
??? 摘??要: 基于網(wǎng)絡處理器" title="網(wǎng)絡處理器">網(wǎng)絡處理器的特點,提出了一種新的多模" title="多模">多模匹配算法HBM算法,。在Intel網(wǎng)絡處理器IXP2400上,,設計實現(xiàn)了高速反蠕蟲病毒引擎" title="反蠕蟲病毒引擎">反蠕蟲病毒引擎。實驗表明,,引擎達到了千兆以太網(wǎng)的性能要求,,具有較好的實際應用價值。
??? 關鍵詞: 網(wǎng)絡處理器? 反蠕蟲病毒引擎? 多模匹配算法? HBM算法
?
??? 隨著Internet規(guī)模的擴大,,網(wǎng)絡安全已經(jīng)成為當前網(wǎng)絡系統(tǒng)設計中的一個重要問題,。為此,,在當前的網(wǎng)絡防火墻和入侵檢測系統(tǒng)(IDS)中,除了需要進行協(xié)議分析,、流狀態(tài)檢測外,,還需要對網(wǎng)絡分組的載荷進行特征匹配,以此來確定網(wǎng)絡分組中是否含有蠕蟲病毒代碼,。與網(wǎng)絡帶寬的飛速提高相比,,反蠕蟲系統(tǒng)的掃描引擎的發(fā)展還不成熟,開發(fā)千兆以太網(wǎng)環(huán)境下的反蠕蟲系統(tǒng)還有難度,。本文給出的對于網(wǎng)絡分組載荷進行掃描檢測的多模匹配引擎,,正是一種適合高速環(huán)境下的反蠕蟲引擎系統(tǒng)。
1 相關工作
??? 反蠕蟲引擎平臺主要有兩種:一種是采用全硬件定制的方式,;另一種是采用軟件實現(xiàn)的方式,。采用硬件方式往往能夠得到較高的掃描檢測速度,但是不適合設計比較復雜的防火墻或IDS系統(tǒng),;采用軟件方式的掃描引擎速度較慢,,但是可以用來設計實現(xiàn)功能復雜的系統(tǒng)。
??? 網(wǎng)絡處理器[1]是一種介于全硬件定制和通用處理器之間的新型處理器,,相對于前兩種實現(xiàn)方式,,網(wǎng)絡處理器兼有他們的優(yōu)點。一方面,,它采用執(zhí)行程序的方式,,相比于硬件實現(xiàn)方式,可以完成較為復雜的處理功能,。同時,,也可以方便地添加和擴展功能模塊,有效地移植和整合現(xiàn)有的程序功能,。另一方面,,它的硬件體系結(jié)構(gòu)針對網(wǎng)絡應用進行了優(yōu)化,大大提升了分組處理過程,,可以得到較好的性能指標,,適合作為網(wǎng)絡應用的開發(fā)平臺[1,5,9]。
??? 反蠕蟲引擎的核心算法是多模匹配算法(multi-pattern matching algorithm)[2,4],,即對于輸入的字符串,,掃描其是否包含預先給定的若干特征字符串之一,蠕蟲攜帶的特征字符串也稱為特征碼(signature),。
??? 多模匹配的主要算法之一是將BM算法[6]在多模匹配條件下進行擴展,。BM算法是一種啟發(fā)式算法,主要利用了失效字符轉(zhuǎn)跳及好后綴轉(zhuǎn)跳思想,如圖1和圖2所示,。該算法思想是在每次匹配中,,從右往左反向逐個比較字符,當發(fā)生匹配失敗時,,根據(jù)此字符的信息以及之前比較過的字符串后綴(即字符串最右部分)信息,,最大程度地向后移動比較指針,從而減少無用的比較次數(shù),。在圖1中,,輸入字符‘l’匹配失敗,從失效轉(zhuǎn)跳表Delta1中,,找到‘l’對應項的值(該值為‘l’在“hello hi”中最右出現(xiàn)處到串末尾的距離),,并將輸入字符串向左移動相應距離。在圖2中,,輸入串的‘do’和特征字符串末尾的‘do’相匹配,,稱特征字符串的‘do’為好后綴。轉(zhuǎn)跳時,,可以將輸入字符串的‘do’移動到和特征串中的前一個‘do’相對齊位置,。
?

