
我在NVIDIA研究深度學習已達四年之久,作為一名解決方案架構師,專門研究深度學習相關技術,為客戶提供可能的解決方案,并加以實施。
在我加入NVIDIA時,人工智能已經成為一個非常普遍的應用術語,但經常被模棱兩可的使用,甚至錯誤的被描述為深度學習和機器學習。我想從一些簡單的定義出發(fā),去一步步深入解讀其中含義,不足之處,以及采用新構架創(chuàng)建更完整能力“AI”的一些步驟。
機器學習——將函數(shù)與數(shù)據(jù)進行擬合,并使用這些函數(shù)對數(shù)據(jù)進行分組或對未來數(shù)據(jù)進行預測。(抱歉,我大大簡化了概念。)

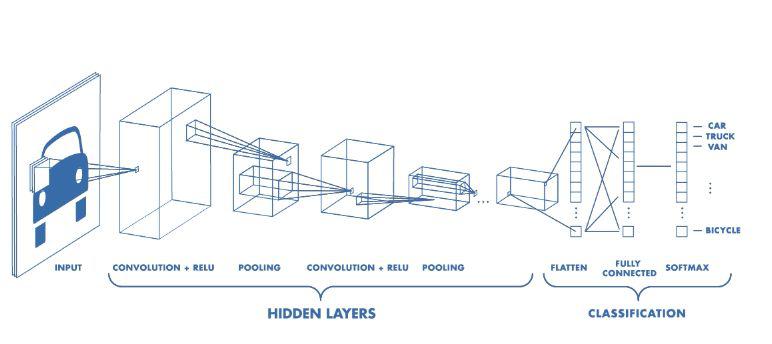
深度學習——將函數(shù)與數(shù)據(jù)進行擬合,如下圖所示,函數(shù)就是節(jié)點層,用于和前后節(jié)點相連,其中擬合的參數(shù)是這些連接節(jié)點的權重。
深度學習就是如今經常被成為AI的概念,但實際上只是非常精細的模式識別和統(tǒng)計建模。最常見的技術/算法是卷積神經網(wǎng)絡(CNNs)、遞歸神經網(wǎng)絡(RNNs)和強化學習(RL)。
卷積神經網(wǎng)絡(CNNs)具有分層結構,通過(訓練過的)卷積濾波器將圖像采樣到一個低分辨率的映射中,該映射表示每個點上卷積運算的值。從圖像中來看,它是從高分辨像素到特征(邊緣、圓形、……),再到粗糙特征(臉上的鼻子、眼睛、嘴唇……),然后再到能夠識別圖像內容的完整連接層。CNNs很酷的一點是,其卷積濾波器是隨機初始化的,當你訓練網(wǎng)絡時,你實際是在訓練卷積濾波器。幾十年來,計算機視覺研究人員一直在手工制作類似的濾波器,但無法像CNNs那樣的精準結果。此外,CNN的輸出可以是2D圖而不是單個值,從而為我們提供圖像分割。CNNs還可以用于許多其他類型的1D、2D甚至3D數(shù)據(jù)。
遞歸神經網(wǎng)絡(RNN)適用于順序或時間序列數(shù)據(jù)。基本上,RNN中的每個“神經”節(jié)點都是存儲門,通常是LSTM(長短期記憶)或者長短期的存儲單元。當他們被連接到層神經網(wǎng)絡時,RNN將狀態(tài)在自身網(wǎng)絡中循環(huán)傳遞,因此可以接受更廣泛的時間序列結構輸入。比如:語言處理或者翻譯,以及信號處理,文本到語音,語音到文本……

強化學習是第三種主要的深度學習(DL)方法,強調如何基于環(huán)境而行動,以取得最大化的預期利益。一個例子就是迷宮,其中每個單元都存在各自的“狀態(tài)”,擁有四個移動的方向,在每個單元格某方向的移動的概率來形成策略。
通過反復運行狀態(tài)和可能的操作,并獎勵產生良好結果的操作序列(通過增加策略中這些操作的概率),懲罰產生負面結果的操作(降低概率)。隨著時間的推移,你會得到一個最優(yōu)的策略,它有最高的可能性來取得一個成功的結果。通常在訓練的時候,你會對更早的行為的懲罰/獎勵打折扣。

