
摘 要: 為了使VTL(虛擬磁帶庫(kù))系統(tǒng)能更有效地利用磁盤(pán)空間,存儲(chǔ)更多的數(shù)據(jù)信息,,介紹了一種帶有重復(fù)數(shù)據(jù)刪除算法的虛擬磁帶庫(kù)應(yīng)用方法,。該方法從性能和效率等多方面考慮,首先把磁帶按文件級(jí)去重,,再將文件切分成塊,,通過(guò)Bloom Filter和MD5算法雙重計(jì)算,經(jīng)查找和存儲(chǔ)實(shí)現(xiàn)數(shù)據(jù)塊級(jí)的重復(fù)刪除,。實(shí)驗(yàn)測(cè)試證明,,該方案穩(wěn)定地實(shí)現(xiàn)了數(shù)據(jù)的去重及加密功能,能有效節(jié)省虛擬磁帶庫(kù)的存儲(chǔ)空間,。
關(guān)鍵詞: 虛擬磁帶庫(kù),;重復(fù)數(shù)據(jù)刪除;Bloom filter,;MD5
進(jìn)入21世紀(jì)以來(lái),,在科技飛速發(fā)展的同時(shí),數(shù)據(jù)信息的產(chǎn)生也在急劇增長(zhǎng),。據(jù)悉,,企業(yè)的數(shù)據(jù)量平均年度增長(zhǎng)率為50%左右,部分?jǐn)?shù)據(jù)的冗余率卻在60%以上,。這使得備份時(shí)需消耗大量的時(shí)間和空間去存儲(chǔ)重復(fù)的數(shù)據(jù),,資源浪費(fèi)十分嚴(yán)重。為了實(shí)時(shí)存儲(chǔ)大量有效的信息,,針對(duì)物理磁帶庫(kù)存儲(chǔ)容量小和效率低等不足,,人們引進(jìn)了虛擬磁帶庫(kù)技術(shù),將高速磁盤(pán)陣列仿真成磁帶格式,,節(jié)省了磁帶機(jī)上帶,、定位、退帶等機(jī)械動(dòng)作時(shí)間,,同時(shí)無(wú)需擔(dān)心機(jī)械手故障,、磁頭耗損或磁帶受潮等問(wèn)題。節(jié)省成本的同時(shí)提高了備份和恢復(fù)速度,,實(shí)現(xiàn)了實(shí)時(shí)有效地存儲(chǔ)海量數(shù)據(jù)信息,。
盡管虛擬磁帶庫(kù)在應(yīng)對(duì)數(shù)據(jù)存儲(chǔ)時(shí)發(fā)揮了巨大作用,但是仍不能滿(mǎn)足市場(chǎng)需求。如何對(duì)存儲(chǔ)在虛擬磁帶庫(kù)系統(tǒng)中的數(shù)據(jù)進(jìn)行重新壓縮從而更有效地利用存儲(chǔ)空間,,便成為了如今研究的熱門(mén)課題,。而重復(fù)數(shù)據(jù)刪除技術(shù)作為目前企業(yè)熱捧的技術(shù)之一,在數(shù)據(jù)壓縮處理和存儲(chǔ)領(lǐng)域具有很大的應(yīng)用空間,。本文提出了重復(fù)數(shù)據(jù)刪除算法在虛擬磁帶庫(kù)系統(tǒng)中的一種應(yīng)用方案,。
1 相關(guān)概念和算法介紹
1.1 重復(fù)數(shù)據(jù)刪除算法
重復(fù)數(shù)據(jù)刪除算法又名智能壓縮算法,是一種通過(guò)消除冗余重復(fù)數(shù)據(jù)減少存儲(chǔ)需求的方法,。
重復(fù)數(shù)據(jù)刪除算法有多種分類(lèi)方法,。按照重復(fù)內(nèi)容識(shí)別方法分類(lèi)可分為三種:基于內(nèi)容散列識(shí)別、基于內(nèi)容識(shí)別和基于Hyper-factor識(shí)別,;而基于消除冗余執(zhí)行次序的分類(lèi)則可以分為在線(xiàn)式消冗和后處理式消冗兩種,;基于去重粒度分類(lèi)可分為文件級(jí)、數(shù)據(jù)塊級(jí)和字節(jié)級(jí)消冗三種[1],。本文在虛擬磁帶庫(kù)系統(tǒng)的應(yīng)用主要采用基于散列識(shí)別方法的數(shù)據(jù)塊級(jí)后處理式消冗方案,。
