
摘 要: 提出了半像素運(yùn)動估計(jì)" title="運(yùn)動估計(jì)">運(yùn)動估計(jì)算法的硬件實(shí)現(xiàn)方案,該方案可有效地提高視頻編碼的速度,耗費(fèi)較低的硬件資源,減小處理器的面積。
關(guān)鍵詞: 半像素運(yùn)動估計(jì) 視頻壓縮
1 運(yùn)動估計(jì)和運(yùn)動補(bǔ)償
在視頻壓縮編碼中,當(dāng)編碼器對圖像序列中的第N幀進(jìn)行處理時,利用運(yùn)動補(bǔ)償中的核心技術(shù)——運(yùn)動估值ME(Motion Estimation),得到第N幀的預(yù)測幀N’。在實(shí)際編碼傳輸時,并不總是傳輸?shù)贜幀,而是第N幀與其預(yù)測幀N’的差值⊿。如果運(yùn)動估計(jì)十分有效,⊿中的概率基本上分布在零的附近,從而導(dǎo)致⊿比原始圖像第N幀的能量小得多,編碼傳輸⊿所需的比特?cái)?shù)也就少得多。這就是運(yùn)動補(bǔ)償技術(shù)能夠去除信源中時間冗余度的本質(zhì)所在[5]。
2 整像素運(yùn)動估計(jì)
在獲得運(yùn)動矢量的方法上有著很多的標(biāo)準(zhǔn)和技術(shù)。其中平均絕對誤差MAE(Mean Absolute Error)在精確程度和計(jì)算復(fù)雜度之間是一個很好的折衷(還有很多其他的標(biāo)準(zhǔn),例如:CCF、MSE、SAD、SAD summation truncation、SAD estimation、PDC、MME、RBMAD、ABT、DPC、MADM)。如果使用MAE標(biāo)準(zhǔn),對于一個確定的向量vector (i, j),兩個宏塊" title="宏塊">宏塊之間的偏差定義為:
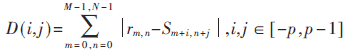
其中r是參考宏塊,s是候選坐標(biāo)宏塊。參考宏塊的大小為M×N, 候選宏塊的大小是(N+2p-1)(M+2p-1)。讓D(i,j)達(dá)到最小的就是運(yùn)動矢量。如果參考宏塊與所有的搜索區(qū)域內(nèi)的候選宏塊比較,這個過程就叫做全局搜索匹配算法FSBMA(full-search block matching algorithm,實(shí)現(xiàn)方法參見文獻(xiàn)[2])。例如,在32×32的搜索塊中,參考宏塊16×16,則共算出289(=17×17)個D(i,j),讓D(i,j)達(dá)到最小的就是運(yùn)動矢量。
3 半像素運(yùn)動估計(jì)
許多視頻應(yīng)用中都會需要一些亞像素運(yùn)動估計(jì),如半像素或者是四分之一像素估計(jì)。分?jǐn)?shù)像素的像素估計(jì)將會有更好的圖像預(yù)測效果。半像素估計(jì)是在先前最好的整數(shù)像素估計(jì)上繼續(xù)操作。搜索區(qū)域是目標(biāo)周圍的區(qū)域。像素值的插值" title="插值">插值由周圍的在這個范圍中間的像素一起計(jì)算得到。插值中一般采用線性插值" title="線性插值">線性插值的方法。圖1是H.263標(biāo)準(zhǔn)的內(nèi)差法公式。
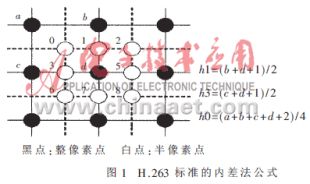
計(jì)算出整像素最優(yōu)的運(yùn)動矢量后,在其附近進(jìn)行插值,然后再比較得出的新最優(yōu)的運(yùn)動矢量。流程如下:
·從前一個模塊輸入計(jì)算得到的整像素的運(yùn)動矢量;
