
1 引言
在如今的快速嵌入式系統(tǒng)設(shè)計(jì)中,目前比較流行的方案是在FPGA內(nèi)集成應(yīng)用軟件或是軟IP平臺(tái),以簡化工序、加速產(chǎn)品面市日程。為此,很多公司推出了自己的開發(fā)平臺(tái)以及相關(guān)CPU的IP核,常見的為兩種:一種是通用型CPU,如xilinx和altera公司的32位以及64位通用CPU核;還有就是專用型的,常見的為51系列單片機(jī)的CPU核,但是目前關(guān)于單片機(jī)的軟核基本上都是8051的,其他的品種很少。而且8051的速度不是很快,在有些快速的控制場合(如利用單片機(jī)來作為usb2.0的控制部件)顯得速度不足,比較著名的actel公司推出的Core8051,運(yùn)行頻率也只在40 MHz左右。本文介紹了一個(gè)非常高速DS80C320單片機(jī)軟核的設(shè)計(jì)。
DS80C320單片機(jī)是DALLAS公司推出的一款基于51框架的高性能單片機(jī)。
它有如下一些優(yōu)點(diǎn):
ⅰ,具有與51系列完全一致的指令系統(tǒng),能充分兼容所有基于51系列開發(fā)的程序;
ⅱ,具有比8051更加齊全的外設(shè)。相比8051單片機(jī),DS80C320增加了定時(shí)器2以及一個(gè)增強(qiáng)型串口等;
ⅲ,具有比8051更好的效率;DS80C320的一個(gè)指令周期是4個(gè)CLK,8051則是12個(gè),這個(gè)區(qū)別尤其是在處理簡單指令的時(shí)候優(yōu)勢明顯,例如單周期指令的處理,DS80C320只需要4個(gè)CLK,而8051需要12個(gè),據(jù)DALLAS公司的統(tǒng)計(jì)表明,在相同時(shí)鐘頻率下,DS80C320每條指令的執(zhí)行速度是8051的1.5~3倍,對于典型的應(yīng)用程序來說,執(zhí)行速度也是8051的2.5倍左右。
ⅳ,其讀取指令的方式比8051更加適合IP核的特點(diǎn);將單片機(jī)內(nèi)部ROM去掉,完全從外部讀取指令,這種特點(diǎn)作為軟核是很適合的,首先是結(jié)構(gòu)簡單,有利于指令讀取的流水設(shè)計(jì),其次可以突破內(nèi)部ROM大小的限制,最后,作為FPGA設(shè)計(jì)的特點(diǎn),即使8051的設(shè)計(jì),內(nèi)部ROM塊也是放在FPGA芯片的ROM資源里面,與其這樣,還不如直接放到外面更加簡化時(shí)序與結(jié)構(gòu);
2 總體結(jié)構(gòu)劃分
如圖所示為DS80C320軟核的總體功能圖:

圖1 DS80C320功能框圖
本IP核的設(shè)計(jì)主要按照指令執(zhí)行的流程來安排功能塊,并通過數(shù)據(jù)總線來傳遞數(shù)據(jù);虛線里面的為CPU核心;首先是ROM模塊,DS80C320并沒有內(nèi)部ROM,所以該模塊功能主要是分析從P端口讀取過來的指令,并通過查找指令的長度以及周期數(shù)目,從而計(jì)算出相關(guān)控制信號發(fā)送給CPU控制模塊以便控制指令的讀取;同時(shí),如果指令為LCALL或者ACALL,則可以分析出子程序入口地址并報(bào)送PC模塊,引導(dǎo)PC正確跳轉(zhuǎn);在ROM模塊分析指令的同時(shí),譯碼器DECODER也在進