1.2 數(shù)據(jù)分塊算法
基于數(shù)據(jù)塊級(jí)的分塊算法主要有定長(zhǎng)切分、CDC切分和滑動(dòng)塊切分三種[2],。
定長(zhǎng)分塊算法(Fixed-Size Partition)主要采用預(yù)先分配好的塊對(duì)文件進(jìn)行切分,,并計(jì)算弱校驗(yàn)值和MD5強(qiáng)校驗(yàn)值。該算法的優(yōu)點(diǎn)是簡(jiǎn)單,、性能高,,但它對(duì)數(shù)據(jù)插入和刪除非常敏感,處理十分低效,,不能根據(jù)內(nèi)容變化作調(diào)整和優(yōu)化,。
CDC(Content-Defined Chunking)算法是一種變長(zhǎng)分塊算法,它應(yīng)用數(shù)據(jù)指紋將文件分割成長(zhǎng)度大小不等的分塊,。CDC算法對(duì)文件內(nèi)容變化不敏感,,插入或刪除數(shù)據(jù)只會(huì)影響到較少的數(shù)據(jù)塊,其余數(shù)據(jù)塊則不受影響,。該算法也有缺陷,,數(shù)據(jù)塊大小的確定比較困難。
滑動(dòng)塊(Sliding Block)算法結(jié)合了定長(zhǎng)切分和CDC切分的優(yōu)點(diǎn),,數(shù)據(jù)塊大小固定,。它對(duì)定長(zhǎng)數(shù)據(jù)塊先計(jì)算弱校驗(yàn)值,如果匹配則再計(jì)算MD5強(qiáng)校驗(yàn)值,,兩者都匹配則認(rèn)為是一個(gè)數(shù)據(jù)塊邊界,。該數(shù)據(jù)塊前面的數(shù)據(jù)碎片也是不定長(zhǎng)的數(shù)據(jù)塊。如果滑動(dòng)窗口移過(guò)一個(gè)塊大小的距離仍無(wú)法匹配,,則認(rèn)定其為一個(gè)數(shù)據(jù)塊邊界,?;瑒?dòng)塊算法對(duì)插入和刪除問(wèn)題的處理非常高效,并且能夠檢測(cè)到比CDC更多的冗余數(shù)據(jù),,但它容易產(chǎn)生數(shù)據(jù)碎片。
1.3 哈希查找和存儲(chǔ)算法
1.3.1 MD5算法
MD5算法即消息摘要算法第5版,,由MIT計(jì)算機(jī)科學(xué)實(shí)驗(yàn)室和RSA數(shù)碼保安公司聯(lián)合開(kāi)發(fā),,經(jīng)MD2、MD3和MD4延伸而來(lái)[3],。它將文件的任意一段內(nèi)容通過(guò)一系列算法壓縮成一段128 bit的信息摘要(哈希值),。其本質(zhì)即為一種哈希函數(shù),具有單向性,、抗弱碰撞性和抗強(qiáng)碰撞性等特點(diǎn),。
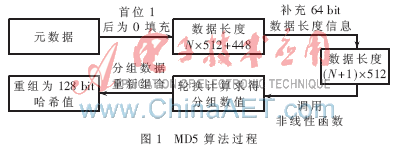
在MD5算法操作中,先對(duì)元數(shù)據(jù)信息進(jìn)行填充,,使得其字節(jié)長(zhǎng)度對(duì)512求余結(jié)果為448,;接著填充64 bit數(shù)據(jù)段長(zhǎng)度信息,湊齊為512的整數(shù)倍,;然后用4個(gè)固定的鏈接變量作為參數(shù)對(duì)MD緩沖器進(jìn)行初始化,;最后用4種不同的非線(xiàn)性函數(shù)進(jìn)行輪換計(jì)算,結(jié)果輸出4個(gè)32 bit即128 bit的哈希值[4-5],。算法過(guò)程如圖1所示,。
