāo)準(zhǔn)化沒有數(shù)據(jù)相關(guān)性,所以可以利用OpenMP的工作分區(qū)功能在兩個線程中同時執(zhí)行運(yùn)算,提高多核的利用率,節(jié)省程序運(yùn)行時間。使用OpenMP的優(yōu)化設(shè)計(jì):
#include <omp.h>
初始化數(shù)據(jù)
#pragma omp parallel sections//工作分區(qū)
{#pragma omp setion
樣本數(shù)據(jù)標(biāo)準(zhǔn)化
#pragma omp section
隸屬度矩陣歸一化}
(2)歸一化后的隸屬度矩陣和標(biāo)準(zhǔn)化的樣本數(shù)據(jù)做矩陣乘法的運(yùn)算,可以使用TBB并行庫進(jìn)行優(yōu)化設(shè)計(jì)[6-7]。TBB::block_range2d表示的是二維迭代空間的模板類,它包含在頭文件TBB/blocked_range.h中,作用是根據(jù)需求對并行任務(wù)正確的劃分。因?yàn)榫仃囅喑耸嵌S空間的運(yùn)算,因此采用block_range2d模板類。迭代空間劃分好后,就可以使用TBB::parallel_for執(zhí)行并行操作。parallel_for包含在頭文件TBB/parallel_for.h中,作用是對循環(huán)體進(jìn)行并行化處理。使用TBB的優(yōu)化設(shè)計(jì):
#include “tbb/taske_scheduler_init.h”
# include ”tbb/parallel_for.h”
#include ”tbb/blocked_range2d.h”
task_scheduler_init init;//初始化對象
{//矩陣相乘的tbb并行化
parallelMul()double c, double a,double b}{parallel _for(blocked_range2d<size_t> (0,k,0,n),MatrixlMul(c,a,b));}
}
4 實(shí)驗(yàn)結(jié)果測試
本文采用UCI標(biāo)準(zhǔn)數(shù)據(jù)集中的Wine數(shù)據(jù)集作為測試實(shí)例,該數(shù)據(jù)集包含有178個樣本,每個樣本有13個屬性特征,分為3類,每類分別為59,71,48,數(shù)據(jù)為178×13的矩陣。設(shè)定加權(quán)指數(shù)m=2,停止閾值ω=le-4。
(1)實(shí)驗(yàn)平臺
硬件:Intel Pentium Dual T3400 @2.16 GHz 2.16 GHz,2 GB內(nèi)存。
軟件:Microsoft Windows XP professional service pack3操作系統(tǒng);Visual.Studio.2008英文專業(yè)版;parallel_studio_ sp1_setup(評估版);tbb22_009oss_win(TBB2.2版本)[8]。
為了檢測并行優(yōu)化的效果,要對測試結(jié)果、熱點(diǎn)、并發(fā)性和串行程序進(jìn)行對比。
(2)實(shí)驗(yàn)結(jié)果
經(jīng)過實(shí)驗(yàn)測試獲得Wine數(shù)據(jù)集3個分類的樣本數(shù),分別為59、64、48,與標(biāo)準(zhǔn)分類相比誤差很小。本文通過5次運(yùn)行FMC得到的實(shí)驗(yàn)結(jié)果相同,說明模糊C均值算法的并行優(yōu)化設(shè)計(jì)是可行的。
(3)熱點(diǎn)對比
從圖3可以看到并行后熱點(diǎn)函數(shù)Update執(zhí)行時間減少為15.321 ms,這是由于Update函數(shù)中有二維矩陣的并行化設(shè)計(jì)。在雙核平臺下,串行程序的線程數(shù)為1,而并行程序的線程數(shù)為3。

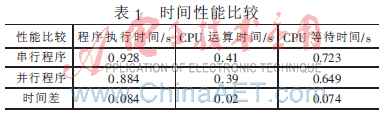
表1是IPA中Compare Results功能的比較結(jié)果,各項(xiàng)時間的差值都為正數(shù),表明性能提高。
(4)并發(fā)性對比
從圖4可以看到并行程序的并發(fā)效果。熱點(diǎn)函數(shù)Update并行后不僅時間減少了,狀態(tài)也由Poor變?yōu)镮deal。說明當(dāng)熱點(diǎn)函數(shù)運(yùn)行時,其他線程同時運(yùn)行在多核處理器上,多核利用率得到提高。

本文將Intel多核高性能工具應(yīng)用到FMC串行程序的并行優(yōu)化設(shè)計(jì)中,提出并行優(yōu)化設(shè)計(jì)方案,把TBB和OpenMP引入到聚類算法的并行化設(shè)計(jì)中。并行聚類算法在處理海量數(shù)據(jù)時將大大節(jié)省時間,并且提高多核資源的利用率。下一步的工作是從并行算法的可擴(kuò)展性進(jìn)行探究,并在眾核處理器上做進(jìn)一步測試,以便更好地提高聚類算法效率。
參考文獻(xiàn)
[1] 齊淼,張化祥.改進(jìn)的模糊c均值聚類算法研究[J].計(jì)算機(jī)工程與應(yīng)用,2009,45(20):133-135.
[2] 英特爾@軟件網(wǎng)絡(luò)[EB/OL].http://software.intel.com/en-us/intel-parallel-studio-home.
[3] REINDERS J. Intel threading building blocks[M]. O’REILLY出版社, 2007.
[4] 周偉明.多核計(jì)算與程序設(shè)計(jì)[M].武漢:華中科技大學(xué)出版社,2009.
[5] Peter Wang.使用Intel parallel Amplifier:一站式解決最佳方案[EB/OL]. http://software.intel.com/zh-cn/blogs2010-2-22.
[6] 曹婷婷.基于多核處理器串行程序并行化改造和性能分析[D].成都:西南交通大學(xué),2009.
[7] 胡斌,袁道華.TBB多核編程及其混合編程模型的研究[J].計(jì)算機(jī)技術(shù)與發(fā)展,2009,19(2):89-101.
[8] Intel公司. Intel threading building blocks reference manual[EB/OL]. 2007. http: //threadingbuildingblocks. org/.