
GPU并行化處理
可編程圖形處理器(Programmable Graphic Process Unit, PGPU)是目前計算機上普遍采用的圖形圖像處理專用器件,具有單指令流多數(shù)據(jù)流(SIMD)的并行處理特性,而且提供了完全支持向量操作指令和符合IEEE32位浮點格式的頂點處理能力和像素處理能力,已經成為了一個強大的并行計算單元。研究人員將其應用于加速科學計算和可視化應用程序,取得了令人鼓舞的研究成果。
與CPU相比,GPU具有以下優(yōu)勢:強大的并行處理能力和高效率的數(shù)據(jù)傳輸能力[1] [2] [7]。其中,并行性主要體現(xiàn)了指令級、數(shù)據(jù)級和任務級三個層次。高效率的數(shù)據(jù)傳輸主要體現(xiàn)在兩個方面: GPU與顯存之間的帶寬為:16GB/s;系統(tǒng)內存到顯存的帶寬為:4GB/s。
總上所述,GPU比較適合處理具有下面特性的應用程序:1、大數(shù)據(jù)量;2、高并行性;3、低數(shù)據(jù)耦合;4、高計算密度;5、與CPU交互比較少。
數(shù)字圖像處理的并行化分析
數(shù)字圖像處理算法多種多樣,但從數(shù)據(jù)處理的層面來考慮,可以分為:像素級處理、特征級處理和目標級處理三個層次[3][4]。
(1)像素級圖像處理
像素級處理,即由一幅像素圖像產生另一幅像素圖像,處理數(shù)據(jù)大部分是幾何的、規(guī)則的和局部的。根據(jù)處理過程中的數(shù)據(jù)相關性,像素級處理又可進一步分為點運算、局部運算和全局運算。
(2)特征級圖像處理
特征級處理是在像素圖像產生的一系列特征上進行的操作。常用的特征包括:形狀特征、紋理特征、梯度特征和三維特征等,一般采用統(tǒng)一的測度,如:均值、方差等,來進行描述和處理,具有在特征域內進行并行處理的可能性。但是,由于其特征具有象征意義和非局部特性,在局部區(qū)域并行的基礎上,需要對總體進行處理。利用GPU實現(xiàn)并行化處理的難度比較大。
(3)目標級圖像處理
目標級處理是對由一系列特征產生的目標進行操作。由于目標信息具有象征意義和復雜性,通常是利用相關知識進行推理,得到對圖像的描述、理解、解釋以及識別。由于其數(shù)據(jù)之間相關性強,且算法涉及到較多的知識和人工干預,并行處理的難度也比較大。
由此可見,整個圖像處理的結構可以利用一個金字塔模型來表示。在底層,雖然處理的數(shù)據(jù)量巨大,但由于局部數(shù)據(jù)之間的相關性小,且較少的涉及知識推理和人工干預,因此大多數(shù)算法的并行化程度比較高。當沿著這個金字塔結構向高層移動時,隨著抽象程度的提高,大量原始數(shù)據(jù)減少,所需的知識和算法的復雜性逐層提高,并行化處理的難度也逐漸加大。
由于絕大部分的圖像處理算法是在像素級進行的,且GPU的SIMD并行流式處理在進行像素級的圖像處理時具有明顯的優(yōu)勢,而特征級和目標級處理無論是從數(shù)據(jù)的表達還是從算法自身的實現(xiàn)來說,都很難實現(xiàn)GPU并行化。因此,本文重點研究各種像素級圖像處理操作的GPU并行化實現(xiàn)方法。
數(shù)字圖像GPU并行化處理的基本流程與關鍵技術
