
摘 要: 為充分利用碼本的級(jí)間相關(guān)性,提出了一種聯(lián)合碼本優(yōu)化多級(jí)矢量量化" title="矢量量化">矢量量化(JCO-MSVQ" title="JCO-MSVQ">JCO-MSVQ)碼本設(shè)計(jì)方法" title="設(shè)計(jì)方法">設(shè)計(jì)方法。每次迭代時(shí),先將訓(xùn)練矢量對(duì)碼字進(jìn)行聚類" title="聚類">聚類,再對(duì)各級(jí)碼本進(jìn)行聯(lián)合優(yōu)化,利用條件期望逐級(jí)更新碼本。實(shí)驗(yàn)數(shù)據(jù)表明,該算法在設(shè)計(jì)10維線譜頻率(LSF)參數(shù)量化碼本時(shí),較隨機(jī)松弛算法(SR)碼本有更小的平均量化畸變。23比特/幀LSF參數(shù)量化器平均對(duì)數(shù)譜失真為0.87dB,達(dá)到了透明量化要求。
關(guān)鍵詞: 多級(jí)矢量量化 線譜頻率 加權(quán)對(duì)數(shù)譜失真 透明量化
矢量量化(Vector Quantization)是一種極其重要的信號(hào)壓縮方法,廣泛應(yīng)用于語音、圖像信號(hào)壓縮等領(lǐng)域。信息論的一個(gè)分支——“率-畸變理論”指出,無論對(duì)于何種信息源,即使是無記憶的信息源(即各個(gè)采樣信號(hào)之間互相統(tǒng)計(jì)獨(dú)立),矢量量化總是優(yōu)于標(biāo)量量化,且矢量維數(shù)越大優(yōu)度越高。因此,目前國內(nèi)外對(duì)于矢量量化技術(shù)的研究非常廣泛而深入。平衡考慮量化效果和運(yùn)算復(fù)雜度,多級(jí)矢量量化(MSVQ)提供了一個(gè)很好的折衷辦法。
線性預(yù)測編碼(LPC)參數(shù)能很好地表征語音信號(hào)" title="語音信號(hào)">語音信號(hào)的短時(shí)譜包絡(luò)信息,在各種LPC參數(shù)中,線譜頻率(LSF)[1]較其它參數(shù)能更有效地表達(dá)LPC信息。K.K.Paliwal和B.S.Atal仔細(xì)研究了用24~26個(gè)比特量化一個(gè)10階LSF參數(shù)的方法,提出了分裂矢量量化(Split Vector Quantization)和多級(jí)矢量量化MSVQ(Multistage Vector Quantization)兩種方案,并且試驗(yàn)得到了用25比特的2級(jí)MSVQ能取得較好的量化效果(平均失真1dB,2~4dB概率小于2%,大于4dB為0)。
MSVQ算法有效減小了碼本容量,但如果在量化比特有限的情況下,想取得透明的量化效果,必須解決兩個(gè)問題:(1)怎樣搜索碼本得到最佳匹配索引;(2)怎樣設(shè)計(jì)碼本。在算法設(shè)計(jì)中這兩個(gè)問題必須統(tǒng)一考慮。對(duì)前一個(gè)問題,為了方便一般采用序列搜索算法,依次搜索得到各級(jí)的最佳匹配矢量。在碼本設(shè)計(jì)中,更多的也是分級(jí)依次進(jìn)行碼本訓(xùn)練,割裂了各級(jí)碼本之間的相關(guān)性。本文將著重研究多級(jí)矢量量化的聯(lián)合優(yōu)化碼本設(shè)計(jì)問題。
1 問題分析
傳統(tǒng)的MSVQ算法在LSF參數(shù)碼本設(shè)計(jì)時(shí)采用一種連續(xù)(stage-by-stage)的設(shè)計(jì)方法,第k級(jí)碼本只與前面的第1至第(k-1)級(jí)碼本有關(guān),而不考慮后續(xù)各級(jí)碼本,即將后續(xù)各級(jí)碼本內(nèi)容視為0。在量化時(shí),同樣只在本級(jí)尋找1個(gè)最佳匹配矢量,然后得到余量矢量送入下一級(jí)量化。量化過程可以用式(1)表示,假設(shè)有2級(jí)碼本,需要找出各級(jí)碼本索引:

在序列搜索算法中,搜索yi時(shí),假設(shè)zj為0,搜索zj時(shí)yi已經(jīng)固定。這樣的搜索算法顯然是一種次優(yōu)的搜索算法,解決這個(gè)問題的方法是全搜索[3]。全搜索是最優(yōu)的搜索算法,但是其計(jì)算復(fù)雜度卻是難以承受的。例如,一個(gè)25比特2級(jí)碼本(13-12結(jié)構(gòu)),其全搜索復(fù)雜度是上述連續(xù)搜索的2000倍以上。M進(jìn)制搜索[4]折衷解決了這個(gè)問題。在運(yùn)算量大大減小的情況下,取得了逼近全搜索的量化效果。
在碼本設(shè)計(jì)中,無論是經(jīng)典的GLA算法還是改進(jìn)的模擬退火(SA)算法,碼本設(shè)計(jì)都是逐級(jí)連續(xù)進(jìn)行的。利用各級(jí)碼本之間的相關(guān)性優(yōu)化碼本設(shè)計(jì),可以較明顯地改善MSVQ的量化效果。在應(yīng)用聯(lián)合碼本設(shè)計(jì)方法量化音頻DCT系數(shù)時(shí),已經(jīng)取得了大約0.4 dB的SNR改善[5]。本文在量化LSF參數(shù)時(shí),對(duì)比300步的SR算法,得到了大約0.05dB、約1bit的加權(quán)對(duì)數(shù)譜失真(WLSD)[6]的改進(jìn)效果。
2 算法說明
2.1 失真距離量度
對(duì)一個(gè)MSVQ碼本,為方便考慮假設(shè)共有2級(jí)碼本。LSF參數(shù)為10維矢量。對(duì)LSF參數(shù)而言,其敏感矩陣(sensitivity matrix)是對(duì)角陣,因此可以用加權(quán)最小均方誤差(WMSE)代替加權(quán)對(duì)數(shù)譜失真(WLSD)作為失真量度[6]。量化失真

r的經(jīng)驗(yàn)值一般為0.15。
2.2 理論推導(dǎo)
對(duì)一個(gè)訓(xùn)練矢量集X和兩級(jí)碼本Y、Z,可以對(duì)X中每個(gè)矢量進(jìn)行2級(jí)全搜索,得到最佳索引值對(duì)(i,j)。根據(jù)i和j的不同可以對(duì)X中每個(gè)矢量進(jìn)行聚類。假設(shè)S為對(duì)第一級(jí)碼字形成的聚類,Si為所有X中第一級(jí)量化索引為i的訓(xùn)練矢量集合。同樣假設(shè)R為第二級(jí)碼字聚類,可知,{S1,S2,…,SK1}和{R1,R2,…,RK2}均是同一X集合的不同劃分。對(duì)于X∈Si,平均量化失真為:

可以令v=E{x-U|x∈Si},則第三項(xiàng)為0。第二項(xiàng)恒為非負(fù),所以

通過多次迭代,可以得到聯(lián)合優(yōu)化的最優(yōu)碼本。
2.3 算法描述
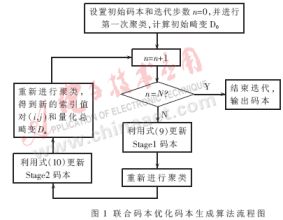
(1)設(shè)置初始碼本,讀入訓(xùn)練矢量文件,并對(duì)其進(jìn)行兩級(jí)碼本全搜索,得到針對(duì)兩級(jí)碼本的聚類{S1,S2,…,SK1}和{R1,R2,…,RK2}。假設(shè)訓(xùn)練矢量個(gè)數(shù)為num,對(duì)所有訓(xùn)練矢量計(jì)算此時(shí)的量化失真之和![]() ,失真測度采用WLSD距離。設(shè)置迭代最大步數(shù)N,設(shè)置初始步數(shù)n=0;
,失真測度采用WLSD距離。設(shè)置迭代最大步數(shù)N,設(shè)置初始步數(shù)n=0;
(2)n=n+1,利用式(9)更新第一級(jí)碼本;
(3)重新對(duì)訓(xùn)練矢量集進(jìn)行全搜索,得到新的索引值對(duì)(i, j),然后利用式(10)更新第二級(jí)碼本;
(4)再次對(duì)訓(xùn)練矢量集進(jìn)行量化搜索,得到新的索引值對(duì)(i, j),并重新計(jì)算量化總畸變Dn;
(5)判斷n=N?若n<N,跳轉(zhuǎn)至(2)繼續(xù)進(jìn)行迭代;若n=N,結(jié)束迭代,保存更新后的碼字至碼本文件。
2.4 算法的進(jìn)一步優(yōu)化
上述聯(lián)合優(yōu)化MSVQ算法中,很重要的一步就是對(duì)訓(xùn)練矢量進(jìn)行聚類,使每個(gè)訓(xùn)練矢量得到一個(gè)最匹配的索引值對(duì)(i, j)。(i, j)應(yīng)當(dāng)是通過全搜索得到的全局最佳匹配矢量。在不需要在線更新碼本的情況下,全搜索是可以采用的。然而如果在矢量維數(shù)較高時(shí),想減小碼本訓(xùn)練的運(yùn)算量,也可以采用M進(jìn)制序列搜索的方法。取M=8在實(shí)驗(yàn)中得到了很好的效果。這樣即可得到一個(gè)性能近似的簡化版JCO-MSVQ碼本設(shè)計(jì)方法。
另外,在碼本設(shè)計(jì)中,可能出現(xiàn)聚類中無訓(xùn)練矢量,即出現(xiàn)空聚類的情況。這時(shí)可以刪除該空聚類,并將包含訓(xùn)練矢量最多的那個(gè)聚類抖動(dòng)成兩個(gè)聚類。這樣可以獲得更小的聯(lián)合量化誤差,如圖1所示。
3 實(shí)驗(yàn)結(jié)果和分析
實(shí)際應(yīng)用中,碼本訓(xùn)練采用107 MB的語音文件,得到342302幀LSF參數(shù)(10維)和加權(quán)系數(shù),訓(xùn)練矢量集足夠大。在實(shí)際的2kbps語音編碼算法中,對(duì)LSF參數(shù)進(jìn)行3級(jí)矢量量化,比特分配為9/8/6,共23bits。利用聯(lián)合優(yōu)化碼本生成算法進(jìn)行300步迭代,與SR算法的第三級(jí)300步迭代結(jié)果進(jìn)行比較,得到訓(xùn)練碼本總畸變數(shù)據(jù),如圖2所示。