·在此運(yùn)動矢量附近進(jìn)行半像素插值" title="像素插值">像素插值,插值時只需要原先最優(yōu)的宏塊和這個宏塊周圍的一圈像素來進(jìn)行插值。 這樣除了原先的宏塊,另外在每個像素點(diǎn)的附近又插值出8個半像素點(diǎn),這些對應(yīng)的半像素點(diǎn)構(gòu)成了8個相同規(guī)模的宏塊;
·在插值后,將新的8個模塊與原始參考模塊進(jìn)行比較,計(jì)算出8個SAD(累計(jì)誤差和)。然后比較出最優(yōu)的匹配宏塊,輸出計(jì)算結(jié)果。 最后再將最優(yōu)的與原先整像素的最優(yōu)比較,輸出其中最優(yōu)的結(jié)果。
4 VLSI實(shí)現(xiàn)
本設(shè)計(jì)提出的計(jì)算半像素運(yùn)動估計(jì)的體系結(jié)構(gòu)中,設(shè)所使用的參考宏塊為(N-2)×(N-2)的像素矩陣,那么經(jīng)過全搜索方式得到最佳匹配模塊后,再經(jīng)邊緣擴(kuò)展,共有N×N個整像素點(diǎn),這些像素點(diǎn)作為半像素插值模塊的輸入數(shù)據(jù),逐行串行輸入進(jìn)行處理。本文具體討論半像素插值和半像素運(yùn)動估計(jì)的硬件實(shí)現(xiàn),對于前級的整像素運(yùn)動估計(jì)和邊緣擴(kuò)展的實(shí)現(xiàn)方法不作具體討論。
本文所提出的體系結(jié)構(gòu)如圖2、圖3所示,模塊P為線性插值模塊,將兩個輸入數(shù)據(jù)的線性插值輸出。P’的輸出為兩輸入數(shù)據(jù)的中值,P’是通過已得到的縱向插值來計(jì)算斜向插值的模塊。在線性插值的計(jì)算中,對橫向插值、縱向插值和斜向插值分別計(jì)算,其中Hor_Mem存放橫向插值(如圖1中的點(diǎn)3,5),該存儲器的深度為(N-2)×(N-1);Ver_Mem存放縱向插值(如圖1中的點(diǎn)1,7),該存儲器的深度為(N-1)×(N-2);Diag_Mem存放斜向插值(如圖1中的點(diǎn)0,2,6,8),該存儲器的深度為(N-1)×(N-1)。

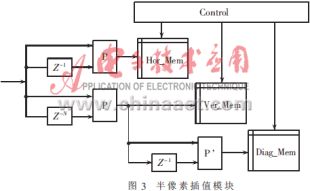
原始的N×N個整像素點(diǎn)逐行串行輸入橫向插值模塊,該模塊將每兩個相鄰像素點(diǎn)的線性插值輸出,結(jié)果存到Hor_Mem中。但每行(即N個像素點(diǎn))輸入結(jié)束時,最后一個線性插值結(jié)果應(yīng)該忽略,因?yàn)樵撝凳怯杀拘凶詈笠粋€點(diǎn)和下一行的第一個點(diǎn)插值而來,這個值是沒有意義的,并且在插值結(jié)果中,第一行和最后一行也應(yīng)舍棄掉,因?yàn)樗鼈儾皇前胂袼夭逯迭c(diǎn)。反映到數(shù)據(jù)流中,這個過程就是將開始的連續(xù)N個輸出結(jié)果丟棄,然后每N個點(diǎn)舍棄一個點(diǎn),最后將結(jié)束的連續(xù)N點(diǎn)丟棄。這個過程可以通過Control模塊來控制Hor_Mem的write_enable完成。
對于縱向插值,可以這樣得到:不難想象,縱向插值即為當(dāng)前像素點(diǎn)與該點(diǎn)前面的第N個點(diǎn)的插值,這樣可以對輸入數(shù)據(jù)做N個時鐘周期的延遲,再與當(dāng)前像素點(diǎn)作線性插值。對于這個插值結(jié)果,同樣需要丟棄一些數(shù)據(jù)。首先,開始的N個插值結(jié)果需要丟棄,因?yàn)檩斎氲牡谝恍袛?shù)據(jù)的前面N個值是不存在的,所以這N個插值結(jié)果是沒有意義的。對于插值結(jié)果的首尾兩列也應(yīng)舍棄掉,因?yàn)樗鼈儾皇前胂袼夭逯迭c(diǎn)。反映到數(shù)據(jù)流中,這個過程就是將開始的連續(xù)N個輸出結(jié)果丟棄,然后每N個點(diǎn)舍棄首尾兩點(diǎn)。這個過程同樣由Control來控制。