(jìn)行譯碼的動(dòng)作,它將根據(jù)指令的8位數(shù)據(jù)分析出三個(gè)重要的參數(shù):ALU的動(dòng)作類型,該指令的操作數(shù)據(jù)來源以及讀取方式,該指令結(jié)果的存放位置以及存放方式;第一個(gè)參數(shù)送給ALU模塊,其余兩個(gè)送到CPU控制模塊;CPU控制模塊CPU_CON是整個(gè)CPU的核心部分,主要完成兩個(gè)作用:ALU執(zhí)行前的讀取數(shù)據(jù)控制,以及ALU執(zhí)行完成之后回寫數(shù)據(jù)控制;該模塊同時(shí)也控制著整個(gè)CPU的時(shí)序,監(jiān)視其他模塊的執(zhí)行情況;ALU則主要是完成計(jì)算工作;INteR模塊則是中斷系統(tǒng)的控制模塊,其功能主要完成對各個(gè)中斷源所提交的中斷請求的有效判斷以及排序,產(chǎn)生中斷標(biāo)志并且將判斷結(jié)果以及中斷入口地址編碼提交給ROM模塊,以指示程序跳轉(zhuǎn),同時(shí)還需要負(fù)責(zé)在中斷完成之后清除中斷標(biāo)志以及恢復(fù)中斷之前的中斷等級; DS80C320有三個(gè)定時(shí)器和2個(gè)串行口,其中定時(shí)器2和串行口如果不需要的話可以裁減;至于其他的模塊或者寄存器則在CPU控制模塊的控制下通過數(shù)據(jù)總線交換數(shù)據(jù);可見,本設(shè)計(jì)的思路是以CPU_CON控制整個(gè)CPU的執(zhí)行以及時(shí)序,以INTER控制整個(gè)中斷系統(tǒng),其他寄存器則以數(shù)據(jù)總線來完成數(shù)據(jù)的交換,均勻的分布在數(shù)據(jù)總線的兩側(cè),結(jié)構(gòu)清晰簡單,規(guī)則化的設(shè)計(jì)也有利于提高速度,以及方便裁減。
3 一些設(shè)計(jì)特點(diǎn)
3.1時(shí)序設(shè)計(jì)
在DS80C320單片機(jī)的資料里面只有外部接口的時(shí)序介紹,對于內(nèi)部的信號執(zhí)行則沒有說明,因此需要重新規(guī)劃,本軟核對DS80C320的時(shí)序進(jìn)行了詳細(xì)的分析,按照黑盒子的思想,加入了流水線的技巧,對其時(shí)序的設(shè)計(jì)如下:
對于普通指令的執(zhí)行過程,內(nèi)部時(shí)序劃分如下:

圖2 DS80C320內(nèi)部時(shí)序圖
這是一條單字節(jié)單周期指令的執(zhí)行過程,在C1的上升沿開始譯碼以及查找本指令的長度周期表,同時(shí),數(shù)據(jù)總線上面是正在回寫的上一條指令的結(jié)果;到了C2的上升沿,數(shù)據(jù)總線和地址總線的控制權(quán)就回到了本條指令的手里,這個(gè)時(shí)候地址總線用來發(fā)送需要讀取的數(shù)據(jù)的地址,數(shù)據(jù)總線則做好從發(fā)送數(shù)據(jù)到接收數(shù)據(jù)的準(zhǔn)備,這個(gè)動(dòng)作由CPU控制模塊完成;然后在C3的上升沿,被選中模塊根據(jù)地址總線和控制總線讀出相關(guān)數(shù)據(jù)并送入數(shù)據(jù)總線,在這以后的一個(gè)時(shí)鐘長度的時(shí)間里面,ALU接到了數(shù)據(jù),然后在C4的上升沿,開始