
引 言
圖像的編解碼技術(shù)是多媒體技術(shù)的關(guān)鍵,H.264/AVC是國際上最先進的視頻壓縮技術(shù),其主要特點是采用小尺寸整數(shù)余弦變換、1/4像素的運動估計精度、多參考幀預(yù)測,基于上下文可變長度編碼和環(huán)路內(nèi)去塊效應(yīng)濾波器等技術(shù)。由于去塊效應(yīng)濾波器大約占整個解碼器1/3的運算量,因此該部分的設(shè)計成為整個解碼器設(shè)計的瓶頸,在此研究了一種新穎的環(huán)路內(nèi)去塊效應(yīng)濾波器設(shè)計。設(shè)計中采用5階流水線的去塊效應(yīng)模塊,利用混合濾波順序與打亂的存儲更新機制的方法提高了流水線暢順性,濾波一個16×16大小的宏塊僅需要198個時鐘周期。
1 H.264/AVC的去塊效應(yīng)
在基于塊的視頻編碼方法中,各個塊的編解碼是互相獨立的,由于預(yù)測、補償、變化、量化等引起塊與塊之間的邊界處會產(chǎn)生不連續(xù),因此新版H.264/AVC標準采用了環(huán)路內(nèi)去塊濾波器來解決每個16×16宏塊重建后的邊界扭曲問題。去塊效應(yīng)濾波有兩種方法:后處理去塊效應(yīng)濾波;環(huán)路內(nèi)去塊效應(yīng)濾波。H.264/AVC采用環(huán)路內(nèi)去塊效應(yīng)濾波(見圖1),即濾波后的幀作為后面預(yù)測的參考幀。與之前的H.263或MPEG的濾波器相比較,新版H.264標準采用的濾波器基于更小的4×4的基本宏塊,基本宏塊的邊界根據(jù)片級/宏塊級的特性與根據(jù)像素穿過濾波邊界的漸變度,對需要濾波的宏塊邊界進行有條件的濾波。重建幀的每個像素都需要從外部存儲器中重調(diào)出來以進行濾波處理或作為相鄰像素來判斷當前像素是否需要進行濾波。顯然,這些操作需要消耗巨大的存儲器帶寬,對像素值進行修改。

本文設(shè)計的去塊效應(yīng)濾波模塊采用流水線技術(shù)來提高系統(tǒng)吞吐量。理想流水線的高效率實現(xiàn)基于相鄰的濾波操作沒有數(shù)據(jù)性。文獻[3,4]采用了非流水線的架構(gòu),因此無法提高系統(tǒng)的吞吐量。而對于流水線架構(gòu),如若不優(yōu)化濾波順序與存儲器訪問次序,則所產(chǎn)生的數(shù)據(jù)與結(jié)構(gòu)冒險也將大大降低流水線的效率。有人使用雙端口的片上SRAM來減少片外存儲器的帶寬,增加了系統(tǒng)的吞吐量,但是雙端口存儲器面積較大且增加功耗。與流水線的濾波器相比,非流水線濾波器的操作(包括條件判斷、查表、像素計算等)是順序化的,即每個時鐘僅處理一個操作類型,因此它所能達到的最大系統(tǒng)頻率要低很多。
采用不同的邊界濾波順序,會大大的影響去塊效應(yīng)濾波器的性能。在H.264/AVC標準中,每個宏塊的濾波順序得到了描述,只要保持濾波數(shù)據(jù)依賴性,H.264/AVC標準所描述的濾波順序可以被改進。其濾波順序包括兩類:順序濾波和混合濾波。但是其濾波順序以及相應(yīng)的存儲更新機制都是針對非流水線結(jié)構(gòu)的,因此如果直接將之應(yīng)用于本文的流水線設(shè)計,就有可能引發(fā)嚴重的競爭與冒險從而降低流水線的性能。
