
??? 摘 要: 針對(duì)三維模型" title="三維模型">三維模型檢索算法性能較低的問題,提出了一種改進(jìn)的中軸骨架三維模型檢索" title="三維模型檢索">三維模型檢索算法。
??? 關(guān)鍵詞: 三維模型檢索,特征變換,中軸骨架,骨架二叉樹
?
??? 隨著激光掃描技術(shù)的發(fā)展以及計(jì)算機(jī)性能的提高,三維模型在很多應(yīng)用領(lǐng)域中扮演著非常重要的角色,如工業(yè)產(chǎn)品的模型設(shè)計(jì)、虛擬現(xiàn)實(shí)系統(tǒng)、游戲設(shè)計(jì)、逆向工程以及仿真等,但是,要想構(gòu)造一個(gè)真實(shí)感較強(qiáng)的模型其工作量巨大。目前在因特網(wǎng)和特定領(lǐng)域的數(shù)據(jù)庫(kù)中存在著數(shù)以兆計(jì)的模型,且還在源源不斷地增加。如果能夠重復(fù)利用已有模型,就可大大減小模型設(shè)計(jì)的工作量。因此,對(duì)三維模型檢索技術(shù)的研究已變得越來越緊迫和重要。
??? 目前,三維模型檢索主要采用基于內(nèi)容的檢索方法。根據(jù)特征提取方法的不同,可將檢索方法大致分為四類:統(tǒng)計(jì)特征、函數(shù)投影、拓?fù)浣Y(jié)構(gòu)" title="拓?fù)浣Y(jié)構(gòu)">拓?fù)浣Y(jié)構(gòu)特征和基于幾何結(jié)構(gòu)分析。
??? 基于統(tǒng)計(jì)特征的三維模型描述方法[1],不需要通過模型進(jìn)行標(biāo)準(zhǔn)化處理,因此計(jì)算較為簡(jiǎn)單,具有良好的不變性。但是,這些特征描述模型之間相似性的能力普遍不夠強(qiáng),對(duì)三維模型本身內(nèi)容的描述也不夠充分。
??? 基于函數(shù)投影的方法首先是將原始的三維模型投影至一個(gè)標(biāo)準(zhǔn)函數(shù)模型中[2],然后再計(jì)算特征向量。其優(yōu)點(diǎn)在于其將三維模型投影為一系列不同視角的二維圖像,從而大大減低了匹配的復(fù)雜度。但在函數(shù)投影過程中容易丟失一些重要的三維結(jié)構(gòu)信息,因此檢索的準(zhǔn)確性不夠理想。
??? 基于模型拓?fù)浣Y(jié)構(gòu)特征的方法主要是根據(jù)模型的幾何信息和拓?fù)浣Y(jié)構(gòu)獲取模型的特征描述。Hilaga等人提出一種使用多分辨率Reeb圖MRG(Multiresolution Reeb Graph)結(jié)構(gòu)表示三維模型的方法[3]。而Sundar利用模型骨架描述三維模型的特征[4],該類方法能很好地描述模型本身的特征,可以獲得較高的檢索準(zhǔn)確率,但該方法計(jì)算量較大。
??? 基于幾何結(jié)構(gòu)分析的形狀特征的方法由于能較好地描述模型的高層結(jié)構(gòu)信息而受到廣泛關(guān)注。Vranic等人[5]基于三維離散傅立葉變換的方法提取三維模型的特征。當(dāng)三維模型可以被分割為一組規(guī)范化的特征集合并且特征之間的對(duì)應(yīng)關(guān)系明確時(shí),該方法具有很好的效果。然而,對(duì)于廣義的三維多邊形模型而言,實(shí)現(xiàn)上述條件是非常困難的。
