
摘要:給出了一種由說(shuō)話者說(shuō)出控制命令,機(jī)器人進(jìn)行識(shí)別理解,并執(zhí)行相應(yīng)動(dòng)作的實(shí)現(xiàn)技術(shù)。在此,提出了一種高準(zhǔn)確率端點(diǎn)檢測(cè)算法、高精度定點(diǎn)DSP動(dòng)態(tài)指數(shù)定標(biāo)算法,以解決定點(diǎn)DSP實(shí)現(xiàn)連續(xù)隱馬爾科夫模型CHMM識(shí)別算法時(shí)所涉及的大量浮點(diǎn)小數(shù)運(yùn)算問(wèn)題,提高了定點(diǎn)DSP實(shí)現(xiàn)的實(shí)時(shí)性、精度,及其識(shí)別率。
關(guān)鍵詞:智能機(jī)器人;語(yǔ)音識(shí)別;隱馬爾可夫模型;DSP
0 引言
語(yǔ)音控制的基礎(chǔ)就是語(yǔ)音識(shí)別技術(shù),可以是特定人或者非特定人的。非特定人的應(yīng)用更為廣泛,對(duì)于用戶而言不用訓(xùn)練,因此也更加方便。語(yǔ)音識(shí)別可以分為孤立詞識(shí)別,連接詞識(shí)別,以及大詞匯量的連續(xù)詞識(shí)別。對(duì)于智能機(jī)器人這類嵌入式應(yīng)用而言,語(yǔ)音可以提供直接可靠的交互方式,語(yǔ)音識(shí)別技術(shù)的應(yīng)用價(jià)值也就不言而喻。
1 語(yǔ)音識(shí)別概述
語(yǔ)音識(shí)別技術(shù)最早可以追溯到20世紀(jì)50年代,是試圖使機(jī)器能“聽(tīng)懂”人類語(yǔ)音的技術(shù)。按照目前主流的研究方法,連續(xù)語(yǔ)音識(shí)別和孤立詞語(yǔ)音識(shí)別采用的聲學(xué)模型一般不同。孤立詞語(yǔ)音識(shí)別一般采用DTW動(dòng)態(tài)時(shí)間規(guī)整算法。連續(xù)語(yǔ)音識(shí)別一般采用HMM模型或者HMM與人工神經(jīng)網(wǎng)絡(luò)ANN相結(jié)合。
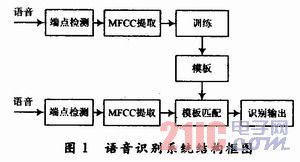
語(yǔ)音的能量來(lái)源于正常呼氣時(shí)肺部呼出的穩(wěn)定氣流,喉部的聲帶既是閥門,又是振動(dòng)部件。語(yǔ)音信號(hào)可以看作是一個(gè)時(shí)間序列,可以由隱馬爾可夫模型(HMM)進(jìn)行表征。語(yǔ)音信號(hào)經(jīng)過(guò)數(shù)字化及濾噪處理之后,進(jìn)行端點(diǎn)檢測(cè)得到語(yǔ)音段。對(duì)語(yǔ)音段數(shù)據(jù)進(jìn)行特征提取,語(yǔ)音信號(hào)就被轉(zhuǎn)換成為了一個(gè)向量序列,作為觀察值。在訓(xùn)練過(guò)程中,觀察值用于估計(jì)HMM的參數(shù)。這些參數(shù)包括觀察值的概率密度函數(shù),及其對(duì)應(yīng)的狀態(tài),狀態(tài)轉(zhuǎn)移概率等。當(dāng)參數(shù)估計(jì)完成后,估計(jì)出的參數(shù)即用于識(shí)別。此時(shí)經(jīng)過(guò)特征提取后的觀察值作為測(cè)試數(shù)據(jù)進(jìn)行識(shí)別,由此進(jìn)行識(shí)別準(zhǔn)確率的結(jié)果統(tǒng)計(jì)。訓(xùn)練及識(shí)別的結(jié)構(gòu)框圖如圖1所示。
1. 1 端點(diǎn)檢測(cè)
找到語(yǔ)音信號(hào)的起止點(diǎn),從而減小語(yǔ)音信號(hào)處理過(guò)程中的計(jì)算量,是語(yǔ)音識(shí)別過(guò)程中一個(gè)基本而且重要的問(wèn)題。端點(diǎn)作為語(yǔ)音分割的重要特征,其準(zhǔn)確性在很大程度上影響系統(tǒng)識(shí)別的性能。