2 去塊效應(yīng)濾波器的存儲管理與濾波算法
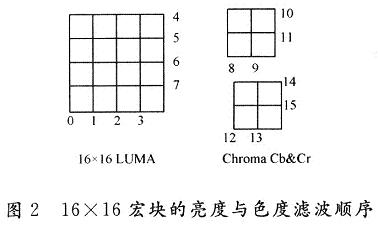
H.264/AvC標準基于4×4宏塊作為濾波的基本宏塊,它有5種濾波強度,分別是Bs=0,1,2,3,4。濾波方式分為強濾波、標準濾波和直通3種方式,其中強濾波影響邊界兩邊的共6個像素,標準濾波影響邊界兩邊的共4個像素,直通方式不修改邊界兩側(cè)的像素。H.264/AVC標準規(guī)定先對垂直邊界進行濾波,然后再對水平邊界進行濾波,只有對垂直與水平邊界全部濾波完成后,才可以對下一個宏塊進行濾波。同一個宏塊中,先對亮度部分進行濾波,再對色度部分進行濾波;色度部分濾波時,先對C6部分進行濾波,再對Cr部分進行濾波,對整個16×16宏塊的濾波順序如圖2所示。
(1)邊界濾波強度與像素濾波的存儲器
按照H.264/AVC的標準,需要對被濾波的邊界兩側(cè)的像素進行有條件的濾波。該條件決定于邊界強度BS與像素穿越邊界的傾斜度。邊界強度BS:0,1,2,3或4,在進行濾波之前被賦給相應(yīng)的邊界。BS=4表示強濾波,BS=0表示不需要進行濾波,即直通方式;否則,BS=1,2,3表示中等強度的濾波,色度部分邊界的濾波強度與對應(yīng)亮度部分是相同的。濾波每條水平或垂直邊界需要被提供邊界兩邊的8個像素,p0~p3&q0~q3;需要更新的像素共6個或4個:p0~p2&q0~q2或聲p0,p1&q0,q1。
對一個16×16宏塊進行濾波需要提供左邊相鄰像素、右邊相鄰像素和本宏塊的像素。對于宏塊邊界,比如最左邊界與最右邊界而言,p0~p3與q0~q3來自不同的模塊(即分別來自相鄰宏塊的像素與本宏塊的像素);對于非16×16宏塊的邊界濾波,像素p0~p3與q0~q3均來自16×16宏塊本身,因此至少需要4個存儲單元:左相鄰像素存儲單元、上相鄰像素存儲單元、本身模塊的像素存儲單元和轉(zhuǎn)換緩沖單元,每個存儲單元的帶寬是32位。
當濾波從垂直邊界向水平邊界變換時,為了方便濾波過程中的存儲器訪問,這里利用額外的轉(zhuǎn)換緩沖器BUF0~BUF3來緩存中間濾波數(shù)據(jù),采用轉(zhuǎn)換緩沖器后獲取一行或一列像素的值(即p0~p3&q0~q3)只需要1個時鐘周期,否則需要4個時鐘周期。
(2)濾波算法
環(huán)路濾波的基本思想是:判斷該邊界是圖像的真實邊界還是編碼所形成的塊效應(yīng)邊界;對真實邊界不濾波,對偽邊界根據(jù)像素穿越邊界的漸變度和編碼方式進行濾波;根據(jù)濾波強度,選擇不同的濾波系數(shù)對邊界兩側(cè)像素進行濾波操作。濾波強度Bs=0的邊界將不會進行濾波,而濾波強度Bs不為0的邊界,依賴于獲取的量化參數(shù)α與β,進行閾值判斷,對鄰近的像素進行有條件的濾波。當濾波強度Bs不是0,并且下面3個條件成立時,才對鄰近像素進行濾波。
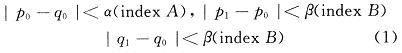