??? 因此,如何提高三維模型的檢索性能,就成了十分突出的問題。本文提出一種基于整數(shù)中軸骨架的三維模型檢索算法,該算法的關(guān)鍵思想是將三維模型的拓?fù)涮卣骱徒y(tǒng)計(jì)特征相結(jié)合。首先,對(duì)待匹配的三維模型進(jìn)行預(yù)處理;然后改進(jìn)Hesselink提出的整數(shù)中軸算法[6],得到模型的中軸骨架,對(duì)骨架按區(qū)域劃分,構(gòu)造骨架二叉樹" title="骨架二叉樹">骨架二叉樹,同時(shí)根據(jù)區(qū)域的大小定義節(jié)點(diǎn)的特征權(quán)值" title="權(quán)值">權(quán)值,用于衡量其對(duì)三維模型整體相似性的影響程度;最后,通過計(jì)算兩個(gè)骨架二叉樹的相似度,獲得兩個(gè)三維模型的相似度,在匹配過程中,采用由粗到細(xì)逐步淘汰的策略,不斷縮減待匹配模型的范圍,從而降低了模型匹配的時(shí)間。實(shí)驗(yàn)結(jié)果表明,該算法可以得到較好的檢索性能。
1 模型預(yù)處理
??? 對(duì)于同一種檢索算法,處于不同坐標(biāo)系下的三維模型應(yīng)該具有相同的相似度。因此,檢索算法在計(jì)算三維模型幾何特征之前,應(yīng)該對(duì)三維模型進(jìn)行姿態(tài)調(diào)整,使其坐標(biāo)系一致。
??? 本文采用主元分析法PCA(Principal Component Analysis)對(duì)模型進(jìn)行姿態(tài)調(diào)整[7]。該方法首先根據(jù)三維模型點(diǎn)集合的協(xié)方差矩陣計(jì)算出相應(yīng)的特征值λ1>λ2>λ3,其對(duì)應(yīng)的特征矢量為(I1,I2,I3),以(I1,I2,I3)為新的坐標(biāo)系統(tǒng),對(duì)三維模型進(jìn)行坐標(biāo)變換,得到變換后的坐標(biāo)值。處理結(jié)果如圖1所示。

2 骨架提取
??? 設(shè)r是三維模型表面上的點(diǎn),由Hesselink的整數(shù)中軸算法可得:
??? 若e∈E,(E={e∈I3||e||=1}),I3為模型內(nèi)部的一個(gè)體素網(wǎng)格點(diǎn),則當(dāng)m=r+1/2e時(shí):
??? ||m-ft(r+e)||=||m-ft(r)||????????????????? (1)
式中,m為整數(shù)中軸骨架上的一個(gè)骨架點(diǎn),ft(r)為點(diǎn)r的特征變換函數(shù)。
??? 為了記錄以骨架點(diǎn)m為球心的內(nèi)接球的半徑,對(duì)整數(shù)中軸骨架進(jìn)行改進(jìn),定義一元函數(shù):
??? σm=||m-ft(r)||????????????????????????????(2)
式中,σm為骨架點(diǎn)m的權(quán)值。
??? 由Hesselink整數(shù)中軸算法得到的骨架是一些比較散亂的骨架點(diǎn),如圖2所示。而一個(gè)好的中軸骨架應(yīng)具有以下三個(gè)特性:相鄰性、一致性和簡(jiǎn)潔性[2]。因此,本文對(duì)獲得的骨架點(diǎn)進(jìn)行以下優(yōu)化。

?
??? 如果q為三維模型表面上的一個(gè)網(wǎng)格點(diǎn),B是一個(gè)網(wǎng)格點(diǎn)的集合,則可以在中軸骨架上找到一個(gè)點(diǎn)p,使得p=IMAS(q)(IMAS(q)表示對(duì)點(diǎn)q進(jìn)行整數(shù)中軸骨架變換)。同樣對(duì)于任意一個(gè)中軸骨架點(diǎn)p,對(duì)其進(jìn)行整數(shù)中軸骨架變換的逆變換IMAS-1(p),就會(huì)得到一個(gè)與其相對(duì)應(yīng)的三維模型表面網(wǎng)格點(diǎn)的集合。設(shè)q∈B,p=IMAS(q),點(diǎn)q和p之間的距離定義為dis(q)。定義一個(gè)輔助函數(shù)Average(dis(q)),其函數(shù)值為dis(q)(q∈IMAS-1(p))的平均值。所有的中軸骨架點(diǎn)應(yīng)該滿足:
??? 
將所有優(yōu)化后的骨架點(diǎn)連接起來形成加權(quán)骨架H,如圖3所示。

?