??? BM算法思路推廣到多模匹配中,,由于匹配模式增加,,Delta1表的每一項必須是字符塊而不是單個字符(否則,所有值均接近0,,無法給出好的轉(zhuǎn)跳信息),,這樣就帶來Delta1表空間增大的問題,同時原來的好后綴生成算法在多模匹配下也不正確,,需要重新設計,。
??? 這類算法主要有WM算法[4]、Setwise BMH算法[7],、AC-BM算法[8]等,。WM算法只對輸入字符串的后綴進行一次比較,并沒有很好地利用字符串的整體信息,,也沒有利用好后綴的可能轉(zhuǎn)跳,。Setwise BMH算法和AC-BM算法的失效字符轉(zhuǎn)跳表(Delta1表)的組織空間往往很大,無法放入高速緩存之中,,不適合在網(wǎng)絡處理器上實現(xiàn),。為此,本文基于網(wǎng)絡處理器的特點,,提出了一種新的多模匹配算法,,即HBM算法。
2 HBM算法描述
??? HBM算法同樣使用失效字符轉(zhuǎn)跳思想,所不同的是,,將失效字符轉(zhuǎn)跳表(Delta1表)進行散列壓縮(允許碰撞),,從而可以大大減少Delta1表的空間占用;同時,,在多模匹配情況下改進好后綴轉(zhuǎn)跳方式,。與以上幾種算法相比,HBM算法可以在空間要求大大降低的情況下,,得到相近甚至更優(yōu)的時間性能,;同時,在網(wǎng)絡處理器系統(tǒng)中,,可利用高速緩存單元,,得到更好的系統(tǒng)性能數(shù)據(jù)。其主要步驟如下:
??? (1)每次比較的基本單位是若干個字符(在實現(xiàn)中取4個字符)組成的字符塊,。
??? (2)每次對一段輸入子字符串的匹配是從右向左依次進行的,。例如,子字符串“abcdef”需要先比較字符塊“cdef”,,再比較“bcde”,,最后比較“abcd”。判斷第i次字符塊比較是否成功的條件是:該字符塊在Delta1表中的值D1是否小于i(即D1
??? (4)算法使用兩張啟發(fā)式移位表:Delta1和Delta2,,第(3)步中輸入字符串的移動距離,取兩者中的較大值,。
??? (5)若某個子字符串的所有字符塊均比較成功,,則還需要和蠕蟲特征碼進行精確比較,才能確定其為特征碼之一或是一次誤判(false-positive),。
??? 整個掃描過程并不復雜,,算法的主要難點在于如何有效地構(gòu)造兩張啟發(fā)式移位表Delta1和Delta2。下面對這兩張表的構(gòu)造做詳細介紹,。
2.1 Delta1表構(gòu)造
??? Delta1表的構(gòu)造和原BM算法相比,,不同之處在于:
??? (1)比較的基本單位變?yōu)樽址麎K。
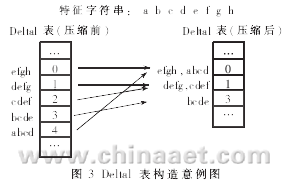
??? (2)字符塊在Delta1表中的索引位置由散列函數(shù)值決定,。
??? (3)如果兩個字符塊由于散列沖突而對應Delta1表的同一項,,則此項存放兩者中的較小“移位距離”,。
??? 例如,圖3中“efgh”和“abcd”的散列值相同,,它們就存放于Delta1表中的同一項,,其值取較小的值0。
?
?
2.2 Delta2表構(gòu)造
??? Delta2表的構(gòu)造比較復雜,,下面將給出其構(gòu)造和使用方法,。
??? 在多模匹配情況下,不能像BM算法那樣直接找特征串首部是否有和后綴相同的字串,,而是要通過字符塊在Delta1表中的值D1,,來間接判斷首部是否有好后綴。例如,,在圖4中,,字串“xbcde”和后綴串“abcde”具有相同的特征(如圖所示,從右往左數(shù),,第i個字符塊的Delta1值D1
?

