
1 引言
從20世紀(jì)50年代開始對(duì)語音識(shí)別的研究開始,經(jīng)過幾十年的發(fā)展已經(jīng)達(dá)到一定的高度,有的已經(jīng)從實(shí)驗(yàn)室走向市場(chǎng),如一些玩具、某些部門密碼語音輸入等,隨著DSP和專用集成電路技術(shù)的發(fā)展,快速傅立葉變換以及近來嵌入式操作系統(tǒng)的研究,使得特定人識(shí)別尤其是計(jì)算量小的特定人識(shí)別成為可能。因此,對(duì)特定人語音識(shí)別技術(shù)在汽車控制上的應(yīng)用的研究是很有前途的。
2 特定人語音識(shí)別的方法
目前,常用的說話人識(shí)別方法有模板匹配法、統(tǒng)計(jì)建模法、聯(lián)接主義法(即人工神經(jīng)網(wǎng)絡(luò)實(shí)現(xiàn))。考慮到數(shù)據(jù)量、實(shí)時(shí)性以及識(shí)別率的問題,筆者采用基于矢量量化和隱馬爾可夫模型(HMM)相結(jié)合的方法。
說話人識(shí)別的系統(tǒng)主要由語音特征矢量提取單元(前端處理)、訓(xùn)練單元、識(shí)別單元和后處理單元組成,其系統(tǒng)構(gòu)成如圖1所示。
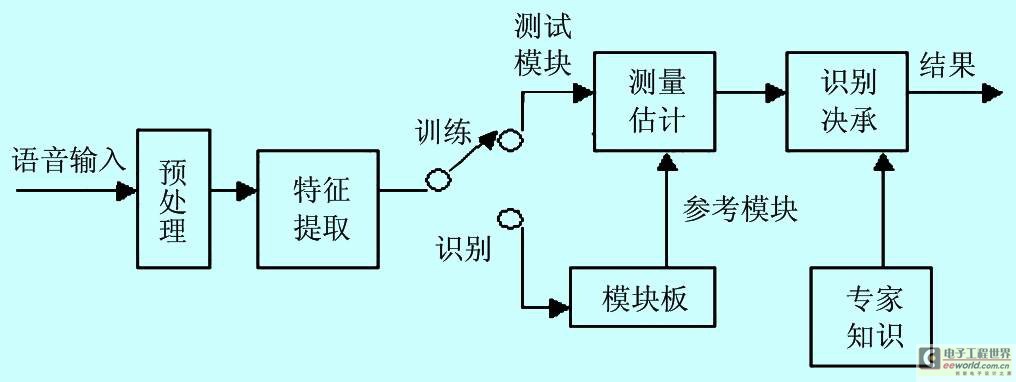
圖1系統(tǒng)構(gòu)成
由上圖也可以看出,每個(gè)司機(jī)在購(gòu)買車后必須將自己的語音輸入系統(tǒng),也就是訓(xùn)練過程,當(dāng)然最好是在安靜、次數(shù)達(dá)到一定的數(shù)目。從此在以后駕駛過程中就可以利用這個(gè)系統(tǒng)了。
所謂預(yù)處理是指對(duì)語音信號(hào)的特殊處理:預(yù)加重,分幀處理。預(yù)加重的目的是提升高頻部分,使信號(hào)的頻譜變得平坦,以便于進(jìn)行頻譜分析或聲道參數(shù)分析。用具有 6dB/倍頻程的提升高頻特性的預(yù)加重?cái)?shù)字濾波器實(shí)現(xiàn)。雖然語音信號(hào)是非平穩(wěn)時(shí)變的,但是可以認(rèn)為是局部短時(shí)平穩(wěn)。故語音信號(hào)分析常分段或分幀來處理。
2.1 語音特征矢量提取單元
說話人識(shí)別系統(tǒng)設(shè)計(jì)中的根本問題是如何從語音信號(hào)中提取表征人的基本特征。即語音特征矢量的提取是整個(gè)說話人識(shí)別系統(tǒng)的基礎(chǔ),對(duì)說話人識(shí)別的錯(cuò)誤拒絕率和錯(cuò)誤接受率有著極其重要的影響。同語音識(shí)別不同,說話人識(shí)別利用的是語音信號(hào)中的說話人信息,而不考慮語音中的字詞意思,它強(qiáng)調(diào)說話人的個(gè)性。因此,單一的語音特征矢量很難提高識(shí)別率。該系統(tǒng)在說話人的識(shí)別中采用倒譜系數(shù)加基因周期參數(shù),而在對(duì)控制命令的語音識(shí)別中僅采用倒譜系數(shù)。其中,常用的倒譜系數(shù)有2 種,即LPC(線性預(yù)測(cè)系數(shù))和倒譜參數(shù)(LPCC),一種是基于Mel刻度的MFLL(頻率倒譜系數(shù))參數(shù)(Mel頻率譜系數(shù))。
對(duì)于LPCC參數(shù)的提取, 可先采用Durbin遞推算法、格型算法或者Schur遞推算法來求LPC系數(shù),然后求LPC參數(shù)。設(shè)第l幀語音的LPC系數(shù)為αn,則LPCC的參數(shù)為![]() 1<n≤p
1<n≤p
其中p為L(zhǎng)PCC系數(shù)的階數(shù),k為L(zhǎng)PCC系數(shù)的遞推次數(shù)。