3 模型匹配
3.1 生成骨架二叉樹
??? 設(shè)δmax(ni)和δmin(ni)分別為骨架二叉樹節(jié)點(diǎn)ni對(duì)應(yīng)的中軸骨架區(qū)域Zi的Z軸坐標(biāo)最大值和最小值。在進(jìn)行更高一級(jí)細(xì)節(jié)層次劃分時(shí),按下面的公式計(jì)算每個(gè)區(qū)域的Z軸坐標(biāo)最大值和最小值,骨架區(qū)域劃分示意圖如圖4所示。

??? 
??? 將區(qū)域Ci視為二叉樹節(jié)點(diǎn)ai,其權(quán)值Wai為:
??? 
3.2 匹配骨架二叉樹
??? 設(shè)ai和bi(0≤i≤n)為三維模型P、Q對(duì)應(yīng)的骨架二叉樹中的節(jié)點(diǎn),則它們的相似度函數(shù)為:
??? 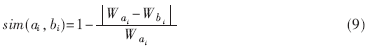
??? 設(shè)三維模型P、Q的相似度函數(shù)為:
??? 
??? 但是,在匹配過程中,由于模型的不同部分對(duì)模型整體的相似性的影響不同,因此對(duì)不同的sim(ai,bi)賦予不同的權(quán)值xi,對(duì)相似度函數(shù)加以改進(jìn),加入權(quán)值因子xi,改進(jìn)的相似度函數(shù)為:
??? 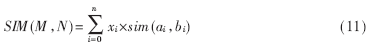
式中,![]() f(ai)為對(duì)應(yīng)節(jié)點(diǎn)ai的區(qū)域大小,f(ao)為整個(gè)區(qū)域的大小。
f(ai)為對(duì)應(yīng)節(jié)點(diǎn)ai的區(qū)域大小,f(ao)為整個(gè)區(qū)域的大小。
??? 具體的匹配步驟如下:
??? (1)定義域值區(qū)間g=[0,β],β∈R;生成兩個(gè)骨架二叉樹的根節(jié)點(diǎn)ao、bo,若sim(ao,bo)∈g,則繼續(xù)以下步驟;否則匹配結(jié)束,兩個(gè)模型不相似。
??? (2)若ai、bi為非葉子節(jié)點(diǎn),則生成ai、bi的左孩子節(jié)點(diǎn)a2i+1和b2i+1,若sim(a2i+1,b2i+1)∈g,則繼續(xù)以下步驟;否則匹配結(jié)束,兩個(gè)模型不相似。
??? (3)若ai、bi為葉子節(jié)點(diǎn),sim(ai,bi)∈g,則該分支的匹配結(jié)束,向上回溯到其父親節(jié)點(diǎn),進(jìn)行另一分支的匹配;若sim(ai,bi)∈g,則匹配結(jié)束,兩個(gè)模型不相似。
??? (4)生成ai和bi的右孩子節(jié)點(diǎn)a2i+2和b2i+2,若sim(a2i+2,b2i+2)∈g,則繼續(xù)以下步驟;否則匹配結(jié)束,兩個(gè)模型不相似。
??? (5)若二叉樹的任意節(jié)點(diǎn)ai和bi都滿足:sim(ai,bi)∈g,(0≤i≤n),則兩模型相似。
??? (6)重復(fù)執(zhí)行(2)~(5)。
4 實(shí)驗(yàn)結(jié)果與分析
??? 為了測(cè)試算法的效果,對(duì)本文方法、中軸骨架方法和形狀分析方法的檢索性能進(jìn)行了實(shí)驗(yàn)和比較。實(shí)驗(yàn)在Windows平臺(tái)上用VC++6.0語(yǔ)言實(shí)現(xiàn),三維模型數(shù)據(jù)庫(kù)采用普林斯頓大學(xué)形狀分析小組提供的標(biāo)準(zhǔn)測(cè)試數(shù)據(jù)庫(kù)[8],總共含有1 800個(gè)模型,采用典型的Precision-Recall曲線來度量不同方法的檢索性能,三種方法的檢索性能曲線如圖5所示。由圖可以看出,本文方法由于在拓?fù)浣Y(jié)構(gòu)的基礎(chǔ)上融入了統(tǒng)計(jì)特征,因此在檢索性能上有明顯提高。

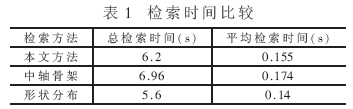
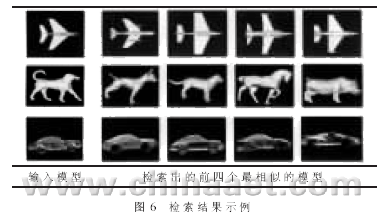