執(zhí)行數(shù)據(jù)處理,同時(shí),CPU控制模塊再次改變地址總線和控制總線的內(nèi)容,并發(fā)布寫信號,提示開始被選中讀數(shù)的模塊放棄對數(shù)據(jù)總線的控制權(quán),以及被選中的存儲(chǔ)結(jié)果的模塊分析寫入類型,作好接收數(shù)據(jù)的準(zhǔn)備,ALU在計(jì)算完成之后就將結(jié)果放到數(shù)據(jù)總線,等待下一個(gè)周期的C1開始將結(jié)果寫入相關(guān)位置;總之,本設(shè)計(jì)充分利用了數(shù)據(jù)總線的資源和流水設(shè)計(jì)的技巧,將本來需要6個(gè)時(shí)序的操作簡化為4個(gè)就完成了,時(shí)序緊湊,速度快;同時(shí)采用了分布式處理的思想,大大簡化了CPU控制模塊的功能,只發(fā)布控制信號,具體哪個(gè)模塊需要執(zhí)行什么功能由該模塊自行根據(jù)控制信號來判斷,有利于避免由于局部功能太過集中而造成的芯片局部過熱的問題;
3.2指令長度周期表的設(shè)計(jì)
指令長度表主要是用來控制取指令,以及辨別指令代碼和指令參數(shù);而指令周期表則主要是用來控制指令執(zhí)行的時(shí)間,這兩個(gè)表可以簡化對指令執(zhí)行的控制。一般這個(gè)過程由ROM模塊根據(jù)已經(jīng)讀取的指令來查表,然后根據(jù)查表的結(jié)果和時(shí)序情況來處理分析,產(chǎn)生一系列控制信號,并發(fā)送給CPU控制模塊,這樣做的好處主要是避免CPU控制模塊與指令以及數(shù)據(jù)打交道,減少其輸入輸出端口數(shù)目;指令長度周期表的設(shè)計(jì)是和讀取方式息息相關(guān)的,本設(shè)計(jì)使用自己單獨(dú)構(gòu)建的表,并且一分為二,處理方式是為:index={lsb_3, ir[7:4]},其中l(wèi)sb_3的含義為:對于指令的低三位(ir(2 downto 0)) 規(guī)則為:8-F=》7,6-7=》6,0-5不變化。兩個(gè)表使用相同的讀取方式,這樣既可以簡化結(jié)構(gòu),將查找空間降低為7位,又可以提高查找速度;
3.3 PC異動(dòng)編碼的作用
在單片機(jī)內(nèi)部,PC是需要不停變化的,不僅所有的跳轉(zhuǎn)類指令都需要改變PC的內(nèi)容,而且中斷類指令還需要完成PC的出棧以及入棧操作;因此,有些模型里面對PC的處理異常復(fù)雜,基本上是對每條指令詳細(xì)規(guī)定PC的變化;本設(shè)計(jì)在這方面的處理采用了編碼的技巧來提高速度;首先分析編碼的可能性,雖然很多指令可以改變PC的內(nèi)容,但是對于PC來說,除了正常的加1操作,其它的變化方式只有如下幾種:
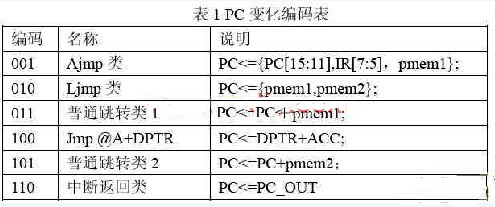
其中pmem1和pmem2為指令參數(shù),來自于ROM模塊;PC_OUT為堆棧中的PC內(nèi)容。
剩下的難題就是由誰來發(fā)出這個(gè)編碼,對于所有的跳轉(zhuǎn)類指令以及中斷類指令,每條指令的跳轉(zhuǎn)條件是不相同的,需要一一判斷,本設(shè)計(jì)就巧妙的利用了ALU模塊來處理這個(gè)編碼,ALU模塊計(jì)算的時(shí)候也是需要對操作進(jìn)行判斷的,因此,只要添加一小段代碼就可以讓其完成發(fā)送編碼的功能;PC編碼的方式大大簡化了PC模塊的操作,使得程序更加規(guī)整;