進(jìn)一步的研究發(fā)現(xiàn),引入一階和二階差分倒譜可以提高識(shí)別率。
對(duì)于MPCC參數(shù)的提取,若根據(jù)Mel曲線將語音信號(hào)頻譜分為K個(gè)頻帶,每個(gè)頻帶的能量為θ(Mk),則 MFCC參數(shù)為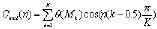 1<n≤p
1<n≤p
通過對(duì)LPCC和MFCC參數(shù)對(duì)識(shí)別率影響的實(shí)驗(yàn)比較,筆者選取LPCC參數(shù)及其一階和二階差分倒譜稀疏作為特征參數(shù)。
基音周期估計(jì)的方法很多,主要有基于求短時(shí)自相關(guān)函數(shù)的算法、基于求短時(shí)平均幅度差函數(shù)(AMDF)的算法、基于同態(tài)信號(hào)處理和線性預(yù)測(cè)編碼的算法。筆者僅介紹基于求短時(shí)自相關(guān)函數(shù)的算法。
設(shè)Sw(n)是一段加窗語音信號(hào),它的非零區(qū)間為0<n≤n-1。Sw(n)的自相關(guān)函數(shù)稱為語音信號(hào)的S(n)的短時(shí)自相關(guān)函數(shù),用Rw(l)表示,即Rw(l)= 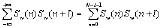 可知短時(shí)自相關(guān)函數(shù)在Rw(0)處最大,且在基音周期的各個(gè)整數(shù)倍點(diǎn)上有很大的峰值,選擇合適的窗函數(shù)(窗長(zhǎng)為40ms的Hamming窗)與濾波器(帶寬為60~900Hz的帶通濾波器)后,只要找到自相關(guān)函數(shù)的第一最大峰值點(diǎn)的位置并計(jì)算它與零點(diǎn)的距離,便能估計(jì)出基音周期。
可知短時(shí)自相關(guān)函數(shù)在Rw(0)處最大,且在基音周期的各個(gè)整數(shù)倍點(diǎn)上有很大的峰值,選擇合適的窗函數(shù)(窗長(zhǎng)為40ms的Hamming窗)與濾波器(帶寬為60~900Hz的帶通濾波器)后,只要找到自相關(guān)函數(shù)的第一最大峰值點(diǎn)的位置并計(jì)算它與零點(diǎn)的距離,便能估計(jì)出基音周期。
2.2 訓(xùn)練單元
訓(xùn)練單元的功能是把事先收集到的語音利用一定的算法為每一個(gè)待識(shí)別的說話人訓(xùn)練出與之相匹配的參數(shù)。針對(duì)說話人識(shí)別在汽車應(yīng)用中的不同的要求,訓(xùn)練單元也分為2部分:對(duì)說話人識(shí)別的訓(xùn)練和對(duì)待識(shí)別詞的訓(xùn)練。
對(duì)于說話人識(shí)別部分的訓(xùn)練, 針對(duì)說話人的特征進(jìn)行訓(xùn)練,為每個(gè)合法用戶建立一套或多套HMM模型,同時(shí)采用基于矢量量化(VQ)的方法,為每個(gè)合法用戶建立VQ碼本。VQ碼本的設(shè)計(jì)采用LBG算法,初始碼本的設(shè)置采用分裂法初始碼本。
第2 部分針對(duì)控制命令中用到的每個(gè)孤立的詞條建立多個(gè)訓(xùn)練樣本,或稱為詞條樣本,估計(jì)出該詞條的HMM參數(shù)(一套或多套)。對(duì)一個(gè)HMM過程的完整的描述包括:2個(gè)模型參數(shù)N和M,3組概率度量A,B和π。為了方便起見,通常采用如下方式表示一個(gè)完整的模型:λ=(N,M,π,A,B),或者簡(jiǎn)寫為:λ= (π,A,B)。而對(duì)于每一個(gè)詞條V的模型參數(shù) ,V=1~V,可以用Baum-Welch重估算法。
