
文獻(xiàn)標(biāo)識(shí)碼: A
文章編號(hào): 0258-7998(2011)05-0031-04
數(shù)字廣播調(diào)幅系統(tǒng)DRM(Digital Radio Mondiale)采用先進(jìn)音頻編碼AAC(Advanced Audio Coding)作為其主要的信源編碼方式[1],在與模擬調(diào)幅廣播同樣的帶寬(9 kHz或10 kHz)下實(shí)現(xiàn)了調(diào)頻的音質(zhì)。DRM不僅解決了模擬調(diào)幅廣播抗干擾能力差等缺點(diǎn),而且在音頻業(yè)務(wù)的基礎(chǔ)上又增加了文本、圖像、數(shù)據(jù)等附加業(yè)務(wù),豐富了調(diào)幅廣播的內(nèi)容,大大提高了調(diào)幅廣播的市場競爭力,成為調(diào)幅廣播發(fā)展的必然趨勢。
信源編碼是DRM系統(tǒng)的關(guān)鍵技術(shù),其壓縮節(jié)目音頻源信號(hào),只需較少的傳輸帶寬就可保證接收端的重建音頻信號(hào)有較好的音質(zhì)。DRM音頻解碼器的實(shí)現(xiàn)和優(yōu)化決定了系統(tǒng)能否正確實(shí)現(xiàn)音頻解碼,并完成音頻的實(shí)時(shí)播放,使用戶得到良好音質(zhì)。本文中AAC音頻解碼程序在DSP硬件平臺(tái)上運(yùn)行,由于硬件平臺(tái)性能有限,要求音解碼器不僅要能確保音頻質(zhì)量,還要不能占用DSP系統(tǒng)太多的資源。因此研究DRM音頻解碼器在高性能DSP平臺(tái)上的實(shí)現(xiàn)及其優(yōu)化具有非常重要的現(xiàn)實(shí)意義。
1 DRM音頻解碼流程
通用MPEG-4 AAC音頻編解碼器的原理和實(shí)現(xiàn)技術(shù)已經(jīng)很成熟,不再詳述。DRM系統(tǒng)的信源編碼方案中所采用的頻帶恢復(fù)技術(shù)(SBR)提供了類似于MPEG-4 AAC中感知噪聲整形(PNS)模塊的功能,故DRM系統(tǒng)采用的音頻編碼方案不包括PNS模塊,同時(shí)也去除了長期預(yù)測(LTP)、采樣率可分級(jí)(SSR)等復(fù)雜的模塊,降低了算法復(fù)雜度,對處理器的處理能力要求也相對較低,適合應(yīng)用于嵌入式開發(fā)平臺(tái)上。AAC的采樣率有12 kHz和24 kHz兩種,5個(gè)(12 kHz采樣頻率)或10個(gè)(24 kHz采樣頻率)音頻幀組成一個(gè)持續(xù)時(shí)間固定為400 ms的音頻超級(jí)幀。本文優(yōu)化之前首先在PC機(jī)的VC++6.0環(huán)境下實(shí)現(xiàn)了DRM廣播信號(hào)的正確解碼和實(shí)時(shí)播放,測試信號(hào)為單聲道、48 kHz采樣,采用AAC音頻編碼的wav格式的DRM廣播信號(hào)源,其中AAC的采樣率為24 kHz,即一個(gè)音頻超幀包含10個(gè)子幀。在VC++6.0環(huán)境下運(yùn)行整個(gè)工程,經(jīng)同步、解調(diào)和信道解碼后獲得DRM信號(hào)源中的AAC音頻編碼數(shù)據(jù),在每次AAC子幀解碼前將每子幀數(shù)據(jù)輸出到一個(gè)文件。在DSP上測試音頻解碼程序時(shí),可以直接提取AAC數(shù)據(jù)進(jìn)行解碼,解碼流程如圖 1所示。解碼過程如下:
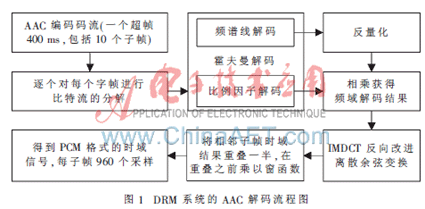
(1)對傳來的AAC子幀數(shù)據(jù)進(jìn)行比特流分解,根據(jù)DRM系統(tǒng)中音頻子幀結(jié)構(gòu)獲取語法單元、霍夫曼碼字等各部分的數(shù)據(jù)。
