
摘 要: 提出一種基于概率與信息熵理論的實值屬性離散化方法,綜合考慮了各對合并區(qū)間之間的差異性;該方法利用信息熵衡量相鄰區(qū)間的相似性,同時考慮離散區(qū)間大小和區(qū)間類別數(shù)對學習精度的影響,并通過概率的方法得到了這兩個因素的衡量標準。仿真結(jié)果表明,新方法對See5/C5.0分類器有較好的分類學習能力,并在腫瘤診斷中得到了很好的應用。
關(guān)鍵詞: 離散化;數(shù)據(jù)挖掘;概率;信息熵
連續(xù)屬性離散化是數(shù)據(jù)挖掘和機器學習的重要預處理步驟,直接影響到機器學習的效果。在分類算法中,對訓練樣本集進行離散化具有兩重意義:一方面可以有效降低學習算法的復雜度,加快學習速度,提高學習精度;另一方面可以簡化、歸納獲得的知識,提高分類結(jié)果的可理解性。很多離散化方法的提出,主要分為以下兩種類型[1]:(1)自底向上和自頂向下的離散化方法。自底向上離散化方法是以每個屬性值為一個區(qū)間,然后迭代地合并相鄰區(qū)間;自頂向下離散化方法是把整個屬性的值域視為一個區(qū)間,遞歸地向該區(qū)間中添加斷點。(2)有監(jiān)督和無監(jiān)督離散化方法。有監(jiān)督方法使用決策類信息進行離散化,如Ent-MDLP[2]、CAIM[3]和Chi2-based[4-5]等算法。Ent-MDLP使用熵的理論來評價候選斷點,選擇使得整體熵值最小的斷點作為最終斷點,并且通過最小描述長度原則來確定離散區(qū)間數(shù);CAIM是一種自頂向下離散化方法,該方法依據(jù)類與屬性間的關(guān)聯(lián)度,提出一種啟發(fā)式離散化標準,計算當前狀態(tài)的標準值來判別當前斷點是否應該被加入斷點集合中。自底向上的Chi2-based離散化算法使用卡方統(tǒng)計來確定當前相鄰區(qū)間是否被合并,并采用顯著性水平值逐漸降低的方法檢驗系統(tǒng)的不一致率,確定離散化進程是否終止。然而,Chi2-based方法在衡量區(qū)間差異時沒有考慮區(qū)間大小和區(qū)間類別數(shù)對離散化結(jié)果的影響,可能會導致學習精度的降低;而無監(jiān)督離散化方法則不考慮類的信息。傳統(tǒng)的無監(jiān)督離散化方法包括EWD(Equal Width Discretization)和EFD(Equal Frequency Discretization),這兩個算法實現(xiàn)簡單且計算消耗低,但結(jié)果往往難以滿足預計的要求。
本文提出一種基于概率與信息熵理論的實值屬性離散化方法PIE(Probability and Information Entropy),綜合考慮了各對合并區(qū)間之間的差異性,利用信息熵衡量相鄰區(qū)間的相似性,同時考慮離散區(qū)間大小和區(qū)間類別數(shù)對分類能力的影響,并通過概率的方法得到了這兩個因素的衡量指標。實驗結(jié)果表明,PIE顯著地提高了See5/C5.0分類器分類學習精度,并在乳腺腫瘤診斷中得到了很好的應用。
1 PIE離散化
離散化問題描述如下:對于m個連續(xù)屬性的數(shù)據(jù)集,樣本點個數(shù)為N,決策類別數(shù)為S,數(shù)據(jù)集中任意一個連續(xù)屬性為a,可以將連續(xù)屬性的值域離散成I個區(qū)間:
P:{[d0,d1],[d1,d2],…,[dI-1,dI]}
其中,d0是連續(xù)屬性A的最小值,dI是a的最大值,屬性a的值按升序進行排列,{d0,d1,d2,…,dI-1,dI}為離散過程中的斷點集合。屬性a的每個值都可以劃分到離散的I個區(qū)間的某一個區(qū)間中。

