
文獻(xiàn)標(biāo)識碼: A
說話人識別是從說話人的一段語音中提取出說話人的個性特征,通過對這些個性特征的分析和識別,從而達(dá)到對說話人進(jìn)行辨認(rèn)或者確認(rèn)的目的。它可以分為兩個范疇:說話人辨認(rèn)和說話人確認(rèn)。說話人辨認(rèn)是辨認(rèn)出待識別的語音是來自待考察的個人中的哪一個;而說話人確認(rèn)則是特定的參考模型和待識別模式之間的比較,系統(tǒng)只做出“是”或“不是”的二元判決[1]。
Ville Hautamaki[2]等人提出了最大后驗概率矢量量化(VQ-MAP)過程,它可以看作是GMM-MAP的一種特殊形式;Suykens等人[3]提出了最小二乘支持向量機LS-SVM的概念,而志平等人[4]將最小二乘向量機應(yīng)用在說話人識別系統(tǒng)中,并取得了較好的效果。
VQ-MAP過程首先只依照均值對通用背景模型UBM(Universal Bakground Model)進(jìn)行聚類,然后應(yīng)用VQ-MAP過程來更新自適應(yīng)參數(shù),由此訓(xùn)練語音未覆蓋到的部分就可以用UBM中說話人無關(guān)的特征分布近似,以減小訓(xùn)練語音太短帶來的影響。將得到的自適應(yīng)參數(shù)集作為最小二乘向量機的訓(xùn)練樣本,在說話人識別中進(jìn)行應(yīng)用,取得了較好的效果。本文介紹了VQ-MAP和LS-SVM融合的說話人識別系統(tǒng),并在說話人識別中進(jìn)行了應(yīng)用。
1 VQ-MAP過程
在說話人識別中,可以使用訓(xùn)練集中的發(fā)音數(shù)據(jù)對UBM進(jìn)行參數(shù)自適應(yīng)來得到發(fā)音人的模型。高斯混合模型在最大后驗概率自適應(yīng)(GMM-MAP)過程中需要更新3種參數(shù):權(quán)值、均值向量和協(xié)方差矩陣。VQ-MAP過程是GMM-MAP的一種特殊形式,它只依照均值向量來得到新的自適應(yīng)說話人模型。依照均值向量為參數(shù)用K均值聚類算法對UBM進(jìn)行聚類,從而得到一組均值核心矢量:
2 最小二乘支持向量機[3-4]
Suykens等人[3]在SVM的優(yōu)化函數(shù)中引入方差項,并將SVM中的不等式約束條件改為等式約束,提出了一種以二次等式約束條件為基礎(chǔ)的改進(jìn)型向量機即最小二乘向量機(LS-SVM)。這樣LS-SVM的求解問題從標(biāo)準(zhǔn)SVM的二次函數(shù)尋優(yōu)問題轉(zhuǎn)換為線性方程求解問題, 解決了二次尋優(yōu)算法費時且不易用于實時數(shù)據(jù)處理的問題,從而大大地簡化了問題的復(fù)雜性[4]。
方程的最優(yōu)性條件如下:

3 融合算法
3.1選擇樣本
設(shè)計1個SVM,分別標(biāo)記這2個說話人自適應(yīng)參數(shù)集為{+ 1,- 1}類,將每幀測試語音特征矢量輸入到1個訓(xùn)練支持向量機中,對每幀矢量判別是哪一類,當(dāng)所有的測試語音特征矢量判別完畢后, 采用投票方法判決,得票最多者就為目標(biāo)說話人。
實驗1:同一語音庫下,隨著說話人人數(shù)的變化,VQ-MAP和LS-SVM融合的說話人識別系統(tǒng)與基于LS-SVM的說話人識別系統(tǒng)中SVM訓(xùn)練時間進(jìn)行對比,兩個系統(tǒng)中LS-SVM均采用徑向基核函數(shù),取γ=0.125,結(jié)果如圖1所示。
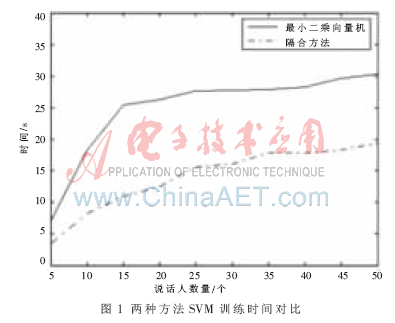
由圖1可以看出,隨著說話人數(shù)越多,所需SVM訓(xùn)練時間越長。當(dāng)說話人數(shù)為50時,應(yīng)用VQ-MAP和SVM融合的系統(tǒng)SVM訓(xùn)練時間僅僅是直接用LS-SVM訓(xùn)練時間的36.6%。這是因為直接用LS-SVM時,把每個說話人所有幀的特征向量都作為輸入矢量來訓(xùn)練SVM,而在VQ-MAP和LS-SVM融合方法中,只把VQ-MAP自適應(yīng)更新模型中的K個向量作為輸入矢量訓(xùn)練SVM,大大減少了運算量,因而提高了識別速度。
實驗2:同一語音庫下,VQ-MAP和LS-SVM融合的說話人識別系統(tǒng)與基于LS-SVM的說話人識別系統(tǒng)識別率進(jìn)行對比,比較結(jié)果如表1所示。
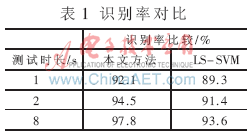
從表1可以看出,隨著測試時長的增加, VQ-MAP和LS-SVM融合方法識別率不斷提高,且明顯高于LS-SVM方法。這是因為在VQ-MAP算法中,采用了均值矢量通過UBM進(jìn)行自適應(yīng)來得到說話人模型,在訓(xùn)練語音未覆蓋到的部分就可以用UBM中說話人無關(guān)的特征分布近似,減小訓(xùn)練語音太短帶來的影響,從而為提高識別率打下良好的基礎(chǔ)。
本文介紹的VQ MAP和LS-SVM融合說話人識別系統(tǒng),比直接應(yīng)用LS-SVM訓(xùn)練效率提高了36.6%,且識別率也高于LS-SVM方法,尤其是在測試時長為8 s時,比傳統(tǒng)的LS-SVM方法識別率提高了4.2%,為在說話人識別系統(tǒng)中使用多系統(tǒng)融合提供了新的途徑,是一種行之有效的方法。
參考文獻(xiàn)
[1] 趙力.語音信號處理[M]. 北京:機械工業(yè)出版社,2003.
[2] HAUTAMAKI V, KINNUNEN T, KARKKAINEN I. Maximum a posteriori adaptation of the centroid Model for Speaker Verification[J]. IEEE Signal Process. Lett.2008,15:162-165.
[3] SUYKENS J K, VANDEWALLE J. Least squares support vector machine classifiers[J].Neural Processing Letter,1999,9(3):293-300.
[4] 但志平,鄭勝. 基于最小二乘向量機的說話人識別研 究[J]. 計算機工程與應(yīng)用,2007(7):49-51.
[5] 趙虹,韋麗華.基于支持向量機的說話人識別研究[J].現(xiàn)代電子技術(shù),2008(6):123-127.