?
??? 記特征字符串數(shù)為n,長度為L,,塊大小為b,;記特征碼為S0,S2……,Sn-1,,為了便于描述,,將任意字符串pattern=a0a1a2…aL-1,擴充記為pattern=…$$$$a0a1a2…aL-1,,即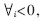 ai=$。其中$為假想字符,,可為任意字符,,同時任何含有$的字符塊,其Delta1值定為D1=0,。這里對所有特征字符串都作了這種擴充,。
ai=$。其中$為假想字符,,可為任意字符,,同時任何含有$的字符塊,其Delta1值定為D1=0,。這里對所有特征字符串都作了這種擴充,。
??? 在給出Delta2表的構(gòu)造和使用之前,先給出某個子字符串“相一致”,,以及函數(shù)rpr(rightmost plausible reoccurrence)的定義,。
??? “相一致”指的是在特征字符串中,某個子字符串和后綴子字符串,,它們的首字符塊有不同的特性,,而其余對應字符塊則有共同的特性,,如圖4所示。由于出現(xiàn)好后綴轉(zhuǎn)跳時,,后綴子字符串的Delta1值特性固定,,因此定義特征字符串中的子字符串C=c0 c1…cn和后綴字符串“相一致”,要求滿足條件(1):
??? 
式中,,D1(ci ci+1…ci+b-1)為字符塊ci ci+1…ci+b-1在Delta1表中的移位值,。
??? 定義函數(shù)y=rpr(Si,t),t∈[0,L-b-1],,要求在特征字符串Si中,,從位置t往左(不包括t),找到長度為L-t的最右的相一致的子字符串,,記此子字符串為位置k開始的siksi(k+1)…si(k+L-t-1),,則rpr(Si,t)=k+1。
??? Delta2表長度固定為L-b+1,,記Delta2表的第t項的值為D2(t),,則其值可由(2)式求得。
???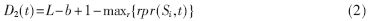
式中,,0≤t≤L-b-1,,maxr{rpr(Si,t)}表示對于r=0,1,…n-1,取這n個特征字符串Sr的rpr值中的最大值,。
3 基于網(wǎng)絡處理器的優(yōu)化
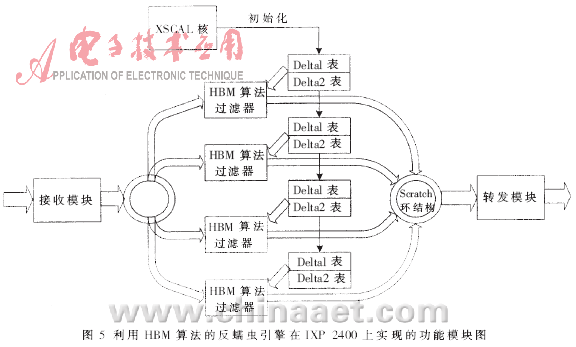
??? 本文將HBM算法在Intel網(wǎng)絡處理器IXP 2400上實現(xiàn),,并針對IXP 2400的體系結(jié)構(gòu)特點進行了優(yōu)化。主要由網(wǎng)絡處理器的XScale核心對蠕蟲特征碼進行初始化處理,,組織兩張啟發(fā)式移位表,;運行時主要由微引擎執(zhí)行掃描工作,完成網(wǎng)絡分組的接收,、分類,、掃描和轉(zhuǎn)發(fā)功能。系統(tǒng)整體功能模塊如圖5所示,。
?
??? 在IXP 2400上實現(xiàn)HBM多模匹配算法時,,綜合起來,主要的優(yōu)化有:
??? (1)算法中的散列運算用邏輯操作完成,,不需要復雜的乘除指令支持,,適合網(wǎng)絡處理器的指令結(jié)構(gòu)。
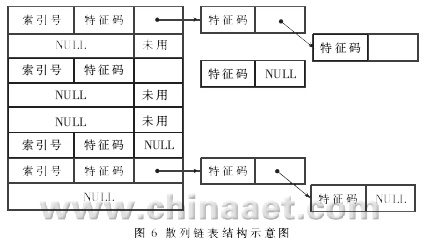
??? (2)將特征字符串組織成散列鏈表的形式,,以減少精確匹配時的I/O" title="I/O">I/O操作次數(shù),。散列鏈表結(jié)構(gòu)如圖6所示。
?