對于一個連續(xù)屬性的各對相鄰區(qū)間,它們對應的類分布是不同的,類分布最相似的區(qū)間應該先被合并。事實上,從信息通信的角度考慮,區(qū)間在合并前與合并后需要轉(zhuǎn)換信息量,轉(zhuǎn)換的信息量越小,說明兩個區(qū)間對應的類分布越相似,它們應該被合并,反之亦然。由于相鄰兩區(qū)間的樣本數(shù)為M,需要轉(zhuǎn)換M次,因此,用M×[H(I)-H(I1,I2)]作為區(qū)間相似性的衡量標準。
為了更好地衡量各對合并區(qū)間之間的差異性,僅考慮類分布的相似性是不夠的,還需要考慮離散區(qū)間大小和區(qū)間中類別數(shù)對離散化結(jié)果的影響,進而會影響到分類器的學習精度。通過概率的方法可獲得兩個因素的衡量標準,對于任意連續(xù)屬性,每一對相鄰區(qū)間(I1和I2)的樣本數(shù)是不同的,可視為變量{Mi},則p({Mi+})代表兩個區(qū)間樣本數(shù)的集合可能性,即:

2 仿真結(jié)果
2.1 UCI數(shù)據(jù)集實驗結(jié)果
為了評價PIE的性能,采用了UCI機器學習數(shù)據(jù)庫[7]中的10個數(shù)據(jù)集,見表1所示。該數(shù)據(jù)集是數(shù)據(jù)挖掘等實驗常用的數(shù)據(jù),其中包括兩個大的數(shù)據(jù)集Page-blocks和Letter。PIE方法與以下幾種方法進行了比較:傳統(tǒng)的無監(jiān)督離散化方法EFD;基于熵的最小描述長度離散化方法Ent-MDLP;流行的自頂向下離散化方法CAIM;經(jīng)典的自底向上離散化方法Chi2。
10個數(shù)據(jù)集分別采用上面的離散化方法進行離散數(shù)據(jù),使用Weka數(shù)據(jù)挖掘工具進行實驗,采用See5分類器對離散后的數(shù)據(jù)進行分類預測。采用10折交叉驗證的方法,將數(shù)據(jù)集分成10等份,分別將其中9份作為訓練集,剩下1份作為測試集,重復10次取平均值,對平均學習精度統(tǒng)計進行對比,見表2所示。
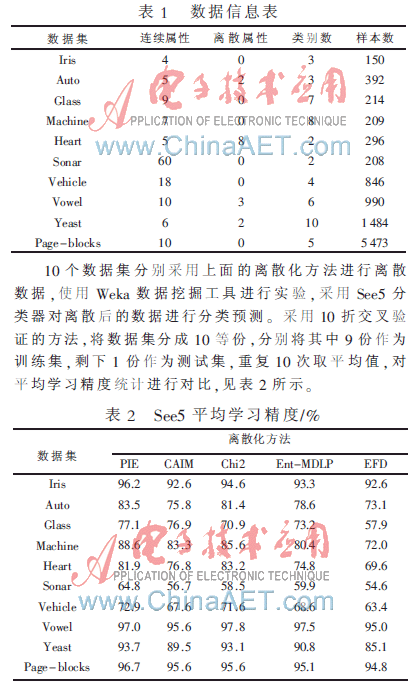
從表2中可以看出,除了Heart和Vowel數(shù)據(jù)集,本文提出的PIE離散化方法的See5平均學習精度均有所上升,這正是離散化方法期望得到的結(jié)果,由此充分顯示了PIE算法的優(yōu)勢。而對于CAIM、Ent-MDLP和EFD三種離散化方法均則未引入不一致衡量標準,即它們沒有對數(shù)據(jù)的有效性進行控制,在離散化過程中丟失了大量的信息,導致分類預測的精度比Chi2和PIE方法平均低很多。
2.2 PIE在乳腺腫瘤診斷上的效用
乳腺腫瘤診斷的實驗數(shù)據(jù)來自于UCI機器學習數(shù)據(jù)庫中的Breast Cancer Wisconsin數(shù)據(jù)集,將Breast Cancer Wisconsin刪掉屬性值不全的病例樣本,剩下683個病例樣本,病理檢測有9項(Clump Thickness、Uniformity of Cell Size、Uniformity of Cell Shape、 Marginal Adhension、Single Epithelial Cell Size、Bare Nuclei、Bland Chromatin、Normal Nucleoli、Mitoses),即9個屬性,每個屬性取值范圍[1,10],病情狀況分為兩類:一類表示腫瘤為惡性,另一類表示腫瘤為良性。這樣,每個樣本有9個連續(xù)條件屬性,1個決策屬性,選取樣本的80%作為訓練集,20%作為測試集。
將Breast Cancer Wisconsin用本文所提出的PIE算法進行離散化,然后分別使用See5和PIE+See5對離散前和離散后的數(shù)據(jù)進行分類預測,結(jié)果見表3。

