
摘要:介紹了一種以ARM為核心的嵌入式語音識別模塊的設(shè)計與實現(xiàn)。模塊的核心處理單元選用ST公司的基于ARM Cortex-M3內(nèi)核的32位處理器STM32F103C8T6。本模塊以對話管理單元為中心,通過以LD3320芯片為核心的硬件單元實現(xiàn)語音識別功能,采用嵌入式操作系統(tǒng)μC/OS-II來實現(xiàn)統(tǒng)一的任務(wù)調(diào)度和外圍設(shè)備管理。經(jīng)過大量的實驗數(shù)據(jù)驗證,本文設(shè)計的語音識別模塊具有高實時性、高識別率、高穩(wěn)定性的優(yōu)點。
關(guān)鍵詞:ARM;語音識別;對話管理;LD3320;μC/OS-II
引言
服務(wù)機器人以服務(wù)為目的,因此人們需要一種更方便、更自然、更加人性化的方式與機器人交互,而不再滿足于復雜的鍵盤和按鈕操作。基于聽覺的人機交互是該領(lǐng)域的一個重要發(fā)展方向。目前主流的語音識別技術(shù)是基于統(tǒng)計模式。然而,由于統(tǒng)計模型訓練算法復雜,運算量大,一般由工控機、PC機或筆記本來完成,這無疑限制了它的運用。嵌入式語音交互已成為目前研究的熱門課題。
嵌入式語音識別系統(tǒng)和PC機的語音識別系統(tǒng)相比,雖然其運算速度和內(nèi)存容量有一定限制,但它具有體積小、功耗低、可靠性高、投入小、安裝靈活等優(yōu)點,特別適用于智能家居、機器人及消費電子等領(lǐng)域。
1 模塊整體方案及架構(gòu)
語音識別的基本原理如圖1所示。語音識別包括兩個階段:訓練和識別。不管是訓練還是識別,都必須對輸入語音預(yù)處理和特征提取。訓練階段所做的具體工作是通過用戶輸入若干次訓練語音,經(jīng)過預(yù)處理和特征提取后得到特征矢量參數(shù),最后通過特征建模達到建立訓練語
音的參考模型庫的目的。而識別階段所做的主要工作是將輸入語音的特征矢量參數(shù)和參考模型庫中的參考模型進行相似性度量比較,然后把相似性最高的輸入特征矢量作為識別結(jié)果輸出。這樣,最終就達到了語音識別的目的。

現(xiàn)有的語音識別技術(shù)按照識別對象可以分為特定人識別和非特定人識別。特定人識別是指識別對象為專門的人,非特定人識別是指識別對象是針對大多數(shù)用戶,一般需要采集多個人的語音進行錄音和訓練,經(jīng)過學習,達到較高的識別率。
基于現(xiàn)有技術(shù)開發(fā)嵌入式語音交互系統(tǒng),目前主要有兩種方式:一種是直接在嵌入式處理器中調(diào)用語音開發(fā)包;另一種是嵌入式處理器外圍擴展語音芯片。第一種方法程序量大,計算復雜,需要占用大量的處理器資源,開發(fā)周期長;第二種方法相對簡單,只需要關(guān)注語音芯片的接口部分與微處理器相連,結(jié)構(gòu)簡單,搭建方便,微處理器的計算負擔大大降低,增強了可靠性,縮短了開發(fā)周期。
語音識別技術(shù)在國內(nèi)外的發(fā)展十分迅速。目前國內(nèi)在PC應(yīng)用領(lǐng)域,具有代表性的有:科大訊飛的InterReco2.0、中科模式識別的Pattek ASR3.0、捷通華聲的jASRv5.5;在嵌入式應(yīng)用領(lǐng)域,具有代表性的有:凌陽的SPCE061A、ICRoute的LD332X、上海華鎮(zhèn)電子的WS-117。
本文的語音識別方案是以嵌入式微處理器為核心,外圍加非特定人語音識別芯片及相關(guān)電路構(gòu)成。語音識別芯片選用ICRoute公司的LD33 20芯片。
2 硬件電路設(shè)計
如圖2所示,硬件電路主要包括主控核心部分和語音識別部分。語音進入語音識別部分后,將處理過的數(shù)據(jù)并行傳輸?shù)街骺刂破鳎骺刂破鹘?jīng)過處理后,發(fā)送命令數(shù)據(jù)到USART,USART可用于擴展外圍串行設(shè)備,如語音合成模塊等。