(2)進(jìn)行霍夫曼解碼,這部分用到了一系列的霍夫曼碼書進(jìn)行查詢解碼。頻域數(shù)據(jù)和比例因子的獲得都在這一步。該過程需要在將順序打亂的碼字重新組合在一起的同時(shí),進(jìn)行霍夫曼解碼,并將解碼之后的數(shù)據(jù)放置到正確的位置上,準(zhǔn)備進(jìn)行下一步的反量化。
(3)對解碼后的頻域數(shù)據(jù)進(jìn)行反量化。
(4)將反量化的結(jié)果乘以(2)中生成的比例因子。
(5)濾波器組部分。這部分在解碼時(shí)采用了逆改進(jìn)離散余弦變換(IMDCT)[2],還包括一個(gè)加窗的過程和疊加的過程。功能模塊的輸出為信號(hào)的時(shí)域值。
2 TMS320C6416的DSP開發(fā)平臺(tái)
TMS320C6416(簡稱C6416)[3]是一種高性能的32 bit定點(diǎn)DSP芯片。本文使用的C6416的工作頻率達(dá)到600 MHz。其特點(diǎn)包括:具有8個(gè)功能單元的高級(jí)超長指令體系結(jié)構(gòu)的CPU;所有指令有條件執(zhí)行;支持8/16/32 bit可變長度數(shù)據(jù)訪問;支持常用算術(shù)運(yùn)算的飽和與歸一化操作;兩級(jí)高速緩存(Cache)存儲(chǔ)器結(jié)構(gòu)及豐富的片內(nèi)外設(shè),如增強(qiáng)型直接存儲(chǔ)器訪問EDMA控制器、多通道緩沖串口McBSP等。C6416開發(fā)板上除C6416 DSP芯片外,還帶有外擴(kuò)的512 K×8 bit的FLASH。
開發(fā)環(huán)境采用DSP集成開發(fā)環(huán)境CCS(Code Composer Studio),它集成了代碼編輯、編譯、工程管理、代碼生成與調(diào)試、代碼性能剖析、數(shù)據(jù)查看、繪制數(shù)據(jù)圖像、DSP/BIOS參數(shù)設(shè)置,以及提供各種優(yōu)化建議等工具模塊。
3 音頻解碼程序的優(yōu)化
本文優(yōu)化之前先在PC機(jī)VC++6.0環(huán)境下實(shí)現(xiàn)了DRM廣播信號(hào)的正確解碼和實(shí)時(shí)播放,但移植到DSP平臺(tái)之后不能實(shí)時(shí)播放。本文單獨(dú)將音頻解碼部分的程序移植到DSP開發(fā)平臺(tái)CCS3.1開發(fā)環(huán)境中,測試數(shù)據(jù)為前文中存儲(chǔ)的AAC解碼前每子幀的數(shù)據(jù)。優(yōu)化前,不帶有SBR解碼的情況下,音頻解碼程序中一個(gè)音頻超幀里每個(gè)子幀解碼所花費(fèi)的周期數(shù),即運(yùn)行效率如下:
子幀1:1 901 300 子幀2:3 667 994
子幀3:3 469 783 子幀4:3 397 752
子幀5:1 745 753 子幀6:3 416 357
子幀7:3 439 464 子幀8:3 331 484
子幀9:1 721 339 子幀10:1 764 605
(共計(jì)27 855 831周期)
在DSP上單獨(dú)測試音頻解碼的效率,計(jì)算所花費(fèi)的時(shí)鐘周期數(shù)的語句如下:
st=clock( ); aac_frame_decode(, , , ); end=clock(); printf("clock cost %d\n",end - st);
其中aac_frame_decode( )是信道解碼與音頻解碼的接口函數(shù),該函數(shù)調(diào)用AAC解碼程序,在此,其參數(shù)與返回值已省略。在CCS環(huán)境下,運(yùn)行程序前點(diǎn)擊Profile剖析菜單下Clock選項(xiàng)中的Enable,就打開了CCS的程序運(yùn)行周期計(jì)數(shù)功能。兩次clock函數(shù)調(diào)用返回值之差就是解碼函數(shù)花費(fèi)的周期數(shù)。表1是利用CCS3.1中Profile工具分別計(jì)算的程序優(yōu)化前后一個(gè)超幀解碼過程中每個(gè)函數(shù)所花費(fèi)的周期數(shù)。