3.4 雙向P端口的模擬
這里主要是P0和P2雙向端口的模擬;對于典型的單片機(jī),其P端口一般都是雙向的,但是對于FPGA設(shè)計(jì)來說,以現(xiàn)在的芯片結(jié)構(gòu),在FPGA芯片里面實(shí)現(xiàn)真正的雙向是不可能的,因此,作為軟核來說,雙向的模擬就一定要處理好;常用的解決辦法有這么幾種:一種是直接將雙向端口改成兩個(gè)單向的端口,這樣對于軟核來說使用更加方便,本設(shè)計(jì)也提供了這種方式供選擇,但是這樣就與標(biāo)準(zhǔn)的單片機(jī)不相同了,因此,本設(shè)計(jì)也提供了一種模擬的雙向口,根據(jù)FPGA設(shè)計(jì)的特點(diǎn),改變信號線的方向必須有個(gè)切換的過程,這樣就只好仔細(xì)的來分析指令時(shí)序,看看能不能在P端口使用的間隙來處理這個(gè)切換過程;首先是分析指令是否需要使用P端口,比較重要的控制信號有譯碼器發(fā)送的RD_LATCH信號,用來區(qū)分指令是否需要使用P端口,還有來自于CPU_CON的控制總線信息,用來告知P端口需要完成的具體功能;如果需要使用P端口的復(fù)用功能,則由相關(guān)的需要使用P端口的模塊(如串行口模塊)發(fā)送請求指令;然后P端口分析所有的使用請求,根據(jù)不同的使用方式來安排不同的使用情況;如果需要雙向切換,則根據(jù)時(shí)序以及指令特點(diǎn)來處理,從而順利完成雙向的切換過程。
4 綜合與驗(yàn)證
使用Altera公司的Quartus II 4.2軟件來綜合,使用Nios Development Board,Cyclone Edit開發(fā)板來進(jìn)行板上驗(yàn)證;綜合結(jié)果如下:
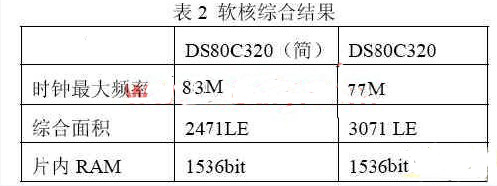
其中,前一個(gè)版本是沒有內(nèi)部串行口的版本;時(shí)序仿真驗(yàn)證的結(jié)果表明,在上述頻率下該系統(tǒng)可以穩(wěn)定的工作;理論上換算成8051的主頻為:83*2.5=207.5M,這基本上可以適應(yīng)絕大部分需要單片機(jī)控制的場合了;仿真測試主要使用了modelsim SE5.8以及quartus4.2的VWF文件測試;板上波形觀測主要使用Agilent公司的 1673G 邏輯分析儀;同時(shí)充分利用了開發(fā)板的資源進(jìn)行了大量的系統(tǒng)級測試;將程序下載到芯片里面,使用邏輯分析觀測到部分指令的執(zhí)行波形為:
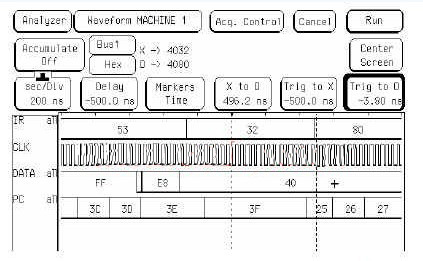
圖3 中斷指令波形圖
這是一條中斷返回指令的波形圖,指令代碼為32H,主要觀測PC的變化,PC在這條指令之后從3FH又變化為中斷發(fā)生前的地址25H。
5 結(jié)束語
本設(shè)計(jì)具有速度快,可裁減,具有良好的可重用性和可移植性,完全兼容DS80C320單片機(jī)接口,以及方便使用等優(yōu)點(diǎn)。尤其是專門構(gòu)造的內(nèi)部框架以及時(shí)序分配,使得其高速性能在目前的51系列軟核里面基本上是最前列的。因此,可以很方便的應(yīng)用于需要單片機(jī)軟核的FPGA設(shè)計(jì)以及嵌入式系統(tǒng)設(shè)計(jì)之中。