對于斜向插值,其計(jì)算公式為h0=(a+b+c+d+2)/4,將其變換成h0=((a+b+1)/2+(c+d+1)/2)/2。于是不難發(fā)現(xiàn),斜向插值即為與其相鄰的兩個縱向(或橫向)插值結(jié)果的中值,這里選用縱向插值作為輸入,因?yàn)檫B續(xù)兩個縱向插值即可求出一個斜向插值來,這樣只要將縱向插值結(jié)果串行輸入到P’模塊即可。同樣,對于輸入到Diag_Mem存儲器中的數(shù)據(jù),同樣需要取舍:首先前N個縱向插值沒有意義,那么前N個斜向插值自然也會舍掉,然后每行的最后一個中值結(jié)果也要舍掉。因?yàn)檫@個結(jié)果是隔行算出的中值結(jié)果,顯然沒有意義。
這樣所有的插值結(jié)果都已經(jīng)計(jì)算出來并存在三個存儲器中,那么接下來就可以計(jì)算這些半像素插值的累計(jì)誤差和(SAD),其中通過Hor_Mem算出2個水平運(yùn)動的SAD,Ver_Mem算出2個垂直運(yùn)動的SAD,Diag_Mem算出4個斜向運(yùn)動的SAD。對于計(jì)算SAD的過程,有兩種選擇,可以用一個計(jì)算累計(jì)誤差和的模塊順序逐一計(jì)算出這8個SAD,這樣做可以節(jié)省硬件資源,但是缺點(diǎn)也很明顯,輸出結(jié)果要等到8個SAD計(jì)算完之后才能輸出,延遲過長,影響整體編碼的速度和效率。相應(yīng)地,還可以用多個SAD模塊并行計(jì)算累計(jì)誤差和,對水平、垂直、斜向的累計(jì)誤差和分別同時計(jì)算,這樣提高了編碼效率,但這是以硬件資源為代價的。總之,在計(jì)算完插值后,作半像素運(yùn)動估計(jì)時,要根據(jù)具體的應(yīng)用需求和硬件資源進(jìn)行相應(yīng)的取舍。
5 關(guān)于存儲器
對于存儲器的設(shè)計(jì),同樣面臨兩種選擇:一是選擇單口RAM,這樣只有等到半像素插值點(diǎn)全部計(jì)算完畢并且已經(jīng)存在三個存儲器中,才可以讀取RAM中的數(shù)據(jù)來計(jì)算接下來的8個累計(jì)誤差和,這樣做對于單口RAM的設(shè)計(jì)來說,實(shí)現(xiàn)起來比較簡單,可以節(jié)省硬件資源,但是同樣也會帶來較大的時間延遲;二是選擇雙口RAM,這樣對三個存儲器的讀寫可同時進(jìn)行,隨著半像素插值點(diǎn)不斷存入存儲器,累計(jì)誤差和模塊同時也在對已有的半像素插值點(diǎn)計(jì)算累計(jì)誤差和。這樣實(shí)現(xiàn)了流水線設(shè)計(jì),減小了整體延時,當(dāng)然這仍舊是以硬件資源為代價的。首先雙口RAM的邏輯設(shè)計(jì)要比單口RAM消耗更多的邏輯資源,而且累計(jì)誤差和模塊要通過復(fù)制來并行處理三個存儲器中的數(shù)據(jù),這些都會增加硬件的負(fù)擔(dān)。
既然兩種方法利弊明顯,筆者在這里提出一種折衷的方案:設(shè)算出一個累計(jì)誤差和的時間為TS,那么從4個斜向運(yùn)動估計(jì)的累計(jì)誤差和的計(jì)算總共需要4TS的時間、而水平、垂直運(yùn)動的累計(jì)誤差和分別只需要2TS的時間,那么即使采用流水線的實(shí)現(xiàn)方案,也要等到4個斜向SAD算出之后才能對8個SAD值做出比較。也就是說,有水平、垂直的累計(jì)誤差和模塊要閑置2TS的時間,硬件資源的利用率沒有得到完全發(fā)揮。于是采用一種折衷的方案,Hor_Mem、Diag_Mem采用雙口RAM,以流水線的方式完成累計(jì)誤差和的計(jì)算,而Ver_Mem則采用單口RAM的方式實(shí)現(xiàn),并且水平垂直的累計(jì)誤差和的計(jì)算將復(fù)用同一個模塊,即先算出水平運(yùn)動的2個SAD,然后再算垂直運(yùn)動的2個SAD,這樣可以與斜向運(yùn)動的4個SAD值的計(jì)算同步完成。