優(yōu)化的本質(zhì)是提高程序的運(yùn)行效率,同時(shí)保持程序原有功能準(zhǔn)確無誤。本文針對本課題中的具體問題,提出以下對應(yīng)的優(yōu)化措施:
(1)去除原程序中用不到的函數(shù)。最初的音頻解碼程序是針對所有MPEG-4 AAC標(biāo)準(zhǔn)使用的,其中包含了很多功能模塊,如MP4解碼、PNS解碼、LTP解碼等。這些功能在DRM系統(tǒng)的音頻編碼標(biāo)準(zhǔn)AAC中是用不到的,所以應(yīng)當(dāng)將它們?nèi)コ駝t其生成的代碼不僅無用,而且會(huì)占用大量存儲(chǔ)空間。在CCS3.1中點(diǎn)擊Profile菜單下的Analysis Toolkit選項(xiàng)中的Code coverage and Exclusive Profiler,按照提示運(yùn)行程序,可以得到一個(gè)Excel文件。該文件將代碼覆蓋程度、每個(gè)函數(shù)調(diào)用次數(shù)以及執(zhí)行函數(shù)CPU所花費(fèi)的周期數(shù)等展示出來,從而可以方便地找到每個(gè)文件中一直沒有運(yùn)行的函數(shù),去除這些函數(shù)可節(jié)省大量存儲(chǔ)空間且保證程序功能無誤。
(2)循環(huán)體優(yōu)化。原始的音頻解碼程序已經(jīng)采用了一些常用的算法級(jí)別的優(yōu)化,如IMDCT的快速算法[4]、霍夫曼解碼的查表快速算法等,但仍沒有達(dá)到最理想的速度。主要原因是for循環(huán)和定點(diǎn)化的問題。在AAC解碼器中,循環(huán)體幾乎占用了60%的資源,因此它的優(yōu)化非常重要。要想充分發(fā)揮C6416 DSP處理器的8個(gè)功能單元并行執(zhí)行指令的功能,需要讓編譯器盡可能多地生成由2條以上指令組成的超長指令。C/C++編譯器可以對代碼進(jìn)行不同級(jí)別的優(yōu)化。高級(jí)優(yōu)化由專門的優(yōu)化器完成,與目標(biāo)DSP有關(guān)的低級(jí)優(yōu)化由代碼生成器完成。圖2是編譯器、優(yōu)化器和代碼生成器的執(zhí)行圖。

最簡單的執(zhí)行優(yōu)化的方法是用cl6x編譯程序[5],在命令行設(shè)置-On選項(xiàng)即可。n是優(yōu)化的級(jí)別(n為0、1、2或3),它控制優(yōu)化的類型和程度。-O3級(jí)別下,編譯器可對循環(huán)代碼實(shí)現(xiàn)軟件流水[6],優(yōu)化器將會(huì)充分利用處理器的8個(gè)功能單元,盡可能多地生成并行指令,使最后的可執(zhí)行代碼運(yùn)行速度達(dá)到最高,以達(dá)到優(yōu)化代碼的目的。
軟件流水是用來安排循環(huán)指令并使這個(gè)循環(huán)多次迭代并行執(zhí)行的一種技術(shù)。簡單循環(huán)情況下,軟件流水能夠正常的發(fā)揮作用,但在多層嵌套循環(huán)情況下,軟件流水往往會(huì)失敗。簡化循環(huán)是充分發(fā)揮軟件流水的通用而有效的辦法。如本文中一個(gè)函數(shù)reordered_spectral_data( )中存在多達(dá)5層嵌套的for循環(huán),有的循環(huán)中還有條件分支函數(shù),在-O3優(yōu)化情況下,解一個(gè)超幀10次調(diào)用這個(gè)函數(shù)之后,共花費(fèi)7 613 426個(gè)周期,與其他函數(shù)開銷相比如圖3(a)所示。這是因?yàn)閮?yōu)化器只能對最內(nèi)層的循環(huán)進(jìn)行軟件流水操作,而外層的循環(huán)只能按照原語句執(zhí)行,于是大量語句只能以最慢的方式執(zhí)行。