2.1 主控制器電路
本文的主控制器選用的是ST公司的STM32F103C8T6芯片。該芯片基于ARM Cottex-M3 32位的RISC內(nèi)核,工作頻率最高可達72 MHz,內(nèi)置高速存儲器(64 KB的閃存和20 KB的SRAM),豐富的增強I/O端口和聯(lián)接到兩條APB總線的外設(shè)。STM32系列提供了全新的32位產(chǎn)品選項,結(jié)合了高性能、實時、低功耗、低電壓等特性,同時保持了高集成度和易于開發(fā)的優(yōu)勢,將32位MCU世界的性能和功效引向一個新的級別。
2.2 語音識別電路
圖3為語音識別部分原理圖,參照了ICRoute發(fā)布的LD3320數(shù)據(jù)手冊進行設(shè)計。LD3320的內(nèi)部集成了快速穩(wěn)定的優(yōu)化算法,不需外接Fla-sh、RAM,不需要用戶事先訓練和錄音而完成非特定人語音識別,識別準確率高。
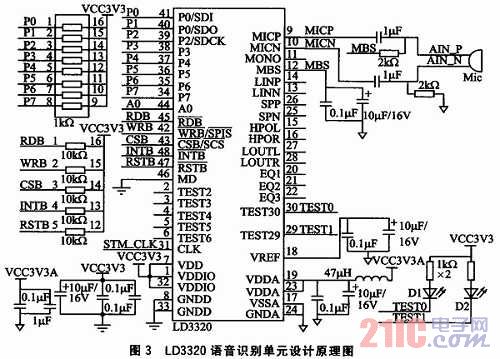
圖中,LD3320采用并行方式直接與STM32F103C8T6相接,均采用1kΩ電阻上拉,A0用于判斷是數(shù)據(jù)段還是地址段;控制信號![]() ,復位信號
,復位信號![]() 以及中斷返回信號INTB與STM32F103C8T6直接相連,采用10kΩ電阻上拉,輔助系統(tǒng)穩(wěn)定工作;和STM32F103C8T6采用同一個外部8 MHz時鐘;發(fā)光二極管D1、D2用于復位后的上電指示;MBS(引腳12)作為麥克風偏置,接了一個RC電路,保證能輸出一個浮動電壓給麥克風。
以及中斷返回信號INTB與STM32F103C8T6直接相連,采用10kΩ電阻上拉,輔助系統(tǒng)穩(wěn)定工作;和STM32F103C8T6采用同一個外部8 MHz時鐘;發(fā)光二極管D1、D2用于復位后的上電指示;MBS(引腳12)作為麥克風偏置,接了一個RC電路,保證能輸出一個浮動電壓給麥克風。
3 軟件系統(tǒng)設(shè)計
軟件系統(tǒng)的設(shè)計主要包括3部分:主控單元的嵌入式操作系統(tǒng)μC/OS-II移植、LD3320的語音識別程序設(shè)計、對話管理單元的設(shè)計。
3.1 嵌入式操作系統(tǒng)μC/OS-II移植
μC/OS-II是一個源碼公開、可移植、可固化、可裁剪、占先式的實時多任務(wù)操作系統(tǒng)。它是專門為計算機的嵌入式應(yīng)用設(shè)計的,絕大部分代碼采用C語言編寫,具有執(zhí)行效率高、占用空間小、實時性能優(yōu)良和可擴展性強等特點,最小內(nèi)核可至2 KB。在μC/OS-II中,任務(wù)的概念尤為重要,它是可剝奪型的內(nèi)核,因此任務(wù)優(yōu)先級的劃分至關(guān)緊要。基于分層化和模塊化的設(shè)計理念,整個系統(tǒng)任務(wù)的劃分如表1所列。
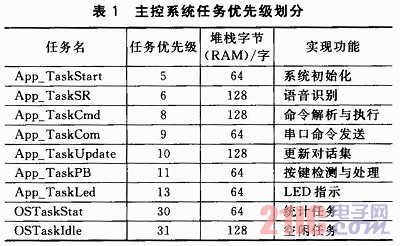
表1中除OSTaskStat和OSTaskIdle任務(wù)為系統(tǒng)自帶,其他7個任務(wù)均為用戶創(chuàng)建。App_TaskStart是系統(tǒng)的第一個任務(wù),對系統(tǒng)時鐘和底層設(shè)備進行初始化,創(chuàng)建所有事件和其他各項用戶任務(wù),并對系統(tǒng)狀態(tài)進行監(jiān)測;App_TaskSR完成語音識別;App_TaskCmd完成對話集中命令的解析和執(zhí)行,并通過USART1向外發(fā)送;App_TaskCom作為外圍擴展任務(wù),通過USART2向外發(fā)送指令或數(shù)據(jù),負責控制外圍擴展設(shè)備,如語音合成設(shè)備等;
App_TaskUpdate通過解析USART1接收的命令和數(shù)據(jù)進行對話集的更新;App_TaskPB是按鍵掃描任務(wù),負責檢測3個獨立按鍵,分為短按和長按檢測;App_TaskLed驅(qū)動4個LED指示燈,指示當前工作狀態(tài)。
3.2 語音識別程序設(shè)計
語音識別程序的設(shè)計,參考了LD332X開發(fā)手冊,本文中采用中斷方式工作,其工作流程分為通用初始化一語音識別用初始化-寫入識別列表-開始識別-響應(yīng)中斷。
①通用初始化和語音識別用初始化。在初始化程序里,主要完成軟復位、模式設(shè)定、時鐘頻率設(shè)定、FIFO設(shè)定。
②寫入識別列表。列表的規(guī)則是,每個識別條目對應(yīng)一個特定的編號(1個字節(jié)),編號可以相同,可以不連續(xù),但是數(shù)值要小于256(00H~FFH)。本芯片最多支持50個識別條目,每個識別條目是標準普通話的漢語拼音(小寫),每2個字(漢語拼音)之間用一個空格間隔。本文中采取了連續(xù)不同編號的識別條目,表2是簡單的示例。