能零積定義:一幀時(shí)間范圍內(nèi)的信號(hào)能量與該段時(shí)間內(nèi)信號(hào)過(guò)零率的乘積。
能零積門限檢測(cè)算法可以在不丟失語(yǔ)音信息的情況下,對(duì)語(yǔ)音進(jìn)行準(zhǔn)確的端點(diǎn)檢測(cè),經(jīng)過(guò)450個(gè)孤立詞(數(shù)字“0~9”)測(cè)試準(zhǔn)確率為98%以上,經(jīng)該方法進(jìn)行語(yǔ)音分割后的語(yǔ)音,在進(jìn)入識(shí)別模塊時(shí)識(shí)別正確率達(dá)95%。
當(dāng)話者帶有呼吸噪聲,或周圍環(huán)境出現(xiàn)持續(xù)時(shí)間較短能量較高的噪聲,或者持續(xù)時(shí)間長(zhǎng)而能量較弱的噪聲時(shí),能零積門限檢測(cè)算法就不能對(duì)這些噪聲進(jìn)行濾除,進(jìn)而被判作語(yǔ)音進(jìn)入識(shí)別模塊,導(dǎo)致誤識(shí)。圖2(a)所示為室內(nèi)環(huán)境,正常情況下采集到的帶有呼氣噪聲的數(shù)字“0~9”的語(yǔ)音信號(hào),利用能零積門限檢測(cè)算法得到的效果示意圖。最前面一段信號(hào)為呼氣噪聲,之后為數(shù)字“0~9”的語(yǔ)音。

從圖2(a)直觀的顯示出能零積算法在對(duì)付能量較弱,但持續(xù)時(shí)間長(zhǎng)的噪音無(wú)能為力。由此引出了雙門限能零積檢測(cè)算法。
所謂的雙門限能零積算法指的是進(jìn)行兩次門限判斷。第一門限采用能零積,第二門限為單詞能零積平均值。也即在前面介紹的能零積檢測(cè)算法的基礎(chǔ)上再進(jìn)行一次能零積平均值的判決。其中,第二門限的設(shè)定依據(jù)取決于所有實(shí)驗(yàn)樣本中呼氣噪聲的平均能零積及最小的語(yǔ)音單詞能零積之間的一個(gè)常數(shù)。如圖2(b)所示,即為圖2(a)中所示的語(yǔ)音文件經(jīng)過(guò)雙門限能零積檢測(cè)算法得到的檢測(cè)結(jié)果。可以明顯看到,最前一段信號(hào),即呼氣噪聲已經(jīng)被視為噪音濾除。
1.2 隱馬爾可夫模型HMM
隱馬爾可夫模型,即HMM是一種基于概率方法的模式匹配方法。它的應(yīng)用是20世紀(jì)80年代以來(lái)語(yǔ)音識(shí)別領(lǐng)域取得的重要成果。
一個(gè)HMM模型可以表示為:
![]()
式中:π為初始狀態(tài)概率分布,πi=P(q1=θi),1≤i≤N,表示初始狀態(tài)處于θi的概率;A為狀態(tài)轉(zhuǎn)移概率矩陣,(aij)N×N,aij=P(qt+1 =θj|qt=θi),1≤i,j≤N;B為觀察值概率矩陣,B={bj(ot)},j=1,2,…,N,表示觀察值輸出概率分布,也就是觀察值ot處于狀態(tài)j的概率。
1.3 模型訓(xùn)練
HMM有多種結(jié)構(gòu)類型,并且有不同的分類方法。根據(jù)狀態(tài)轉(zhuǎn)移矩陣(A參數(shù))和觀察值輸出矩陣(B參數(shù))的不同有不同類型的HMM。
對(duì)于CHMM模型,當(dāng)有多個(gè)觀察值序列時(shí),其重估公式由參考文檔給出,此處不再贅述。
1.4 概率計(jì)算
利用HMM的定義可以得出P(O|λ)的直接求取公式:
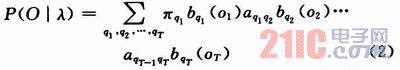
式(2)計(jì)算量巨大,是不能接受的。Rabiner提出了前向后向算法,計(jì)算量大大減小。定義前向概率:

