
文獻(xiàn)標(biāo)識(shí)碼: A
文章編號(hào): 0258-7998(2011)07-156-03
由于當(dāng)前計(jì)算機(jī)網(wǎng)絡(luò)的飛速發(fā)展,入侵檢測(cè)技術(shù)得到了研究者的廣泛重視,F(xiàn)orrest[1]等人在1996年首次提出以進(jìn)程正常運(yùn)行時(shí)產(chǎn)生的一定長度的系統(tǒng)調(diào)用短序列作為模型來表現(xiàn)進(jìn)程正常運(yùn)行時(shí)的狀態(tài)。Lee[2]等人則用RIPPER從系統(tǒng)調(diào)用序列中挖掘正常和異常模式,以規(guī)則的形式來描述系統(tǒng)的運(yùn)行狀態(tài),建立了一個(gè)更簡潔有效的系統(tǒng)正常模型。美國新墨西哥大學(xué)的Warrender[3]以系統(tǒng)調(diào)用為審計(jì)數(shù)據(jù),進(jìn)行了基于隱馬爾可夫模型HMM(Hidden Markov Model)的程序行為異常檢測(cè)研究。美國普渡大學(xué)的Lane [4]及其團(tuán)隊(duì)則利用了Unix用戶的shell命令作為審計(jì)數(shù)據(jù),進(jìn)行了基于HMM的用戶行為異常檢測(cè)研究和實(shí)驗(yàn)。西安交通大學(xué)的周星[5]提出一種利用進(jìn)程堆棧中的函數(shù)返回地址鏈信息來提取不定長模式的方法,并基于系統(tǒng)調(diào)用序列及其對(duì)應(yīng)的不定長模式序列構(gòu)建了一個(gè)兩層的HMM來檢測(cè)異常行為,取得了更低的誤報(bào)率和漏報(bào)率。
在以上檢測(cè)方法的基礎(chǔ)上,本文提出一種新的基于HMM的用戶行為異常檢測(cè)方法,與參考文獻(xiàn)[6]中提出的基于HMM的檢測(cè)方法相比,檢測(cè)效率和實(shí)時(shí)性相對(duì)較高,在檢測(cè)準(zhǔn)確率方面也有較大優(yōu)勢(shì)。
本文用一種不同的方法來建立和訓(xùn)練HMM模型,降低不必要的系統(tǒng)占用,并得到一個(gè)較好的正常行為模式與異常行為模式的區(qū)分效果。
2 基于HMM的用戶行為異常檢測(cè)方法
2.1 數(shù)據(jù)預(yù)處理
本文所采用的原始數(shù)據(jù)來自普渡大學(xué)的Lane團(tuán)隊(duì),他們花費(fèi)了很長時(shí)間去跟蹤了9個(gè)Unix用戶在2年內(nèi)的活動(dòng)記錄,以保證這些記錄的真實(shí)性。
參考文獻(xiàn)[4]對(duì)這些數(shù)據(jù)記錄進(jìn)行了預(yù)處理,將每次的命令運(yùn)用相同的起始、終止符隔開,將各命令中所出現(xiàn)的地址均用統(tǒng)一標(biāo)識(shí)方法代替,所涉及的文件也用相同的標(biāo)識(shí)方法代替,這樣的預(yù)處理使得原始數(shù)據(jù)更加整齊且易于分析。在此基礎(chǔ)上,本文又作了進(jìn)一步處理,對(duì)于命令行中所有出現(xiàn)的參數(shù)進(jìn)行處理,即將命令中的附加參數(shù)與命令本身結(jié)合設(shè)定為命令序列中的一條命令,而對(duì)于地址、網(wǎng)絡(luò)等記錄則直接從命令序列流中刪除。表1中左欄的數(shù)據(jù)流經(jīng)過本文二次處理后,該命令流序列如右欄所示,左欄中的14條記錄經(jīng)過處理后,減少為右欄中的8條記錄,減少了近50%。

采用本文方法進(jìn)行數(shù)據(jù)預(yù)處理的依據(jù)是:(1)在實(shí)際訓(xùn)練及檢測(cè)中,地址等參數(shù)并沒有實(shí)際意義。無論是按照shell命令序列長度,還是按照各命令本身出現(xiàn)頻率作為劃分狀態(tài)標(biāo)準(zhǔn),都并不需要此類命令內(nèi)容;(2)當(dāng)利用大數(shù)量的shell命令序列進(jìn)行建模和檢測(cè)時(shí),進(jìn)行這樣的二次處理可以降低對(duì)系統(tǒng)存儲(chǔ)空間的需求。
2.2 HMM建模
本文所建立的HMM模型的目的是為了描述一個(gè)正常用戶行為,用W代表合法用戶正常行為模式的總類數(shù),而相對(duì)應(yīng)的shell命令集合則如C=(L(1),L(2),…,L(W+1)),其中L(j)為包含若干個(gè)長度為l(j)的shell命令序列。W的值越大意味著對(duì)于命令集合分類得越精細(xì),所需要的系統(tǒng)資源也就越多。本文針對(duì)兩種不同的shell命令集合分類方法進(jìn)行了對(duì)比實(shí)驗(yàn),方法一是參考文獻(xiàn)[6]中使用的方法;方法二是本文提出的改進(jìn)隱馬爾科夫方法。