現(xiàn)代GPU提供了頂點處理器和片段處理器兩個可編程并行處理部件。在利用GPU執(zhí)行圖像處理等通用計算任務時,要做的主要工作是把待求解的任務映射到GPU支持的圖形繪制流水線上。通常的方法是把計算任務的輸入數(shù)據(jù)用頂點的位置、顏色、法向量等屬性或者紋理等圖形繪制要素來表達,而相應的處理算法則被分解為一系列的執(zhí)行步驟,并改寫為GPU的頂點處理程序或片段處理程序,然后,調用3D API執(zhí)行圖形繪制操作,調用片段程序進行處理;最后,保存在幀緩存中的繪制結果就是算法的輸出數(shù)據(jù),如圖1所示[5][6]。
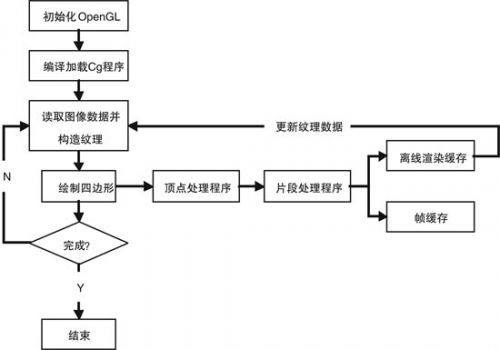
圖1 遙感影像GPU并行化處理基本流程
雖然數(shù)字圖像處理算法多種多樣,具體實現(xiàn)過程也很不相同,但是在利用GPU進行并行化處理時,有一些共性的關鍵技術問題需要解決,如:數(shù)據(jù)的加載,計算結果的反饋、保存等。下面對這些共性的問題進行分析,并提出相應的解決思路。
數(shù)據(jù)加載
在GPU的流式編程模型中,所有的數(shù)據(jù)都必須以“流”的形式進行加載處理,并通過抽象的3D API進行訪問。在利用GPU進行圖像處理時,最直接有效的數(shù)據(jù)加載方法是把待處理的圖像打包為紋理,在繪制四邊形時進行加載、處理。同時為了保證GPU上片段程序能夠逐像素的對紋理圖像進行處理,必須將投影變換設置為正交投影,視點變換的視區(qū)與紋理大小相同,使得光柵化后的每個片段(fragment)和每個紋理單元(texel)一一對應。
對于圖像處理算法中的其他參數(shù),如果數(shù)據(jù)量很小,則可以直接通過接口函數(shù)進行設置;如果參數(shù)比較多,也應該將其打包為紋理的形式傳輸給GPU。在打包的過程中應充分利用紋理圖像所具有的R、G、B、A四個通道。
計算結果的反饋、保存
應用程序是通過調用3D API繪制帶紋理的四邊形,激活GPU上的片段程序進行圖像處理的,而GPU片段著色器的直接渲染輸出是一個幀緩沖區(qū),它對應著計算機屏幕上的一個窗口,傳統(tǒng)上用來容納要顯示到屏幕的像素,但是在GPU流式計算中可以用來保存計算結果。雖然CPU可以通過3D API直接讀寫這個幀緩沖區(qū),將渲染處理的結果從幀緩存中復制到系統(tǒng)內存進行保存,但是幀緩存的大小受窗口大小限制,而且由于AGP總線的帶寬限制(2.1GB/s),從顯存到系統(tǒng)內存的數(shù)據(jù)回讀操作效率低下。對于大幅影像的處理應用是顯然不適合的,特別是在中間計算結果的保存反饋時,采用幀緩存方式將成為制約GPU性能發(fā)揮的最主要瓶頸。
針對以上問題,筆者利用離線渲染緩存Pbuffer作為輸出緩存。Pbuffer是OpenGL1.3版本的WGL_ARB_pbuffer擴展提供的輸出緩存,它通過在顯存中開辟一個不可見的數(shù)據(jù)緩沖區(qū),取代幀緩存來保存片段處理器的輸出結果。如果這個結果只是中間計算數(shù)據(jù),還可以采用渲染到紋理的技術,把Pbuffer中的數(shù)據(jù)綁定到一個紋理,供下一遍繪制的片段程序取用,減少數(shù)據(jù)在顯存和系統(tǒng)內存之間的傳輸,實現(xiàn)整個數(shù)據(jù)流在GPU芯片內部的流轉,顯著提高數(shù)據(jù)的反饋速度。特別是在需要GPU反復執(zhí)行的情況下,可以構造兩個Pbuffer,交替的作為輸入或輸出紋理使用,產生所謂的“Ping-Pong”方法,有效避免中間計算結果的回讀操作。