在我們的迷宮事例中,先允許代理穿過迷宮,選擇一個方向,使用已有的概率策略,當它達到死胡同時,懲罰它選擇的路徑(降低每個單元移動該方向的概率)。如果找到了出口,我們則增加每個單元移動方向的概率作為獎勵。隨著時間的推移,代理通過學習,找到了最快方式。強化學習的這種變化就是AlphaGo AI和Atari電子游戲AI的核心。
最后值得關注的是GANs(生成對抗網(wǎng)絡),它更多的是一門技術而不是架構。目前它與CNNs一起用于制作圖像鑒別器和發(fā)生器。鑒別器是經過訓練以識別圖像的CNN,生成器是一個反向網(wǎng)絡,它采用隨機種子生成圖像。鑒別器評估發(fā)生器的輸出并向發(fā)生器發(fā)送關于如何改進的信號,發(fā)生器依次向鑒別器發(fā)送信號以提高其準確性,在零和博弈游戲(zero-sum game)中反復往返,直到兩者收斂到最佳質量。這是一種向神經系統(tǒng)提供自我強化反饋的方法。
當然,所有這些方法以及其他方法都有豐富的變化和組合,但是一旦你嘗試將它們用于特定問題之外的問題時,這些技術有時不會有效。對于實際問題,即使你可以擴展和重新設計網(wǎng)絡拓撲并對其進行調整,它們有時也表現(xiàn)不加。往往我們只是沒有足夠的數(shù)據(jù)來訓練它們,以使得它們在部署中更加精準。
同樣,許多應用需要將多種DL技術結合在一起并找到融合它們的方法。一個簡單的例子就是視頻標記——你通過CNN傳送視頻幀,在頂部有一個RNN來捕捉這些視頻中的那些隨著和時間有關的行為。曾經我?guī)椭芯咳藛T使用這種技術來識別四肢癱瘓者的面部表情,向他們輪椅和機器假肢發(fā)出命令,每個指令對應不同的面部表情/手勢。這起到了一定的效果,但當你擴大規(guī)模時,開發(fā)和訓練它可能會花費更多時間,且變得非常棘手。因為你現(xiàn)在必須調整交織在一起的兩種不同類型的DL網(wǎng)絡,有時很難知道這些調整會產生什么影響。
現(xiàn)在想象一下,你有多個CNN/RNN網(wǎng)絡提供輸出,一個深度強化學習引擎對輸入狀態(tài)做出決策,然后驅動生成網(wǎng)絡產生輸出。其實是很多特定的DL技術組合在一起來完成一組任務。你可以說這是“魔鬼式”的瘋狂調參。它會奏效嗎?我不知道,如此一來,它將耗費大量資金和時間才開始工作,并且不確定它是否能夠很好的訓練,甚至在現(xiàn)實條件下進行訓練。
我個人觀點是,我們目前的DL技術各自代表一個子集,用來簡化大腦網(wǎng)絡和神經系統(tǒng)的工作。雖然我們稱之為“神經”,但實際上并不是,它們都是專門用于特定的任務。
事實上,大多訓練DL或者人工智能的人都沒有意識到,如今深度學習中的“神經網(wǎng)絡”和“神經元”只是更大、更豐富的合成神經元、神經網(wǎng)絡和方法。我們今天在DL中使用的大多數(shù)人分層我網(wǎng)絡和CNN屬于前饋神經網(wǎng)絡的較小一部分,只是簡單地對每個節(jié)點處進行加權輸入求和,應用簡單的傳遞函數(shù),將結果傳遞給下一層。
這并不是大腦處理工作的方式,甚至RNN和強化學習也沒有給我們真正的人工智能,只是將非常大和復雜函數(shù)的參數(shù)擬合到大量數(shù)據(jù),并使用統(tǒng)計數(shù)據(jù)找到模式并做出決定。