(2)設(shè)定W個(gè)序列出現(xiàn)頻率門限,記為η1,η2,η3,…,ηw,該門限的作用是判定每個(gè)Seqmj是否可以成為正常用戶行為觀測(cè)值,低于門限值的即舍去。
在C中的L(W+1)用來記錄未知和異常模式記錄的值,對(duì)于L(W+1)下shell命令記錄的判定方法為:當(dāng)l(W)=1時(shí),附加狀態(tài)W+1對(duì)應(yīng)的觀測(cè)值集合L(W+1)是由長度為1、且在Sw中出現(xiàn)頻率小于門限值?濁w的shell命令序列構(gòu)成,而當(dāng)l(W)≠1時(shí),則L(W+1)由所有長度為1的shell命令序列構(gòu)成。
2.2.2 改進(jìn)HMM方法
用戶對(duì)于日常操作都有一套自己的命令使用頻率,本文依據(jù)用戶與用戶之間的命令使用頻率差別作為行為分類依據(jù)。本文方法中的C表示方法與參考文獻(xiàn)[6]中一致,C=(L(1),L(2),…,L(W+1)),W的值增大,則出現(xiàn)頻率的分類更細(xì)化,也會(huì)增加系統(tǒng)存儲(chǔ)和處理量,但與參考文獻(xiàn)[6]的狀態(tài)分類方法相比要小很多。假設(shè)正常用戶的訓(xùn)練數(shù)據(jù)為R=(R1,R2,…,Rn),此時(shí)的用戶正常行為觀測(cè)值集合建立起來就相對(duì)簡單,根據(jù)訓(xùn)練數(shù)據(jù)R,生成W個(gè)出現(xiàn)頻率分別為l(1),l(2),…,l(W)的shell命令序列流,表示為S1,S2…,Sw,每個(gè)Si中包含了所有出現(xiàn)在頻率區(qū)域的shell命令記錄。同樣,劃分在附加狀態(tài)W+1下的shell命令序列,也就是未知和異常行為模式的值。
上述兩個(gè)建模方法各有利弊,對(duì)于參考文獻(xiàn)[6]的方法,在利用命令序列長度建模時(shí),其優(yōu)點(diǎn)是思路清晰,不同的狀態(tài)之間不會(huì)發(fā)生重疊,適用性強(qiáng)。缺點(diǎn)是由于每個(gè)狀態(tài)中Si都將存儲(chǔ)超過門限值的所有shell命令序列,這將是一個(gè)很大的存儲(chǔ)量(尤其是當(dāng)W達(dá)到一定值時(shí)。而本文方法的,優(yōu)點(diǎn)是利用命令的出現(xiàn)頻率分類,由于命令種類(即便加上了參數(shù))的局限性,所需要的存儲(chǔ)量將會(huì)少得多,運(yùn)算起來更快,也更為容易理解。缺點(diǎn)則是對(duì)于每個(gè)狀態(tài)對(duì)應(yīng)的頻率區(qū)域的劃分將更多地依賴歷史記錄和經(jīng)驗(yàn)。
2.3 HMM的訓(xùn)練
訓(xùn)練過程也就是參數(shù)估計(jì)過程,這個(gè)過程在研究中是極其重要的,傳統(tǒng)的思路是利用Baum-Welch 算法實(shí)現(xiàn),而實(shí)際上該算法并不是唯一的,也不是最好的算法。本文采用參考文獻(xiàn)[3]提出的改進(jìn)算法來實(shí)現(xiàn)對(duì)該HMM模型的訓(xùn)練。
2.4 HMM的檢測(cè)
檢測(cè)階段的主要工作是對(duì)被監(jiān)測(cè)用戶在被監(jiān)測(cè)時(shí)間內(nèi)執(zhí)行的shell命令行進(jìn)行處理,并利用在訓(xùn)練中已產(chǎn)生的HMM模型,計(jì)算相應(yīng)的判決值,進(jìn)而對(duì)該用戶的行為類別進(jìn)行判別。
假設(shè)在所需的檢測(cè)時(shí)間內(nèi)記錄該時(shí)間段內(nèi)用戶的命令流,記為R=(R1,R2,…,Rn)。其中,Ri為第i個(gè)獨(dú)立的shell命令序列,n為shell命令記錄的總量,此時(shí)的命令序列R中的值是按照時(shí)間順序依次得到的。
利用訓(xùn)練中的參數(shù)匹配方法,對(duì)于命令序列R進(jìn)行操作,得到狀態(tài)轉(zhuǎn)移序列q=(q1,q2,…,qx),其中,x為狀態(tài)轉(zhuǎn)移序列內(nèi)狀態(tài)的總數(shù),qi代表R中按時(shí)間排序的第i 個(gè)狀態(tài)。HMM檢測(cè)流程如下:
(1)根據(jù)訓(xùn)練數(shù)據(jù)R生成w個(gè)shell命令序列流S1,S2…,Sw,設(shè)定初始m:=1,j:=1,n:=0。
(2)如果m≤r-l(1)+1,則將Seqmj與L(j)進(jìn)行比較,

3 實(shí)驗(yàn)設(shè)計(jì)與結(jié)果分析