??? (3)將兩張訪問頻率較高的表Delta1和Delta2存放在I/O存取速度快的存儲單元,,將訪問頻率低的特征字符串集合存放在存取速度慢的單元,,如表1所示,。
?

?
??? (4)對于輸入的分組載荷進行預讀取功能,以減少I/O操作次數(shù),。即對于輸入的分組載荷,,每次從慢速DRAM中預讀取最大的64個二進制字符,通過軟件計算指針位置,,從而有效地利用預讀取的分組載荷,,減少I/O訪問次數(shù)。
4 實驗測試與性能分析
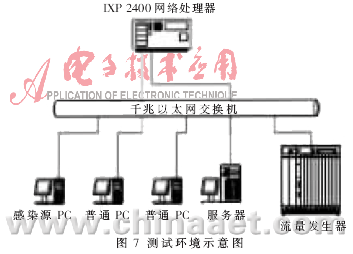
??? 在測試床中對系統(tǒng)的有效性進行了測試,。該測試床包括以下設備:千兆以太網(wǎng)絡交換機(TP-LINK TL-SL2226P+,24+2G),、流量發(fā)生器IXIA 1600、ENP 2611實驗板(含IXP2400網(wǎng)絡處理器),,以及攜帶蠕蟲病毒的PC機,、多臺普通PC機和服務器。其配置環(huán)境示意圖如圖7所示,。反蠕蟲病毒引擎工作在監(jiān)聽模式下被動接收分組,、檢測并發(fā)出報警。
?
??? 實驗采用隨機產(chǎn)生的固定長度特征碼字,,字長為32字節(jié),,特征碼的數(shù)量為512個(注意:HBM算法也支持非固定長度的特征碼字)。產(chǎn)生的以太網(wǎng)幀長度分別為118,、246,、…、1 398以及最大可能的1 518字節(jié),。分組中攜帶特征碼字的比例(簡稱為命中率)為0%,、20%、…,、100%,,特征碼字在分組載荷中的出現(xiàn)位置隨機決定。實驗輸入的分組數(shù)目為4 000,。
??? Intel網(wǎng)絡處理器IXP 2400的XSCAL核的工作主頻為400MHz,,每個微引擎(ME)的工作主頻為400MHz,SRAM和DRAM的總線主頻為100MHz,。實驗數(shù)據(jù)的吞吐率" title="吞吐率">吞吐率值均取于媒體總線(Media Bus)上,其時鐘頻率為104MHz,。
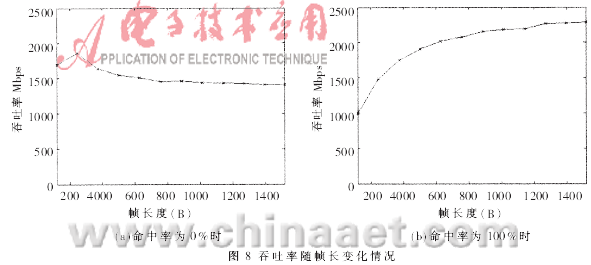
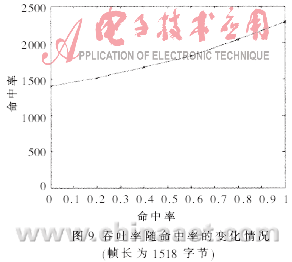
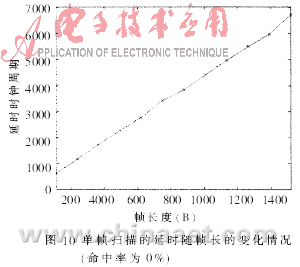
??? 圖8和圖9反映了反蠕蟲引擎的吞吐率性能,。圖8(a)是命中率為0%時的吞吐率隨以太幀長度變化情況,即沒有網(wǎng)絡分組包含蠕蟲特征碼的情況,,引擎性能最后穩(wěn)定在1 400Mbps~1 500Mbps之間,。圖8(b)是命中率為100%時的情況,,即每個網(wǎng)絡分組都包含蠕蟲特征碼的極端情況。此時,,一旦發(fā)現(xiàn)特征碼即結(jié)束操作,,剩余的載荷內(nèi)容不必繼續(xù)檢測,吞吐率隨著以太幀長度的增加而增加,。圖9為吞吐率隨命中率變化情況,,隨著命中率的增加,每幀平均不需要檢測的載荷數(shù)目增多,,吞吐率增大,。圖10為不包含蠕蟲特征碼的網(wǎng)絡分組通過反蠕蟲引擎的延時情況,隨著幀長度的增加,,單幀處理的平均延時呈線性平穩(wěn)增長,。由以上性能數(shù)據(jù)可知:在IXP2400上采用HBM算法的反蠕蟲引擎,已經(jīng)達到了千兆以太網(wǎng)的吞吐率要求,;同時,,算法的吞吐率性能穩(wěn)定,在蠕蟲爆發(fā)時(即命中率大幅度提高),,性能不會有大的下降,。
?