圖像卷積運算的GPU并行化試驗
卷積運算是一種常見的數(shù)字圖像處理局部運算,通過選擇不同的卷積核,可以實現(xiàn)不同的圖像處理效果。圖像卷積運算定義為:
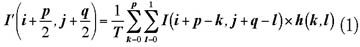
式中,為卷積運算以后的圖像;為待處理的圖像;為卷積核;T為常數(shù),當卷積核中所有系數(shù)之和不為零時,T等于所有系數(shù)之和,否則等于1。
試驗平臺與數(shù)據(jù)
硬件平臺為: Intel Core 2 2.0GHz CPU,1GB系統(tǒng)內存,NVIDIA公司的GeForce G0 7400 GPU, 512MB顯存。
軟件平臺:Windows XP操作系統(tǒng),CPU程序開發(fā)環(huán)境為Microsoft Visual C++2005,三維繪制接口為OpenGL及其擴展庫WGL_ARB_pbuffer,GPU程序開發(fā)語言為Cg。
所采用的試驗數(shù)據(jù)有兩組,如圖2所示:
第一組為:截取的新加坡部分地區(qū)QucikBird衛(wèi)星影像,大小為(像素);
第二組為:截取的黃河小浪底部分地區(qū)Spot4衛(wèi)星影像,大小為(像素)。

(a)試驗數(shù)據(jù)一

(b)試驗數(shù)據(jù)二
圖2 卷積運算試驗數(shù)據(jù)
試驗步驟與數(shù)據(jù)記錄
為了進行多組數(shù)據(jù)的對比試驗,首先對原始圖像數(shù)據(jù)進行預處理,通過裁減獲得大小分別為2048×2048、1024×1024、521×512、256×256、128×128的試驗數(shù)據(jù)。
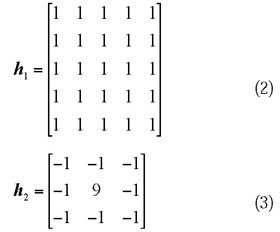
以經過預處理的10幅不同大小的圖像進行卷積運算對比試驗,分別運行卷積平滑和卷積銳化的CPU和GPU程序,并記錄處理時間。試驗所用的平滑卷積核h1為式(2),銳化卷積核h2為式(3):
試驗結果與分析
圖3所示為圖像數(shù)據(jù)二512×512的平滑和銳化試驗的處理結果,圖4為GPU加速效率對比圖。

(a)卷積平滑后圖像

(b)卷積銳化后圖像
圖3 數(shù)據(jù)二的圖像平滑、銳化效果對比
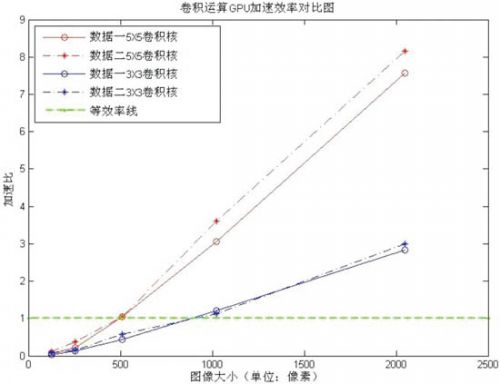
圖4 卷積運算GPU加速效率對比圖
從圖4可以看出:隨著圖像的增大,特別是卷積核的變大,GPU的加速效果更加明顯,例如:對2048×2048大小的圖像進行5×5的卷積運算,最高加速比達到了8倍多。但是,在圖像數(shù)據(jù)較小時,由于OpenGL的初始化和紋理數(shù)據(jù)的加載耗費了大量的時間,使得GPU并行處理的優(yōu)勢消失,甚至還沒有CPU處理的速度快。
結語
本文對GPU的并行性和數(shù)字圖像處理算法的并行層次進行了簡要的介紹,提出了像素級圖像處理的GPU并行化實現(xiàn)方法,并對其基本流程和關鍵技術:數(shù)據(jù)的加載,計算結果的反饋與保存等問題進行了詳細論述,最后通過圖像的平滑和銳化的卷積運算證明了GPU在數(shù)字圖像并行化處理方面的強大優(yōu)勢。