在本文的實(shí)驗(yàn)中,利用其中4個(gè)用戶userl、user2、user3、user4的數(shù)據(jù)進(jìn)行實(shí)驗(yàn),并設(shè)合法用戶為user2,將余下的user1、user3、user4視為非法或未知用戶。在該4個(gè)用戶的數(shù)據(jù)記錄中皆有超過15 000條命令行記錄。對(duì)于正常用戶,實(shí)驗(yàn)中將利用其中的前5 000條命令進(jìn)行正常行為模式的訓(xùn)練,得到HMM觀測(cè)值集合并確定HMM參數(shù),后5 000條命令作為正常行為的檢測(cè)。對(duì)于非法用戶,將分別用其中的5 000條命令進(jìn)行異常檢測(cè)的測(cè)試。在HMM模型建立及訓(xùn)練階段的參數(shù)設(shè)置為W=3,C={3,2,1}。在HMM模型建立過程中,從正常用戶user2的前5 000個(gè)shell命令中得到C(1),C(2),C(3)所對(duì)應(yīng)的命令序列個(gè)數(shù)如表2所示。

參考文獻(xiàn)[6]方法的異常檢測(cè)結(jié)果如圖1所示,上方曲線為合法用戶user2的正常行為測(cè)試數(shù)據(jù)對(duì)應(yīng)的判決值曲線,下方的3條曲線為非法用戶的異常行為測(cè)試數(shù)據(jù)對(duì)應(yīng)的判決值曲線(以下同)。

改進(jìn)的HMM方法得到的異常檢測(cè)測(cè)試結(jié)果如圖2所示。可以看出,相對(duì)于user2,三組非法用戶的值更加靠近于3,表明權(quán)值為2 和1 的命令序列所表示的合法用戶的正常行為模式在3個(gè)非法用戶行為序列中較少出現(xiàn),從圖1、圖2 中可以看出,改進(jìn)的HMM方法使得正常行為和異常行為測(cè)試數(shù)據(jù)對(duì)應(yīng)的判決值曲線具有良好的可分性。
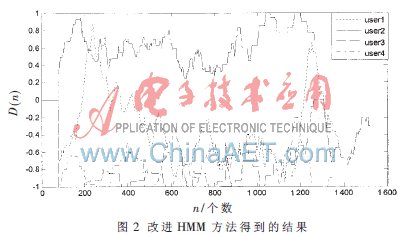
參考文獻(xiàn)[6]方法用于建模的命令序列有1 140個(gè),而改進(jìn)的HMM方法只有136個(gè),大大節(jié)約了系統(tǒng)存儲(chǔ)空間,所以,改進(jìn)HMM的方法具有較好的檢測(cè)準(zhǔn)確度,本文在運(yùn)算成本和計(jì)算效率之間取得了權(quán)衡,在實(shí)驗(yàn)中取得了一個(gè)很好的效果。
本文提出一種基于隱馬爾可夫模型的用戶行為異常檢測(cè)新方法,并通過實(shí)驗(yàn)對(duì)該方法的性能進(jìn)行了測(cè)試。實(shí)驗(yàn)表明,該方法具有很高的檢測(cè)準(zhǔn)確率和較強(qiáng)的可操作性。但需要指出的是,該方法中的一些檢測(cè)思想雖然適用于以系統(tǒng)調(diào)用為審計(jì)數(shù)據(jù)的程序行為異常檢測(cè),但具體的操作方式及檢測(cè)性能還有待分析和驗(yàn)證。
參考文獻(xiàn)
[1] FORREST S, HOFMEYR S A, SOMAYAJIA. A sense of self for UNIX processes[C]. Proceedings of IEEE Symposium on Security and Privacy, Los Alamos, California,1996.
[2] LEE W, STOLFO S J. Data mining approaches for intrusion detection[C].Proceedings of the 7th US ENIX Security Symposium, San Antonio, Texas, 1998.
[3] WARRENDER C, FORREST S, PEARLMUTTER B. Detecting intrusions using system calls: alternative data models[C]. Proceedings of the IEEE Symposium on Security and Privacy, Oakland, CA, USA, 1999:133-145.
[4] LANE T. Machine learning techniques for the computer security domain of anomaly detection[D].Purdue University 2000.
[5] 周星, 彭勤科, 王靜波. 基于兩層隱馬爾可夫模型的入侵檢測(cè)方法[J].計(jì)算機(jī)應(yīng)用研究, 2008,25(3):911-914.
[6] 鄔書躍,田新廣.基于隱馬爾科夫模型的用戶行為異常檢測(cè)新方法[J].通信學(xué)報(bào),2007,28(4):38-43.