??? 對(duì)于三維模型檢索,另一個(gè)值得注意的問題是檢索效率。如果檢索時(shí)間過長(zhǎng),將導(dǎo)致實(shí)時(shí)性差,即使檢索準(zhǔn)確率有了明顯的改進(jìn),其實(shí)用性也不強(qiáng)。本文采用改進(jìn)的中軸骨架提取方法,它與傳統(tǒng)的中軸骨架方法相比降低了算法的復(fù)雜度,但與形狀分布方法相比在算法復(fù)雜度上有所增加,比形狀分布方法需要更多的檢索時(shí)間。但是,這種檢索時(shí)間的差異很小,不會(huì)被用戶察覺。對(duì)三種模型檢索的具體實(shí)驗(yàn)驗(yàn)證環(huán)境是:CPU:Pentium 4 2.4GHz,內(nèi)存512MB。對(duì)一批模型數(shù)據(jù)(40個(gè)模型)進(jìn)行批處理,得到總檢索時(shí)間和平均檢索時(shí)間(檢索時(shí)間包括打開文件讀取模型數(shù)據(jù)的時(shí)間)如表1所示,檢索結(jié)果示例如圖6所示。
?
??? 三維模型檢索技術(shù)是近年來隨著三維模型獲取手段的增強(qiáng)、增多以及互聯(lián)網(wǎng)的發(fā)展而興起的計(jì)算機(jī)圖形學(xué)領(lǐng)域內(nèi)的一個(gè)重要課題。針對(duì)三維模型檢索性能較低的問題,本文將三維模型的統(tǒng)計(jì)特征和拓?fù)涮卣飨嘟Y(jié)合,提出了一種基于增強(qiáng)的中軸骨架三維模型檢索算法。通過對(duì)本文方法的檢索性能、檢索時(shí)間進(jìn)行測(cè)試,結(jié)果表明,該算法可以得到較好的檢索性能。
參考文獻(xiàn)
[1] TANGELDER J W H,VEHKAMP R C.Polyhedral model?retrieval using weighted point sets.Journal of Image and?Graphics,2003,3(1):209-229.
[2] 普建濤,劉一,辛谷雨,等.一種基于二維多邊形集相似性的三維模型檢索方法[J].中國(guó)圖像圖形學(xué)報(bào),2004,9(12):1437-1442.
[3] HILAGA M,SHINAGAWA Y,KOHMURA T,et a1.Topology matching for fully automatic similarity estimation of 3d?shapes proceedings of ACM SIGGRAPH.Los Angeles,USA,2001:203-212.
[4] SUNDAR H,SILVER D,GAGVANI N,et al.Skeleton based shape matching and retrieval? proceedings of international?conference on shape modeling and applications.Seoul,Korea,2003:207-216.
[5] VRANIC D,SAUPE D.3d shape descriptor based on 3d?Fourier transform? proceedings of IEEE EURASIP conference on digital signal processing for multimedia communications?and services.Budapest, Hungary,2001:271-274.
[6] HESSELLINK W H,VISSER M,ROERDINK J B T M.Euclidean skeletons of 3D data sets in linear time by the?integer medial axis transform[A].ISMM′2005[C].Paris,F(xiàn)rance,2005:259~268.
[7] VRANIC D,AAUPE D.3D shape descriptor based on 3D?fourier transform[A].EURASIP conference on digital signal?processing for multimedia communications and services[C].Budapest,Hungary:EURASIP,2001:271~274.
[8] SHILANE P,MICHAEL K,PATRICK M,et al.The princeton shape benchmark.In:Proc of the intern ational conference on shape modeling.Genova,Italy,2004:167-178.?
?