直接計算α,β是非常困難,而且消耗了很多硬件資源,因此通過查找表(LUT)獲取α,β的操作。像素的計算可以被分成下述兩種類型:
(1)Bs=4
如果以下的兩個條件成立,一個非常強的4抽頭或5抽頭濾波器將被用來對鄰近像素進行濾波,修改像素p0,p1,p2。

否則,若式(2)中有一個不成立,將不會對p1與p2進行濾波,只會對p0進行弱強度的濾波。對于色度部分邊界的濾波,如果式(2)成立,只會對p0與q0進行濾波。
(2)Bs=1~3
亮度像素p0與q0的計算如下:
![]()
而d_0是在裁減操作中被定義的:
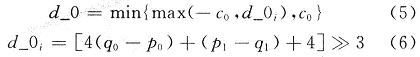
式中:c0來自于c1,而c1是通過查找兩維的LUT表獲取的。
像素p1僅在式(3)成立的時候進行修改,同p0與q0修改的方式相同;而像素p2與q2對于濾波強度Bs不為4的情況下,不進行濾波。在色度分量進行濾波時,只有對p0與q0進行濾波,濾波的方式與亮度濾波的方式相同。
3 流水線濾波架構(gòu)
3.1 流水線分析
流水線技術(shù)適合于連續(xù)的批處理任務(wù),當一個N階流水線被灌滿以后,系統(tǒng)在一個周期內(nèi)可以并行處理N個任務(wù),由此提高了整組任務(wù)的處理速度并增大了系統(tǒng)吞吐能力。如果相鄰的濾波操作沒有數(shù)據(jù)競爭,并且所有的階段都被很好地進行了平衡,則濾波過程能夠被進行流水線操作化并可將速度提高N倍數(shù)。然而,如若存在競爭與冒險問題,則無法實現(xiàn)。此時的主要任務(wù)是如何均衡流水線的各個階段,如何把總的操作盡可能平均的分配給不同的流水線階段,如何避免或消除競爭與冒險,以便獲得一個比較平衡暢順的流水線架構(gòu)。按照去塊效應(yīng)濾波器模塊的實現(xiàn)算法,大多數(shù)的關(guān)鍵路徑位于以下操作中。
(1)查找表操作:取得α,β,c1參數(shù)。α,β參數(shù)均需在查找表操作之前進行基于量化參數(shù)與片級偏移參數(shù)的計算中使用。當Bs=1,2,3時,為獲取c1進行LUT操作,該操作比獲取α,β的LUT操作大3倍。
(2)當Bs=4時,需用4或5抽頭的濾波器進行濾波,原來的p,q像素值需要進行移位、相加等操作,以得到最后的結(jié)果。
3.2 流水線架構(gòu)
基于上述分析,這里提出了5階流水線以提高吞吐量,見圖3。由于整個任務(wù)被分配到不同的階段實現(xiàn),降低濾波的平均時間。
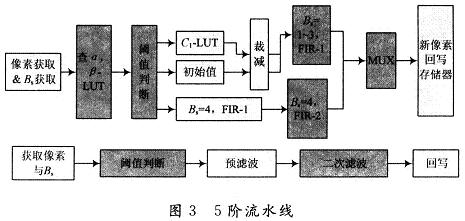
4 階流水線每個階段的任務(wù)
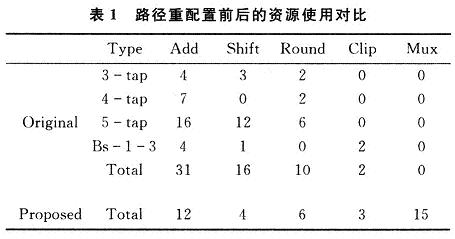
階流水線每個階段的任務(wù)為:獲取像素與濾波強度;閾值判斷;預(yù)濾波;二次濾波;回寫。操作類型轉(zhuǎn)換與可重新配置路徑設(shè)計:首先進行操作類型的變換,使用加法與移位操作硬件替換了原來所有的乘法與除法硬件。當Bs=4時,濾波被3,4,5抽頭的濾波器執(zhí)行,盡管應(yīng)用不同抽頭數(shù)目的濾波器,仍考慮硬件復用以及輸入數(shù)據(jù)路徑重新配置。由于設(shè)計中的表達式采用兩輸入加法,因而可以公用加法的中間結(jié)果。此外,通過重新配置在不同濾波抽頭系數(shù)時的加法器的輸入,達到共享資源的目的。同理,當Bs=1,2,3時,通過輸入路徑的重新配置,同樣達到共享加法與減法器,達到共享資源的目的,資源使用前后對比見表1。