式(2)表示的是初始前向概率,其中bi(o1)為觀察值序列處于t=1時(shí)刻在狀態(tài)i時(shí)的輸出概率,由于它服從連續(xù)高斯混合分布,故此值往往極小。根據(jù)大量實(shí)驗(yàn)觀察,通常小于10-10,此值在定點(diǎn)DSP中已不能用Q格式表示。分析式(3)可以發(fā)現(xiàn),隨著時(shí)間t的增加,還會(huì)有大量的小數(shù)之間的乘法加法運(yùn)算,使得新的前向概率值at+1更小,逐漸趨向于0,定點(diǎn)DSP采用普通的Q格式進(jìn)行計(jì)算時(shí)便會(huì)負(fù)溢出,即便不發(fā)生負(fù)溢出也會(huì)大大丟失精度。因此必須尋找一種解決方法,在不影響DSP實(shí)時(shí)性的前提下,既不發(fā)生負(fù)溢出,又能提高精度。
2 DSP實(shí)現(xiàn)語(yǔ)音識(shí)別
孤立詞語(yǔ)音識(shí)別一般采用DTW動(dòng)態(tài)時(shí)間規(guī)整算法。連續(xù)語(yǔ)音識(shí)別一般采用HMM模型或者HMM與人工神經(jīng)網(wǎng)絡(luò)ANN相結(jié)合。
為了能實(shí)時(shí)控制機(jī)器人,首先需要考慮的是能夠?qū)崿F(xiàn)實(shí)時(shí)地語(yǔ)音識(shí)別。而考慮到CHMM的巨大計(jì)算量以及成本因素,采用了數(shù)據(jù)處理能力強(qiáng)大,成本相對(duì)較低的定點(diǎn)數(shù)字信號(hào)處理器,即定點(diǎn)DSP。本實(shí)驗(yàn)采用的是TI公司多媒體芯片TMS320DM642。定點(diǎn)DSP要能準(zhǔn)確、實(shí)時(shí)的實(shí)現(xiàn)語(yǔ)音識(shí)別,必須考慮2點(diǎn)問(wèn)題:精度問(wèn)題和實(shí)時(shí)性問(wèn)題。
精度問(wèn)題的產(chǎn)生原因已經(jīng)由1.4節(jié)詳細(xì)闡述,這里不再贅述。因此必須找出一種可以提高精度,而又不會(huì)對(duì)實(shí)時(shí)性造成影響的解決方法。基于以上考慮,本文提出了一種動(dòng)態(tài)指數(shù)定標(biāo)方法。這種方法類似于科學(xué)計(jì)數(shù)法,用2個(gè)32 b單元,一個(gè)單元表示指數(shù)部分EXP,另一個(gè)單元表示小數(shù)部分Frac。首先將待計(jì)算的數(shù)據(jù)按照指數(shù)定標(biāo)格式歸一化,再進(jìn)行運(yùn)算。這樣當(dāng)數(shù)據(jù)進(jìn)行運(yùn)算時(shí),仍然是定點(diǎn)進(jìn)行,從而避開(kāi)浮點(diǎn)算法,從而使精度可以達(dá)到要求。
對(duì)于實(shí)時(shí)性問(wèn)題,通常,語(yǔ)音的頻率范圍大約是300~3 400 Hz左右,因而本實(shí)驗(yàn)采樣率取8 kHz,16 b量化。考慮識(shí)別的實(shí)現(xiàn),必須將語(yǔ)音進(jìn)行分幀處理。研究表明,大約在10~30 ms內(nèi),人的發(fā)音模型是相對(duì)穩(wěn)定的,所以本實(shí)驗(yàn)中取32 ms為一幀,16 ms為幀移的時(shí)間間隔。
解決實(shí)時(shí)性問(wèn)題必須充分利用DSP芯片的片上資源。利用EDMA進(jìn)行音頻數(shù)據(jù)的搬移,提高CPU利用率。采用PING—PONG緩沖區(qū)進(jìn)行數(shù)據(jù)的緩存,以保證不丟失數(shù)據(jù)。CHMM訓(xùn)練的模板放于外部存儲(chǔ)器,由于外部存儲(chǔ)器較片內(nèi)存儲(chǔ)器的速度更慢,因此開(kāi)啟CACHE。建立DSP/BIOS任務(wù),充分利用BIOS進(jìn)行任務(wù)之間的調(diào)度,實(shí)時(shí)處理新到的語(yǔ)音數(shù)據(jù),檢測(cè)語(yǔ)音的起止點(diǎn),當(dāng)有語(yǔ)音數(shù)據(jù)時(shí)再進(jìn)入下一任務(wù)進(jìn)行特征提取及識(shí)別。將識(shí)別結(jié)果用揚(yáng)聲器播放,并送入到機(jī)器人的控制模塊。