經(jīng)過對這個(gè)函數(shù)中的循環(huán)語句進(jìn)行分析和調(diào)試,同時(shí)參照AAC標(biāo)準(zhǔn),在保證功能正確實(shí)現(xiàn)的基礎(chǔ)上對該函數(shù)做如下改進(jìn):這個(gè)函數(shù)的功能是將打亂順序的霍夫曼碼字重新排序,并進(jìn)行霍夫曼解碼。在碼字重新排序的過程中有碼書查找的步驟,編碼時(shí)碼書的選擇是有優(yōu)先級(jí)別的,解碼時(shí)需要從最高級(jí)到最低級(jí)依次判斷是否存在以這個(gè)碼書編碼的碼字,如果有就進(jìn)行解碼,沒有就判斷下一個(gè)碼書,每判斷一個(gè)碼書就是一次大循環(huán)。事實(shí)上,碼書級(jí)別都很低,先前大部分循環(huán)中判斷的碼書都是錯(cuò)誤的,所以可以另外用一個(gè)小的循環(huán)檢查出級(jí)別最高的碼書,這樣就會(huì)在真正解碼的嵌套循環(huán)中省去許多無用的循環(huán)。另外在嵌套的for循環(huán)中,有一層是針對窗組進(jìn)行的循環(huán),即有幾個(gè)窗組需要解碼,就循環(huán)幾次。事實(shí)上,窗組往往只有一個(gè),多窗組的情況極為少見,所以這層for循環(huán)在大部分情況下可以去除。但多窗組的情況畢竟存在,可以事先用一個(gè)if條件判斷窗組個(gè)數(shù),再根據(jù)結(jié)果條件執(zhí)行相應(yīng)的程序。這就使程序在大多數(shù)情況下能夠節(jié)省大量的運(yùn)行時(shí)間,因?yàn)樗鼤?huì)執(zhí)行軟件流水生成的代碼,而在極少情況下會(huì)執(zhí)行效率最慢的未經(jīng)優(yōu)化的代碼。
按照上述的分析進(jìn)行優(yōu)化之后,結(jié)果如圖3(b)所示。reordered_spectral_data()函數(shù)優(yōu)化之后的開銷為:10次調(diào)用這個(gè)函數(shù)共花費(fèi)1 029 512周期,與優(yōu)化前的7 613 426周期相比,運(yùn)行速度提高了7倍多。

(3)消除存儲(chǔ)器相關(guān)性。如果C6416編譯器可以確定兩條指令是不相關(guān)的,則安排它們并行執(zhí)行,否則安排指令串行執(zhí)行。有幾個(gè)方法可以幫助編譯器確定哪些指令不相關(guān):使用restrict關(guān)鍵字聲明指針;一起使用-pm選項(xiàng)和-O3選項(xiàng)確定程序優(yōu)先級(jí),在程序優(yōu)先級(jí)中,所有源文件都被編譯成一個(gè)模塊,從而使編譯器更有效地消除相關(guān)性;使用-mt選項(xiàng)向編譯器說明代碼不存在存儲(chǔ)器相關(guān)性,即允許編譯器在無存儲(chǔ)器相關(guān)性的假設(shè)下進(jìn)行優(yōu)化。
(4)使用內(nèi)聯(lián)函數(shù)。C6416編譯器提供的內(nèi)聯(lián)函數(shù)是直接映射為內(nèi)聯(lián)指令的特殊函數(shù),內(nèi)聯(lián)函數(shù)的代碼高效、長度短。可以使用內(nèi)聯(lián)函數(shù)并行優(yōu)化C代碼。
(5)在循環(huán)前加上#pragma MUST_ITERATE(, ,),向編譯器傳遞循環(huán)次數(shù)信息,編譯器會(huì)生成更好的循環(huán)代碼,或消除因不知道循環(huán)次數(shù)而產(chǎn)生的冗余循環(huán)以便減小整個(gè)代碼量。
4 DRM音頻解碼器的測試結(jié)果