1.3.2 Bloom Filter算法
Bloom Filter由Howard Bloom在1970年提出。它利用位數(shù)組很簡(jiǎn)潔地表示一個(gè)集合,,并能通過(guò)一組哈希映射函數(shù)判斷一個(gè)元素是否屬于這個(gè)集合,。該算法具有很好的空間效率和時(shí)間效率,但是卻有一定的誤識(shí)別率(假陽(yáng)性誤判),,并且刪除操作比較困難,。
該算法主要包括數(shù)據(jù)元素的查找和插入兩部分。在查找操作中,,首先將目標(biāo)信息存儲(chǔ)到一個(gè)集合S中,,接著設(shè)計(jì)多個(gè)相互獨(dú)立的哈希函數(shù)及適度大小的哈希表,并設(shè)其初始值全為0,。在集合S中任取一個(gè)元素,,經(jīng)哈希函數(shù)分別映射到哈希表中。如果所對(duì)應(yīng)哈希表位置的值都為1,,則說(shuō)明該元素可能已經(jīng)存在,,但也有誤判的可能。若有任意其中一個(gè)位置不為1,,則說(shuō)明該元素必不存在,。同樣插入操作經(jīng)哈希函數(shù)計(jì)算并映射后,,把相應(yīng)位置的值都置為1。
2 方案設(shè)計(jì)及實(shí)現(xiàn)
2.1 應(yīng)用場(chǎng)景
圖2所示為常見(jiàn)的一種應(yīng)用虛擬磁帶庫(kù)進(jìn)行數(shù)據(jù)備份的場(chǎng)景,。各個(gè)客戶(hù)端所產(chǎn)生的數(shù)據(jù)通過(guò)網(wǎng)絡(luò)傳送到服務(wù)器端,,在服務(wù)器中備份軟件的操作下,將數(shù)據(jù)備份到虛擬磁帶庫(kù)所模擬成磁帶格式的磁盤(pán)陣列中,,該磁盤(pán)陣列由相應(yīng)的RAID組構(gòu)成,,從而進(jìn)行容災(zāi)保護(hù)。該數(shù)據(jù)可以實(shí)時(shí)導(dǎo)入,、導(dǎo)出到相應(yīng)的物理磁帶庫(kù)中,。同樣,數(shù)據(jù)流的逆向即可實(shí)現(xiàn)數(shù)據(jù)恢復(fù)作業(yè),。在虛擬磁帶庫(kù)系統(tǒng)中可以對(duì)所備份的數(shù)據(jù)進(jìn)行重新掃描和重復(fù)數(shù)據(jù)刪除,,并存儲(chǔ)壓縮后的數(shù)據(jù),選擇是否刪除原有數(shù)據(jù),,進(jìn)而節(jié)省大量的磁盤(pán)空間,。

2.2 系統(tǒng)結(jié)構(gòu)設(shè)計(jì)
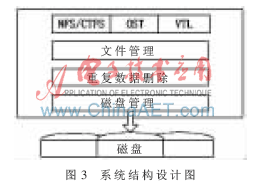
帶有重復(fù)數(shù)據(jù)刪除功能的虛擬磁帶庫(kù)系統(tǒng)結(jié)構(gòu)設(shè)計(jì)如圖3所示。上層為包含有支持NFS/CIFS,、OST及VTL等文件協(xié)議的文件協(xié)議讀取層,,該層將存儲(chǔ)子系統(tǒng)進(jìn)行網(wǎng)絡(luò)化,實(shí)現(xiàn)存儲(chǔ)內(nèi)容的高速共享訪(fǎng)問(wèn),。下一層為文件管理層,,該層主要實(shí)現(xiàn)對(duì)數(shù)據(jù)存放文件及命名空間的管理和設(shè)置。文件管理層下面為重復(fù)數(shù)據(jù)刪除模塊,,主要對(duì)搜尋到的數(shù)據(jù)文件進(jìn)行分塊處理,、哈希計(jì)算和查找并歸類(lèi)存儲(chǔ)等操作。下一層為磁盤(pán)管理模塊,,主要負(fù)責(zé)對(duì)磁盤(pán)陣列數(shù)據(jù)元數(shù)據(jù)和哈希值的分類(lèi)存放和獲取,,以及磁盤(pán)訪(fǎng)問(wèn)順序的優(yōu)化處理等。