③開始識別。設(shè)置幾個相關(guān)的寄存器,即可開始語音的識別。圖4是相關(guān)的流程。ADC通道即為麥克風輸入通道,ADC增益也就是麥克風音量,可設(shè)定值00H~7FH,建議設(shè)置值為40H~6FH,值越大代表MIC音量越大,識別啟動越敏感,但可能帶來更多誤識別;值越小代表MIC音量越小,需要近距離說話才能啟動識別功能,好處是對遠處的干擾語音沒有反應(yīng)。本文中設(shè)定值為43H。

④響應(yīng)中斷。如果麥克風采集到聲音,不管是否識別出正常結(jié)果,都會產(chǎn)生一個中斷信號。而中斷程序要根據(jù)寄存器的值分析結(jié)果。讀取BA寄存器的值,可以知道有幾個候選答案,而C5寄存器里的答案是得分最高、最可能正確的答案。
3.3 對話管理單元設(shè)計
為了方便進行對話的管理,本文中設(shè)計了一個對話管理單元,用于對等待識別的語句和等待執(zhí)行的命令進行存儲,在主控制器中通過定義二維數(shù)組來實現(xiàn)。LD3320每次識別最多可以設(shè)置50項候選識別句,每個識別句可以是單字、詞組或短句,長度為不超過10個漢字或者79個字節(jié)的拼音串。基于上述原因,本文設(shè)計的對話管理數(shù)組如表3所列。

行為數(shù)組中存儲要執(zhí)行的行為編號,對應(yīng)于50條語音識別語句,共有50組指令,每組指令中可以最多包含6個行為,并行的行為可以歸為一步,通過多個行為的組合,就可以完成更復雜的任務(wù)。
4 性能測試與應(yīng)用
為了保證設(shè)計的語音識別模塊的語音識別率、穩(wěn)定性和響應(yīng)時間,本文對所描述的語音識別模塊做了相應(yīng)的測試,測試環(huán)境分別為安靜的家庭環(huán)境和嘈雜的醫(yī)院環(huán)境,共8條語音指令,對每條語音指令分別進行10次測試,每個環(huán)境下對每個特定人的總實驗次數(shù)為80次,記錄成功識別的次數(shù)。測試結(jié)果如表4所列。
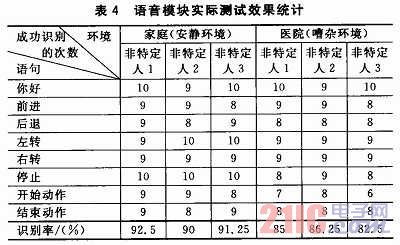
測試中的3個非特定人中,非特定人1為女性,非特定人2和非特定人3為男性。由表中數(shù)據(jù)可以看出,家庭環(huán)境下對非特定人的語音識別率可達到90%以上,嘈雜的醫(yī)院環(huán)境下的語音識別率也可達82.5%以上。識別率方面,在嘈雜環(huán)境下比在安靜環(huán)境下的語音識別率有所降低;穩(wěn)定性方面,在安靜環(huán)境下系統(tǒng)的穩(wěn)定性較好,語音說1遍,最多說2遍模塊就可以做出正確的響應(yīng);在噪聲環(huán)境下,系統(tǒng)的穩(wěn)定性有所下降,個別語音命令需要說3遍甚至3遍以上才能被模塊準確識別;實時性方面,在安靜環(huán)境下的語音能保證系統(tǒng)響應(yīng)的實時性,響應(yīng)時間一般不超過1 s,在噪聲環(huán)境下的響應(yīng)時間相對長一些。
結(jié)語
本文討論了基于STM32的嵌入式語音識別模塊的設(shè)計和實現(xiàn),對模塊各個組成單元的硬件電路及軟件實現(xiàn)進行了詳細的介紹。大量實驗及實際應(yīng)用表明,本文設(shè)計的語音識別模塊具有穩(wěn)定性好、語音識別率高、抗噪聲干擾能力強、結(jié)構(gòu)簡單和使用方便等特點。該模塊實用性
強,可廣泛應(yīng)用于服務(wù)機器人智能空間、智能家居和消費電子產(chǎn)品等多個領(lǐng)域。