 ????
???? 
?
??? 網(wǎng)絡處理器由于具有靈活的可編程特性,適用于高速的網(wǎng)絡分組處理,。本文采用Intel IXP2400網(wǎng)絡處理器,,設計和實現(xiàn)了基于深度包檢測的反蠕蟲病毒引擎。HBM算法是對經(jīng)典BM算法的一個推廣,,算法的重點是以字符塊為比較單位,,重新設計Delta1表和Delta2表。同時根據(jù)網(wǎng)絡處理器的存儲器架構(gòu)特點,,以允許沖突的散列運算壓縮Delta1表,,合理存放相應的數(shù)據(jù)結(jié)構(gòu),減少了I/O開銷,。實驗結(jié)果表明,HBM算法有效地提高了吞吐率,,并且性能指標穩(wěn)定,達到了高速網(wǎng)絡環(huán)境下的性能要求,。
參考文獻
[1] CHEN Z, LIN C, NI J.AntiWorm NPU-based Parallel?Bloom filters in Giga-Ethernet?LAN[C]//IEEE International Conference on Communications:Network Security and Information Assurance Symposium, 2006.Istanbul:IEEE Press,2006:2118-2123.
[2] SONG H,LOCKWORD J.Multi-pattern signature matching for hardware network intrusion detection systems[C]//: Global Telecommunications Conference Nov,2005:GLOBECOM’05.St. Louis: IEEE Press, 2005:5.
[3]? ?KIENZLE D M, ELDER M C. Recent worms: a survey and trends[C]//Proceedings of the 2003 ACM workshop on ?Rapid Malcode, October, 2003. Washington: ACM Press,2003: 1-10.
[4] ?WU S, MANBER U. A fast algorithm for multi-pattern searching. Technical Report TR-94-17[R]. Department of Computer Science, University of Arizona, 1994.
[5] ?LIU R, HUANG N, KAO C. A fast pattern-match engine ?for network processor-based network intrusion detection system[C]//:Information Technology: Coding and Computing 2004: Proceedings of ITCC 2004 International Conference. Las Vegas: IEEE Press, 2004:97-101.
[6] ?BOYER R, MOORE J. A fast string searching algorithm[J]. Communications of the ACM, 1977,20(10):762-772.
[7] ?FISK M,VARGHESE G.An analysis of fast string matching applied to content-based forwarding and intrusion detection. Technical Report CS2001-0670[R]. University of California-San Diego, 2002.
[8] ?COIT C, STANIFORD S, MCALERNEY J. Towards faster pattern matching for intrusion detection, or exceeding the speed of snort[C]//. Proc. of the 2nd DARPA Information Survivability Conference and Exposition:DISCEX II. Piscataway: IEEE Press, 2001:367-373.
[9] ?XU B, ZHOU X, LI J. Recursive shift indexing: A fast multi-pattern string matching algorithm[C]//Proc. of the 4th International Conference on Applied Cryptography and Network Security:ACNS 2006. Singapore: Springer,2006.