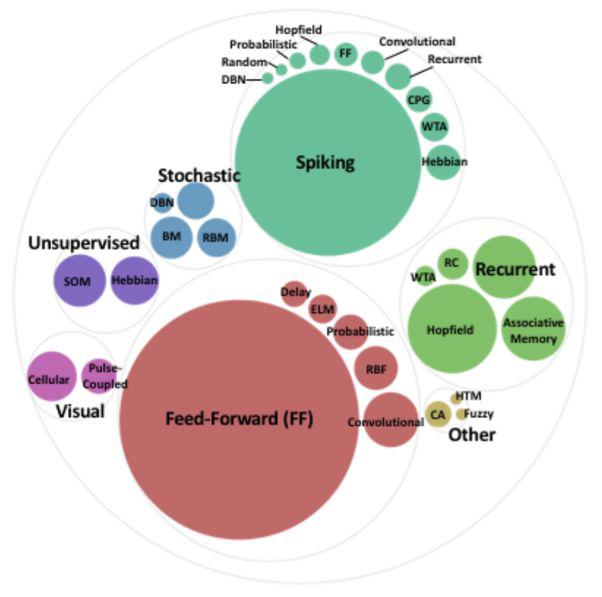
上圖頂部和左側的方法,特別是SNNs(Spiking Neural Networks),給出了一個更準確的模型,來運行真正的神經元工作方式。就像“數(shù)積分-火-模型”、Izhikevich脈沖神經元模型那樣高效。像“Hodgkin-Huxley”一樣接近模擬生物神經元的行為。
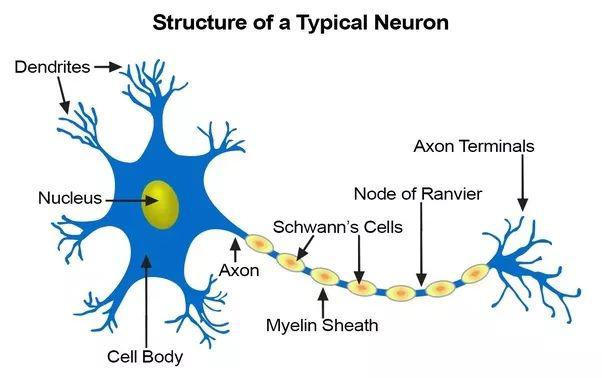
在真實的神經元中,時域信號脈沖沿著樹突傳播,然后獨立到達神經元體,并在其內部的時間和空間中被整合(一些激發(fā)、一些抑制)。當神經元體被觸發(fā)時,它就會在軸突上產生一系列依賴時間的脈沖,這些脈沖在分支時分裂,并需要時間到達突觸。當化學神經遞質信號經過突觸并最終觸發(fā)突觸后樹突中的信號時,突觸本身就表現(xiàn)出非線性、延遲、依賴時間依賴的整合。在這一過程中,如果兩邊的神經元在一定的時間間隔內一起點燃,也就是學習過程中的突觸即學習,即學習,就會得到加強。我們可能永遠無法在硬件或軟件中完全復制真實生物神經元的所有電化學過程,但是我們可以尋找足夠復雜的模型來代表我們的尖峰人工神經網(wǎng)絡中需要的許多有用行為。
這將讓我們更像人工智能,因為真正的大腦從信號通過神經元、軸突、突觸和樹突的傳遞,獲得了更多的計算、感官處理和身體控制能力,從而在復雜的依賴時間的電路中穿行,這種復雜的電路甚至可以有反饋回路,以制造定時器或振蕩器等電路,類似于可重復的級聯(lián)模式激活的神經回路,向肌肉/致動信號的群體發(fā)送特定的依賴模式。這些網(wǎng)絡也是通過直接加強神經元之間的聯(lián)系來學習的,這些被稱為Hebbian學習。為了進行更復雜的人工智能和決策,它們比我們在上面的例子中使用的CNNs、靜態(tài)的RNN甚至是深度強化學習都要強大得多。
但是有一個巨大的缺點——目前還沒有一種方法可以把這類網(wǎng)絡安裝到數(shù)據(jù)上來“訓練”它們。沒有反向傳播,也沒有調整神經元之間突觸權重的梯度下降操作。突觸只是增強或減弱,因此尖峰神經網(wǎng)絡在運作的過程中學習,使用Hebbian學習來進行操作,這在實踐上可能有效訓練我們的合成網(wǎng)絡,因為他們首先必須結構正確,以達到一個有用的解決方案。這是一個正在進行的研究領域,在這一領域的突破可能是非常重要的。
我認為,如果我們可以開始解決這些問題,走向更加功能性更強的神經結構,更加充分地展示大腦、神經系統(tǒng)和真正的神經元的工作和學習方式,我們就可以開始將今天使用的那種單一的、更靈活的深度學習方法整合到這些功能更強大和靈活的架構中,這些架構以更優(yōu)雅的設計來處理多種功能。而且通過這些模型,我們將開啟新的神經計算形式,我們將能夠將它們應用到計算機視覺、機器人運動控制、聽覺、言語,甚至是更像人腦的認知等任務中去。
簡單總結一句話:“我們還沒有達到人類層面的認知。”
更多信息可以來這里獲取==>>電子技術應用-AET<<