2.3 重復(fù)數(shù)據(jù)刪除功能詳細(xì)設(shè)計(jì)
為實(shí)現(xiàn)文件中重復(fù)數(shù)據(jù)的刪除功能,,本文進(jìn)行了如圖4所示的詳細(xì)設(shè)計(jì),。首先該模塊對(duì)虛擬磁帶庫(kù)中需處理的磁帶文件進(jìn)行查找和獲取,然后計(jì)算出相應(yīng)的哈希值,,先用Bloom Filter 算法進(jìn)行快速計(jì)算和查找,,如果位數(shù)組A中已存在相關(guān)的文件,則再次進(jìn)行MD5算法計(jì)算和查找,,如果位數(shù)組A中的確存在該文件,,則只存儲(chǔ)該文件相關(guān)哈希值,接著進(jìn)行下個(gè)文件的處理,。如果在Bloom Filter算法的位數(shù)組A中不存在該數(shù)據(jù)的信息,,則進(jìn)行添加和更新,,接著完成對(duì)該文件哈希值的存儲(chǔ),然后對(duì)該文件進(jìn)行數(shù)據(jù)塊級(jí)的處理,。由于在Bloom Filter中可能出現(xiàn)誤判,,故而當(dāng)MD5再次校驗(yàn)不存在時(shí),同樣也會(huì)進(jìn)入數(shù)據(jù)塊級(jí)處理中,。
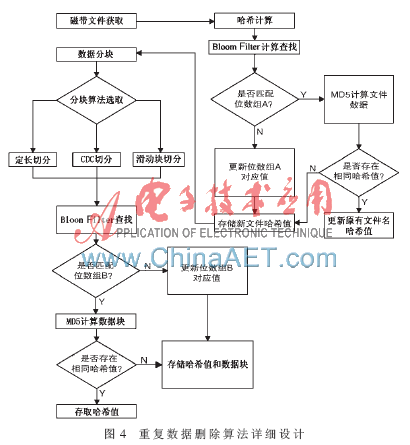
本文應(yīng)用可以根據(jù)需要選擇定長(zhǎng),、CDC、滑動(dòng)塊任意一種切分方式來(lái)進(jìn)行數(shù)據(jù)塊劃分,。接著對(duì)所切分的數(shù)據(jù)塊進(jìn)行如同文件級(jí)別的Bloom Filter和MD5雙重驗(yàn)證。首先對(duì)數(shù)據(jù)塊進(jìn)行Bloom Filter計(jì)算,,當(dāng)結(jié)果不匹配位數(shù)組B中相關(guān)位時(shí),,則表明該數(shù)據(jù)塊必不存在,對(duì)位數(shù)組中相關(guān)位進(jìn)行插入和更新,,并分別存儲(chǔ)該數(shù)據(jù)塊和相關(guān)的哈希值,;如果該數(shù)據(jù)塊匹配該位數(shù)組B時(shí),則再次進(jìn)行MD5計(jì)算和校驗(yàn),。如果仍然匹配,,則說(shuō)明該數(shù)據(jù)塊重復(fù),只存儲(chǔ)該數(shù)據(jù)塊的哈希值,;如果出現(xiàn)不匹配情況,,則說(shuō)明前面計(jì)算出現(xiàn)誤判,分別存儲(chǔ)該數(shù)據(jù)塊和相應(yīng)的哈希值,。
數(shù)據(jù)塊及相應(yīng)哈希值存儲(chǔ)及檢索如圖5所示,。當(dāng)文件A進(jìn)入計(jì)算時(shí),會(huì)生成相應(yīng)哈希值并指向?qū)?yīng)數(shù)據(jù)塊,。當(dāng)首次查找數(shù)據(jù)塊N不存在時(shí),,則先存入數(shù)據(jù)塊,然后再把數(shù)據(jù)塊N的索引指向該數(shù)據(jù)塊所在位置,,當(dāng)再次查找時(shí),,僅存儲(chǔ)對(duì)應(yīng)哈希值。文件A檢索完畢后同樣對(duì)文件B進(jìn)行相關(guān)操作,。而當(dāng)A’經(jīng)計(jì)算與文件A內(nèi)容相同時(shí),,則文件A’的索引會(huì)指向文件A的索引,當(dāng)文件A’數(shù)據(jù)恢復(fù)時(shí),,通過(guò)指引直接檢索調(diào)用文件A中的索引值,,從而進(jìn)一步加快效率,節(jié)省存儲(chǔ)空間,。