可以看到,同樣步數(shù)的JCO-MSVQ算法較SR算法能取得更小的量化畸變。SR算法經(jīng)過一定步數(shù)的迭代,基本沒有下探的空間。而JCO-MSVQ算法則能繼續(xù)優(yōu)化碼本,獲得更好的量化效果。并且,與SR算法不同,JCO-MSVQ算法中量化畸變是單調(diào)遞減的,因在訓(xùn)練過程中每一步都是最優(yōu)的(簡化算法中是多進(jìn)制搜索,因而是次優(yōu)的)。
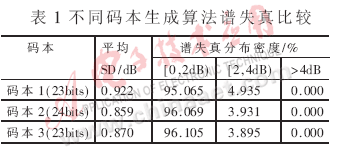
統(tǒng)計(jì)量化譜失真,聯(lián)合碼本優(yōu)化MSVQ比其他的MSVQ有明顯的改善。在同一個(gè)LSF量化器中分別采用23bits SR碼本(碼本1)、24bits SR碼本(碼本2)和23bits聯(lián)合優(yōu)化碼本(碼本3),測試語音為一個(gè)3.5MB的語音文件,既有男聲也有女聲,共11348幀LSF參數(shù)。統(tǒng)計(jì)量化譜失真得到表1所示數(shù)據(jù)。
從表1數(shù)據(jù)可以看到,同是23bits的量化,聯(lián)合碼本設(shè)計(jì)MSVQ與應(yīng)用SR算法生成碼本的MSVQ相比較,有大約1個(gè)比特的改善,接近于應(yīng)用SR算法24bits量化的效果。甚至優(yōu)于文獻(xiàn)[2]中MSVQ算法的26bits量化(平均譜失真0.93dB)。平均譜失真為0.87dB,大于4dB的譜失真統(tǒng)計(jì)為0,達(dá)到了透明量化的要求。
本文研究結(jié)果已經(jīng)成功應(yīng)用于1/2kbps可變速率聲碼器項(xiàng)目中。
參考文獻(xiàn)
1 Itakura F. Line spectrum representation of linear predictive coefficients of speech signals [J]. J.Acoust.Soc.Amer.,1975; 57:S35
2 Paliwal K K, Atal B S. Efficient vector quantization of LPC parameters at 24 bits/frame [J]. Proc. ICASSP,1991:661~664
3 Juang B H, Gray A H. Multiple stage vector quantization for speech coding[J]. Proc.ICASSP,1982:597~600
4 Anderson J, Bodie J. Least square quantization in PCM [J]. IEEE Trans. Inform. Theory, 1975;IT-21:379~387
5 Chan W Y, Gupta S, Gersho A. Enhanced Multistage Vector Quantization by Joint Codebook Design [J]. IEEE Transations on Communications, 1992;40(11):1693~1697
6 Gardner W R, Rao B D. Theoretical Analysis of the HighRate Vector Quantization of LPC Parameters [J]. IEEE Transactions on Speech and Audio Processing,1995;3(5):367~381
7 楊行峻, 遲惠生.語音信號(hào)數(shù)字處理 [M]. 北京:電子工業(yè)出版社, 1995