通過實(shí)施上述各種優(yōu)化方法,從算法程序上的等效替代到充分利用編譯的優(yōu)化功能,音頻解碼程序運(yùn)行效率有了明顯的提高。下面是同一個(gè)超幀解碼中每個(gè)子幀花費(fèi)的周期數(shù),總計(jì)數(shù)周期為2 641 488,與優(yōu)化前程序花費(fèi)的27 855 831個(gè)周期相比,運(yùn)行時(shí)間不到原來的1/10。
子幀1:396 470 子幀2:250 626
子幀3:247 983 子幀4:226 120
子幀5:254 623 子幀6:224 668
子幀7:231 056 子幀8:254 901
子幀9:277 520 子幀10:279 424
(共計(jì)2 641 488周期)
從表1可以看出,優(yōu)化后一些函數(shù)的訪問次數(shù)為0,這是由于優(yōu)化采用了內(nèi)聯(lián)函數(shù)的功能,它們的代碼被內(nèi)聯(lián)在一些較大的函數(shù)中,如faad_getbits( )函數(shù);另一種情況:如對于pns_decode( )函數(shù),由于DRM系統(tǒng)的音頻編碼標(biāo)準(zhǔn)中的SBR技術(shù)提供了相當(dāng)于PNS的功能,所以AAC中的PNS模塊沒有使用,優(yōu)化中被刪除。對比表1中優(yōu)化前后數(shù)據(jù)可知,很多函數(shù)花費(fèi)的周期大大減少,如decode_scale_factors函數(shù)等。

本文給出了DRM音頻解碼器在TMS320C6416上的實(shí)現(xiàn)方案,并結(jié)合TMS320C6416的特性,從去除無用函數(shù)、內(nèi)聯(lián)函數(shù)替換、循環(huán)體優(yōu)化等多方面對音頻解碼程序進(jìn)行了優(yōu)化。在充分利用EDMA硬件資源的音頻驅(qū)動(dòng)程序的配合下,優(yōu)化后的音頻解碼程序能夠完成音樂的實(shí)時(shí)播放。DRM中一個(gè)AAC超幀的時(shí)間為400 ms,優(yōu)化后解碼一個(gè)音頻超幀耗費(fèi)的周期數(shù)從2 800萬降至300萬,即每秒音頻解碼需750萬周期,遠(yuǎn)小于C6416每秒所能執(zhí)行的周期數(shù)(600 M),不但能保證音頻解碼和播放的實(shí)時(shí)性,還為DRM廣播信號(hào)解碼系統(tǒng)執(zhí)行音頻解碼之前的解調(diào)和信道解碼程序節(jié)省了很大的周期資源和處理空間。
參考文獻(xiàn)
[1] ETSI ES 201 980 V3.1.1[S].Digital Radio Mondiale(DRM):System Specification,2009.
[2] CHO Yang Ki,SONG Tae Hoon,Kim Hi Seok.An optimized algorithm for computing the modified discrete cosine transform and its inverse transform[J],IEEE,2004:626-628.
[3] Texas Instruments.TMS320C6414,TMS320C6415,TMS320C6416 fixed-point digital signal processors.SPRS 146N. 2005.
[4] 竇維蓓,劉若珩,王建昕,等,基于DSP的IMDCT快速算法[J].清華大學(xué)學(xué)報(bào),2000,40(3):99-103.
[5] Texas Instruments Incorporated.TMS320C6000系列DSP編程工具與指南[M].北京:清華大學(xué)出版社,2006.
[6] 馬君國,王遠(yuǎn)模,常華俊,等.在DSP處理器上并行實(shí)現(xiàn)ATR算法[EB/OL].http://www.eeworld.com.cn/designarticles/dsp/200703/11490.html.