6 時序分析
原始的N×N個整像素點(diǎn)矩陣串行輸入,這要花費(fèi)N2個時鐘周期,半像素插值點(diǎn)的計(jì)算是隨著整像素點(diǎn)的輸入同時進(jìn)行的,在這N×N個數(shù)據(jù)輸入結(jié)束時,所有的半像素插值點(diǎn)也已經(jīng)計(jì)算完畢,存儲在三個Mem中。接下來的時序要根據(jù)運(yùn)動估計(jì)模塊來分析,如果只用一個計(jì)算累計(jì)誤差和的模塊逐一計(jì)算這8個SAD,假定每個模塊耗時(N-1)2個時鐘周期,那么整個過程總共耗時N2+8×(N-1)2個時鐘周期。假定時鐘頻率為100MHz,搜索模塊大小為32×32,那么N=34,計(jì)算得到總時間約為0.1ms,完全可以滿足大多數(shù)的視頻壓縮需求。而如果采用雙口RAM,并且通過對累計(jì)誤差和模塊的復(fù)制來提高速度,那么編碼時間還會大大降低。
本文提出了一個實(shí)現(xiàn)半像素運(yùn)動估計(jì)的VLSI的體系結(jié)構(gòu),這個算法模型包括:累計(jì)誤差和模塊、線性插值模塊,控制模塊(即存儲器的地址發(fā)生器)和三個存儲器模塊、每個模塊的實(shí)現(xiàn)都很簡單,只需要一些加法器、計(jì)數(shù)器、移位操作和一些簡單的控制電路。本設(shè)計(jì)方案已經(jīng)用行為級verilog實(shí)現(xiàn)成功,綜合后的工作頻率為200MHz,其關(guān)鍵路徑由存儲器的數(shù)據(jù)訪問速度決定。
參考文獻(xiàn)
1 T. Toivonen. Number Theoretic Transform -Based Block Mo-tion Estimation. Master′s Thesis. University of Oulu.Finland (2002)
2 H. A. Mahmoud, M. Bayoumi.A Low Power Architecture for a New Efficient Block-Matching Motion Estimation Algo-rithm. Proceedings of International Conference on Communi-cation Technology 2,2000:1173~1179
3 Y. Naito, T. Miyazaki, I. Kuroda. A Fast Full-Search Motion Estimation Method for Programmable Processors with a Multiply-Accumulator. IEEE Int. Conf. on Acoustics, Speech, and Signal Processing, 1996:3221~3224
4 Uwe Meyer-Baese, Digital Signal Processing with Field Pro-grammable Gate Arrays,2001
5 張益貞,劉 滔.Visual C++實(shí)現(xiàn)MPEG/JPEG編解碼技術(shù).北京:人民郵電出版社, 2002