,V=1~V,可以用Baum-Welch重估算法。
2.3 識(shí)別單元
識(shí)別單元的功能是利用經(jīng)訓(xùn)練已經(jīng)獲得的HMM模型參數(shù) 和測(cè)得的說話人的基音周期在一定的判決條件下辨認(rèn)出待識(shí)別的說話人并估計(jì)出待識(shí)別的控制命令詞串。針對(duì)HMM模型參數(shù)通常采用的判決條件是最大后驗(yàn)概率,用Viterbi算法實(shí)現(xiàn)。
2.4 后處理單元
充分利用每個(gè)說話人的聲道參數(shù)和詞條中各狀態(tài)持續(xù)時(shí)間的概率分布來改進(jìn)系統(tǒng)的識(shí)別率。
3 系統(tǒng)的實(shí)現(xiàn)
由于汽車的控制命令是有限的詞條和數(shù)字串的組合, 對(duì)這些語音命令的識(shí)別屬于特定人小詞匯量的連接詞的識(shí)別以及與文本有關(guān)的說話人確認(rèn),不論是從目前的DSP運(yùn)算速度還是存儲(chǔ)空間來說,實(shí)時(shí)實(shí)現(xiàn)這些語音命令的識(shí)別都是完全可能的。
識(shí)別系統(tǒng)組成框圖如圖所示:在此系統(tǒng)中,對(duì)運(yùn)算能力和存儲(chǔ)單元要求非常高的語音識(shí)別部分完全由DSP完成。
框圖中識(shí)別系統(tǒng)的功能是完成語音的輸入、A/D轉(zhuǎn)換及識(shí)別,系統(tǒng)中核心部分采用TMS320VC5410。其原因是它的運(yùn)算速度和存儲(chǔ)空間都能滿足要求,同時(shí)它的一些并行運(yùn)算硬件結(jié)構(gòu)也非常適合語音識(shí)別的各種算法,程序和已經(jīng)脫機(jī)訓(xùn)練好的HMM參數(shù)表及相應(yīng)的詞典存放在程序存儲(chǔ)器中,數(shù)據(jù)存儲(chǔ)器存放識(shí)別過程中的中間計(jì)算數(shù)據(jù)。A/D芯片采用TLC320AD50C, 里面含有A/D、D/A以及低通濾波器和采樣保持電路。模擬語音信號(hào)的輸入主要是通過傳聲器,保證語音門禁的安全性,轉(zhuǎn)換后的數(shù)字語音數(shù)據(jù)以同步串行通信方式傳送給DSP。如圖2。
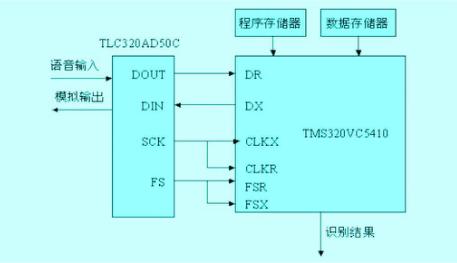
圖2 識(shí)別系統(tǒng)的組成框圖
4 結(jié)束語
語音控制汽車是未來的一種趨勢(shì)。目前,將語音技術(shù)應(yīng)用于汽車的產(chǎn)品只有在一些玩具中用到,由此可想利用語音技術(shù)進(jìn)行汽車控制這一領(lǐng)域蘊(yùn)涵著相當(dāng)大的潛在市場(chǎng)。
而且,說話人識(shí)別技術(shù)已經(jīng)發(fā)展到可以應(yīng)用到實(shí)際的階段了,但目前對(duì)說話人識(shí)別的應(yīng)用并不是很多。筆者嘗試提出一種比較容易實(shí)現(xiàn)的方案,將說話人識(shí)別技術(shù)應(yīng)用到實(shí)際中。但在實(shí)際應(yīng)用中,說話人識(shí)別系統(tǒng)都面臨一個(gè)共同的問題,即無法區(qū)分一個(gè)發(fā)音是現(xiàn)場(chǎng)發(fā)音還是錄音回放。針對(duì)該現(xiàn)象,筆者提出的說話人識(shí)別系統(tǒng)可以有效地防止這種情況發(fā)生。具體實(shí)現(xiàn)說話人識(shí)別系統(tǒng)時(shí),可采用隨機(jī)或其它方法來生成提示文本。如隨機(jī)的數(shù)字串,以使假冒者無法事先錄音,增加駕駛的安全性。