從表3中可以明顯看出,未經(jīng)過離散化處理的BCW病例數(shù)據(jù)集進行See5分類預測的測試準確度為92.55%,而PIE+See5方法的測試準確度為99.27%,比未被離散化的進行See5預測精度高出6.72%,相當于每1 000個患者中就多出約67個患者可以被準確地診斷出腫瘤為良性或是惡性,對患者及時治療有很大幫助。
在BCW數(shù)據(jù)被離散化后,其病理指標被刪去了三項:Uniformity of Cell Shape(細胞形狀均勻度)、Bland Chromatin(平淡的染色質(zhì))、Mitoses,可以只考慮其他六項,簡化了信息系統(tǒng),減輕了醫(yī)生的工作量。另外,利用PIE+See5方法離散后不同樣本占樣本總數(shù)比例只有44.36%,刪除冗余的病例樣本后,只剩余了303個病例樣本,從而使原來的病例樣本空間在橫向和縱向上都得到了降維,可以得到更加穩(wěn)固的訓練模型,在醫(yī)學數(shù)據(jù)挖掘中具有良好的發(fā)展前景。
連續(xù)屬性離散化方法的研究對數(shù)據(jù)挖掘與機器學習領(lǐng)域的研究與應用具有重要的作用。本文提出一種基于概率與信息熵理論的實值屬性離散化方法,綜合考慮了各對合并區(qū)間之間的差異性,能夠更合理準確地離散化,該方法為該領(lǐng)域提供了新思路,具有一定應用價值意義。
參考文獻
[1] DOUGHERTY J, KOHAVI R, SAHAMI M. Supervised and unsupervised discretization of continuous feature[C]. Proceedings of the 12th International Conference of Machine learning. San Francisco: Morgan Kaufmann, 1995.
[2] FAYYAD U, IRANI K. Multi-interval discretization of continuous-valued attributes for classification learning[C]. Proceedings of the 13th International Joint Conference on Artificial Intelligence. San Mateo, CA: Morgan Kaufmann, 1993.
[3] KURGAN L A, CIOS K J. CAIM discretization algorithm[J]. IEEE Transactions on Knowledge and Data Engineering,2004, 16(2): 145–153.
[4] LIU H, SETIONO R. Feature selection via discretization[J]. IEEE Transactions on Knowledge and Data Engineering,1997, 9(4): 642-645.
[5] CHAO T S, JYH H H. An extended chi2 algorithm for discretization of real value attributes[J]. IEEE Transactions Knowledge and Data Engineering, 2005,17(3):437-441.
[6] PAWLAK Z. Rough sets[J]. International Journal of Computer and Information Sciences, 1982,11(5):341-356.
[7] HETTICH S, BAY S D. The UCI KDD Archive [DB/OL]. http://kdd.ics.uci.edu/, 1999.