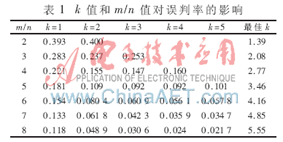
若使f≤0.01,,則需m≥9.567n,,此時(shí)取k=7[6]。表1中所示數(shù)據(jù)可獲得不同k值和m/n下對(duì)應(yīng)的誤判率的大小以及m/n固定時(shí)取得最小誤判率的最佳k值,。

實(shí)驗(yàn)中采用分塊大小為4 KB,,共對(duì)5組大小及內(nèi)容不同的文件進(jìn)行了數(shù)據(jù)的重復(fù)刪除處理。由表2可知,,文件1中TXT文件和文件3中PDF文件存在相當(dāng)數(shù)量的重復(fù)塊,;而照片、音頻和視頻等文件存在較少重復(fù)數(shù)據(jù)塊,。由于測(cè)試環(huán)境限制,,本次測(cè)試的子文件都不相同,且數(shù)據(jù)量小,,所以重刪率較低,,甚至出現(xiàn)小于1的情況。不過(guò)數(shù)據(jù)經(jīng)還原處理后,,與原始數(shù)據(jù)相比完全相同,,安全性能有保障,當(dāng)出現(xiàn)大量重復(fù)文件時(shí),,效果更好,。
本文主要介紹了一種重復(fù)數(shù)據(jù)刪除算法在虛擬磁帶庫(kù)系統(tǒng)中的應(yīng)用方法。該應(yīng)用采用后處理式的數(shù)據(jù)分塊哈希計(jì)算方法來(lái)進(jìn)行數(shù)據(jù)的重復(fù)刪除,。數(shù)據(jù)分塊可選擇使用任一種常用的3種分塊方法,,數(shù)據(jù)查找和存儲(chǔ)采用Bloom Filter和MD5算法雙重計(jì)算,經(jīng)過(guò)設(shè)置參數(shù)有效地降低了Bloom Filter的誤判率和MD5算法的碰撞率,。有效提高了存儲(chǔ)的時(shí)間效率和空間效率,,并獲得良好的重刪率,同時(shí)完成了數(shù)據(jù)的壓縮和加密雙重功能,。
參考文獻(xiàn)
[1] 付印芳,,肖儂,劉芳.重復(fù)數(shù)據(jù)刪除關(guān)鍵技術(shù)研究進(jìn)展[J].計(jì)算機(jī)研究與發(fā)展,,2012,,49(1):12-20.
[2] 敖莉,舒繼武,,李明強(qiáng).重復(fù)數(shù)據(jù)刪除技術(shù)[J].軟件學(xué)報(bào),,2010,21(5):916-929.
[3] RIVEST R.The MD5 message digest algorithm[M].RFC 1321,,1992.
[4] 陳少暉,,翟曉寧,閻娜,,等.MD5算法破譯過(guò)程解析[J].計(jì)算機(jī)工程與應(yīng)用,,2010,,46(19):109-112.
[5] 張裔智,趙毅,,湯小斌.MD5算法研究[J].計(jì)算機(jī)科學(xué),,2008,35(7):295-297.
[6] HOROWITZ E,,SAHNI S,,MEHTA D.Fundamentals of data structures in C++[M].Computer Science Press,1995.