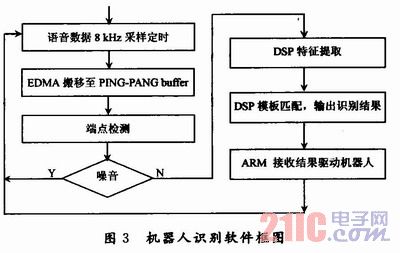
實(shí)驗(yàn)中,采用如圖3的程序架構(gòu)。
3 機(jī)器人控制
機(jī)器人由自然條件下的語(yǔ)句進(jìn)行控制。這些語(yǔ)句描述了動(dòng)作的方向,以及動(dòng)作的幅度。為了簡(jiǎn)單起見(jiàn),讓機(jī)器人只執(zhí)行簡(jiǎn)單命令。由手機(jī)進(jìn)行遙控,DSP模塊識(shí)別出語(yǔ)音命令,送控制命令到ARM模塊,驅(qū)動(dòng)左右機(jī)械輪執(zhí)行相應(yīng)動(dòng)作。
3.1 硬件結(jié)構(gòu)
機(jī)器人的硬件結(jié)構(gòu)如圖4所示。

機(jī)器人主要有2大模塊,一個(gè)是基于DSP的語(yǔ)音識(shí)別模塊;另一個(gè)是基于ARM的控制模塊,其機(jī)械足為兩滑輪。由語(yǔ)音識(shí)別模塊識(shí)別語(yǔ)音,由控制模塊控制機(jī)器人動(dòng)作。
3.2 語(yǔ)音控制
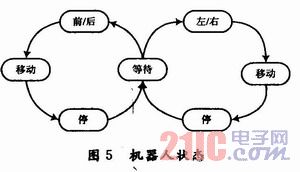
首先根據(jù)需要,設(shè)置了如下幾個(gè)簡(jiǎn)單命令:前、后、左、右。機(jī)器人各狀態(tài)之間的轉(zhuǎn)移關(guān)系如圖5所示。其中,等待狀態(tài)為默認(rèn)狀態(tài),當(dāng)每次執(zhí)行前后或左右轉(zhuǎn)命令后停止,即回到等待狀態(tài),此時(shí)為靜止?fàn)顟B(tài)。
語(yǔ)音的訓(xùn)練模板庫(kù)由4個(gè)命令加10個(gè)阿拉伯?dāng)?shù)字共14個(gè)組成,如下所示。
命令:“前”、“后”、“左”、“右”;
數(shù)字:“0~9”。
命令代表動(dòng)作的方向,數(shù)字代表動(dòng)作的幅度。當(dāng)執(zhí)行前后命令時(shí),數(shù)字的單位為dm,執(zhí)行左右轉(zhuǎn)彎命令時(shí),數(shù)字的單位為角度單位的20°。每句命令句法為命令+數(shù)字。例如,語(yǔ)音“左2”表示的含義為向左轉(zhuǎn)彎40°,“前4”表示向前直行4 dm。
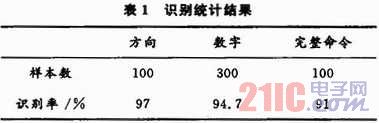
機(jī)器人語(yǔ)音控制的關(guān)鍵在于語(yǔ)音識(shí)別的準(zhǔn)確率。表1給出了5個(gè)男聲樣本的識(shí)別統(tǒng)計(jì)結(jié)果。
4 結(jié)語(yǔ)
工作中,成功地將CHMM模型應(yīng)用于定點(diǎn)DSP上,并實(shí)現(xiàn)了對(duì)機(jī)器人的語(yǔ)音控制。解決了CHMM模型巨大計(jì)算量及精度與實(shí)時(shí)性之間的矛盾。提出了一種新的端點(diǎn)檢測(cè)算法,對(duì)于對(duì)抗短時(shí)或較低能量的環(huán)境噪音具有明顯效果。同時(shí)需要指出的是,當(dāng)語(yǔ)音識(shí)別指令增多時(shí),則需要定義更多的句法,并且識(shí)別率也可能會(huì)相應(yīng)降低,計(jì)算量也會(huì)相應(yīng)變大。下一步研究工作應(yīng)更注重提高大詞匯量時(shí)的識(shí)別率及其魯棒性。