5 流水線競爭與混合濾波順序
5.1 流水線競爭的原因
(1)數(shù)據(jù)競爭:當目的結(jié)果需要用作源操作數(shù)時;
(2)結(jié)構(gòu)競爭:由于有限的存儲器帶寬,大量而頻繁的像素訪問需要以及存儲器的低效率管理而引起;
(3)控制競爭:相鄰邊界的濾波是相對獨立的,當一條邊界進入它的流水線階段時,它不能夠停止,直到它的第5階段新像素值回寫存儲器操作結(jié)束。控制競爭,由于分支語句或延遲等待引起的。
5.2 一種新穎的混合濾波順序
傳統(tǒng)的設(shè)計按照H.264/AVC標準使用了基本的順序濾波,沒有考慮到相鄰濾波邊界的數(shù)據(jù)重用與數(shù)據(jù)相互依賴性以及存儲器的讀與寫訪問延時,因此這里提出了新穎的濾波方法。新穎的濾波順序仍然遵守先左后右,先上后下的原則,但是考慮了相鄰邊界的數(shù)據(jù)依賴性與重用性,解決了數(shù)據(jù)冒險與結(jié)構(gòu)冒險問題,避免了流水線的延遲。濾波包括亮度部分與色度部分,共48條邊界,濾波順序按照如圖4所示的從小到大的數(shù)字進行。

5.3 新穎的存儲更新策略
考慮到外部存儲器的帶寬是32位的,為了配合這里提出的邊界濾波順序,避免由于存儲器的帶寬限制而引起的結(jié)構(gòu)競爭從而導致流水線出現(xiàn)延遲,這里提出了新穎的存儲器更新機制,即給不同的4×4宏塊分配不同的時隙進行像素回寫。
去塊效應(yīng)模塊被分配在整個解碼模塊的最后一步實現(xiàn),而其它的重建步驟、像幀內(nèi)濾波模塊、幀間濾波模塊均以4×4宏塊為基本單位來進行流水線處理,但是由于去塊效應(yīng)濾波模塊中不同邊界之間的數(shù)據(jù)依賴關(guān)系,因而它是以整個16×16宏塊為基本單位進行濾波的。此外,只有整個16×16宏塊的像素重建完畢之后.才可以進行該宏塊的濾波,因而使用了2個SRAM,一個為像素重建提供像素;另一個為像素濾波提供像素,當一個宏塊被處理完畢,兩個SRAM交換角色,這樣避免在兩個SRAM之間傳遞數(shù)據(jù)導致的時間與功耗開銷。使用仿真工具對整個去塊效應(yīng)頂層模塊DF_top進行了仿真,仿真部分結(jié)果如圖5所示。

6 結(jié) 語
使用硬件描述語言完成了設(shè)計,并在FPGA平臺上得到驗證。設(shè)計采用流水線技術(shù),混合濾波方法,配合新穎的存儲器更新機制等方案,實時濾波頻率上限約為200 MHz,吞吐量為濾波每個16×16宏塊需要198個時鐘周期。使用HJTC,CMOS工藝,使用Syn-opsys Co.的DC工具進行綜合,時序分析以及功耗分析,結(jié)論是時序滿足收斂要求,并且完成單個宏塊的濾波消耗的能量大約為2μW,功耗得到了很大的降低。