
??? 摘 要: 針對實(shí)際中存在的各類別樣本錯分造成不同危害程度的分類問題,提出了一種基于屬性加權(quán)的代價敏感支持向量機(jī)分類算法,即在計(jì)算各個樣本特征屬性對分類的重要度之后,對相應(yīng)的屬性進(jìn)行重要度加權(quán),所得的數(shù)據(jù)用于訓(xùn)練和測試代價敏感支持向量機(jī)。數(shù)值實(shí)驗(yàn)的結(jié)果表明,該方法提高了誤分代價高的類別的分類精度,同時屬性重要度的引入提高了分類器的整體分類性能。該方法對錯分代價不對稱的數(shù)據(jù)分類問題具有重要的現(xiàn)實(shí)意義。
關(guān)鍵詞: 屬性加權(quán); 支持向量機(jī); 代價敏感支持向量機(jī)
?
SVM算法是一種專門研究小樣本情況下機(jī)器學(xué)習(xí)規(guī)律的理論,它能夠解決漸進(jìn)理論所難于解決的過擬合、局部極小和泛化能力差等問題。這一新的機(jī)器學(xué)習(xí)方法表現(xiàn)出很多優(yōu)于已有方法的性能,迅速引起各領(lǐng)域的關(guān)注和研究,并成功地引入到很多領(lǐng)域的應(yīng)用中,取得了大量的應(yīng)用研究成果。
在SVM算法的研究中,提高它的分類能力是所有研究的宗旨和目的,很多學(xué)者提出了改進(jìn)的支持向量機(jī)方法:給每一類樣本賦以不同權(quán)值的加權(quán)支持向量機(jī)算法WSVM(Weighted SVM)[1-2],對類別差異造成的影響進(jìn)行相應(yīng)的補(bǔ)償,提高了小類別樣本的分類精度,但影響了整體的分類性能;將模糊學(xué)引入了支持向量機(jī),提出了模糊支持向量機(jī)算法FSVM(Fuzzy SVM)[3-4],減少野值和噪聲的影響;利用樣本的屬性重要度的支持向量機(jī)方法[5],給各個屬性設(shè)定相應(yīng)的權(quán)值,提高了分類的精度。
針對實(shí)際應(yīng)用中各類別樣本錯分所造成的不同程度危害,提出了代價敏感支持向量機(jī)算法[6],該方法對支持向量機(jī)算法進(jìn)行改進(jìn),將分類代價考慮進(jìn)去,使得分類結(jié)果的代價最小,該方法對錯分代價不對稱的數(shù)據(jù)分類問題具有重要的現(xiàn)實(shí)意義,如網(wǎng)絡(luò)故障、網(wǎng)絡(luò)安全等。
1 支持向量機(jī)
支持向量機(jī)的基本思想是對于給定的樣本集(xi,yi),xi∈Rn,yi∈{+1,-1},i=1,…,l,其中xi是n維空間中的向量,yi是xi所屬類的類別標(biāo)識,尋找將兩類數(shù)據(jù)正確分開并使分類間隔最大的超平面,該超平面稱為最優(yōu)超平面,分類情況如圖1所示。
?

為了尋找最優(yōu)超平面,需要求解下面的二次規(guī)劃問題:
 ???????????????????????????
???????????????????????????
其中,
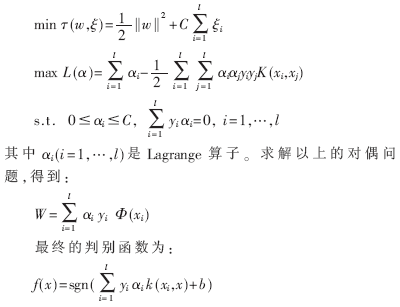
這是由Vapnik提出的第一種支持向量機(jī),也被稱為C-SVM或標(biāo)準(zhǔn)支持向量機(jī)。
2 代價敏感支持向量機(jī)
考慮兩類的分類問題,類別分別為C+和C-,假定C+的錯分代價大于C-的錯分代價。為了解決分類中的代價不對稱問題,將分類算法SVM進(jìn)行改造,基本思想就是對C+錯分、C-錯分兩種錯誤分別引入不同的代價函數(shù)。這種方法等價于對誤分代價高的類使用更大的拉格朗日算子αi,從而使分類平面遠(yuǎn)離C+,而靠近C-,使得未知數(shù)據(jù)被劃分為C+的概率更大,從而減小了分類中因錯分引起的損失。
在支持向量機(jī)(SVM)中,原始問題為:
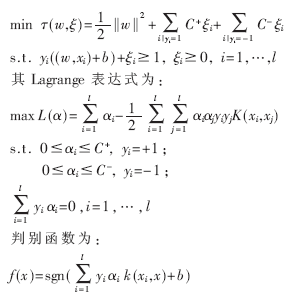
在訓(xùn)練過程中使用C+>C-,得到的分類器的決策平面靠近類別C-,使測試樣本更多地落在C+的區(qū)域中,從而減小C+類的樣本錯分的可能性,但也加大了C-類樣本被錯分的可能性。因此需尋找合適的參數(shù),使得兩類樣本的分類結(jié)果都盡可能地達(dá)到最優(yōu)。設(shè)兩類樣本的約束值的比值為:
s=C+/C-
s值通常使用窮舉的方法來確定,先固定C-的值為C,搜索最佳參數(shù)C+的值,使得分類的錯誤代價最小。
代價敏感支持向量機(jī)的主要思想就是通過改變兩類的懲罰因子C+和C-的比值,使得分類面向遠(yuǎn)離錯分代價高的一類的方向移動,從而使得樣本更大可能地被分為這一類,降低分類錯誤代價,但提高某一類樣本的分類正確率總是以犧牲另一類的分類正確率為代價的。
3 屬性的權(quán)值
樣本屬性重要性的度量是屬性相關(guān)分析的主要內(nèi)容,在模糊集和粗糙集理論方面有許多的研究。這里介紹常用的基于信息熵的屬性權(quán)值的計(jì)算方法[6]。
設(shè)有數(shù)據(jù)樣本集合S,該樣本集有m個不同的屬性值和n個不同的類別,分別定義為Ai(i=1,…,m)和Cj(j=1,…,n),si為Ci中的樣本數(shù)。根據(jù)概率分布和聯(lián)合概率分布以及信息論中熵和條件熵的定義,對于一個給定的樣本分類問題所需的期望信息由下式給出:

式中 pi是樣本屬于Cj的概率,其中 pi=si/s。
設(shè)屬性A有v個不同值{a1,a2,…,av},屬性A可將樣本集S劃分為v個子集{s1,s2,…,sv},其中Sj為在屬性A上具有值ai,設(shè)sij為子集Sj中類Ci的樣本數(shù)。根據(jù)A的這種劃分的期望信息為:

式中pij=sij/|sj|,|sj|是sj中樣本屬于類Ci的概率。
在屬性A上該劃分獲得的信息增益為:
δ=H(C)-E(A)
根據(jù)上面的計(jì)算得到每個屬性的權(quán)重系數(shù)為:
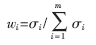
從分析中知道,該權(quán)重系數(shù)反應(yīng)了樣本中各個屬性的重要程度,權(quán)重系數(shù)值越大則該屬性越重要,對分類的貢獻(xiàn)越大。
在確定了樣本屬性重要度后,就可以構(gòu)造基于樣本屬性重要度的代價敏感支持向量機(jī)。
4 實(shí)驗(yàn)結(jié)果
本文利用MATLAB軟件進(jìn)行模擬實(shí)驗(yàn),對+1類和-1類的分類性能進(jìn)行比較,在三維空間中引入兩類不同的樣本:正類和負(fù)類,并引入了一定數(shù)量的噪聲和野值數(shù)據(jù)。為了驗(yàn)證所提算法的有效性,利用所提算法進(jìn)行了一系列比較實(shí)驗(yàn)。在實(shí)驗(yàn)中,模擬用的訓(xùn)練樣本和測試樣本均隨機(jī)產(chǎn)生,樣本數(shù)據(jù)情況如表1所示。
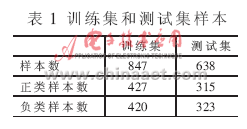
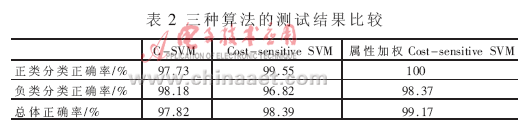
在實(shí)驗(yàn)中考慮正類的錯分代價大于負(fù)類的錯分代價,分別用C-SVM、Cost-sensitive SVM和屬性加權(quán)的Cost-sensitive SVM進(jìn)行性能測試,表2所示為分類準(zhǔn)確率的比較。由表2可見代價敏感支持向量機(jī)分類算法提高了錯分代價高的類別的分類精度,在進(jìn)行屬性加權(quán)后,總體的分類精度也得到了提高。
本文在對支持向量機(jī)分析的基礎(chǔ)上,提出了對樣本屬性加權(quán)型的代價敏感加權(quán)支持向量機(jī)。數(shù)值實(shí)驗(yàn)的結(jié)果表明,該方法能夠提高錯分代價敏感的類別的分類精度,同時整體的分類性能也得到了提高。但是如何確定代價系數(shù)仍然是一個需要解決的問題,也是筆者下一步要研究的方向。
參考文獻(xiàn)
[1]?范昕煒,杜樹新,吳鐵軍.可補(bǔ)償類別差異的加權(quán)支持向量機(jī)算法[J].中國圖像圖形學(xué)報,2003,8(7):1037-1042.
[2]?賈銀山,賈傳熒. 一種加權(quán)支持向量機(jī)分類算法[J].計(jì)算機(jī)工程,2005,10(5):35-39.
[3]?LIN C F, WANG S D. Fuzzy support vector machine [J].?IEEE Trans. On Neural Networks, 2002, 13(2):464-471.
[4]?陳小娟, 劉三陽. 一種新的模糊支持向量機(jī)算法[J].西安文理學(xué)院學(xué)報:自然科學(xué)版,2008,11(1):1-4.
[5]?汪延華,田盛豐. 樣本屬性重要度的支持向量機(jī)方法[J]. 北京交通大學(xué)學(xué)報,2007,10(5):43-46.
[6]?趙靖.基于SVM算法的垃圾郵件過濾研究與實(shí)現(xiàn)[D].北京:北京交通大學(xué),2005.