
實(shí)時(shí)圖像處理系統(tǒng)中DMA控制器的設(shè)計(jì)和驗(yàn)證
2007-10-17
作者:謝 俊,趙 峰
摘 要: 在分析傳統(tǒng)DMA控制器結(jié)構(gòu)的基礎(chǔ)上,針對(duì)實(shí)時(shí)圖象處理系統(tǒng)的數(shù)據(jù)傳輸要求,提出了多端口模塊設(shè)計(jì)、增加Round Robin通道優(yōu)先級(jí)仲裁算法和優(yōu)化數(shù)據(jù)傳輸通道等優(yōu)化方法,以提高數(shù)據(jù)傳輸速度,并改進(jìn)了地址產(chǎn)生模式來滿足圖像算法的要求。
關(guān)鍵詞: DMA 實(shí)時(shí)圖像處理? 多端口? Round-Robin策略? 地址產(chǎn)生模塊
?
數(shù)字圖像處理是嵌入式系統(tǒng)最為廣泛的應(yīng)用之一。目前,數(shù)字圖像處理技術(shù)無論在科學(xué)研究、工業(yè)生產(chǎn)或管理部門中都得到越來越多的應(yīng)用。而目標(biāo)跟蹤、機(jī)器人導(dǎo)航、自動(dòng)駕駛、交通監(jiān)視等應(yīng)用也極大地促進(jìn)了實(shí)時(shí)圖像處理技術(shù)的發(fā)展。
數(shù)字圖像處理的特點(diǎn)是數(shù)據(jù)量大、運(yùn)算復(fù)雜、實(shí)時(shí)性強(qiáng)。通常,數(shù)據(jù)量往往大于片內(nèi)的存儲(chǔ)容量,對(duì)于片內(nèi)存儲(chǔ)資源有限的處理系統(tǒng)來說,一般需要借用外部存儲(chǔ)空間。為了提高系統(tǒng)的實(shí)時(shí)處理能力,必須在片內(nèi)高速存儲(chǔ)區(qū)和外部存儲(chǔ)空間之間使用直接存儲(chǔ)方式(DMA)進(jìn)行數(shù)據(jù)交換,從而使處理器只專注于數(shù)據(jù)的計(jì)算。
1 傳統(tǒng)DMA控制器的設(shè)計(jì)和分析
1.1 DMA控制器的模塊結(jié)構(gòu)
DMA控制器一般具有如下功能:在不同的存儲(chǔ)介質(zhì)" title="存儲(chǔ)介質(zhì)">存儲(chǔ)介質(zhì)之間實(shí)現(xiàn)快速數(shù)據(jù)傳輸;獨(dú)立于處理器進(jìn)行高速數(shù)據(jù)交換;提供多個(gè)DMA通道以提高數(shù)據(jù)傳輸?shù)牟⑿卸龋恢С謹(jǐn)?shù)據(jù)爆發(fā)傳輸模式;具有通道優(yōu)先級(jí)可編程的仲裁機(jī)制。

?
圖1是DMA控制器的模塊框圖。從圖中可以看出,DMA控制器主要由以下幾個(gè)模塊組成:
(1)寄存器控制模塊" title="控制模塊">控制模塊:為軟件程序員提供可編程接口,以控制DMA的工作狀態(tài);根據(jù)各配置位的不同設(shè)置,控制各DMA通道和各端口的工作狀態(tài)。
(2)通道控制模塊:DMA控制器中有6個(gè)可以獨(dú)立工作的DMA通道,根據(jù)相應(yīng)控制寄存器" title="控制寄存器">控制寄存器的配置位提出DMA申請(qǐng),通過端口模塊訪問存儲(chǔ)介質(zhì)。
(3)端口控制模塊:它是DMA控制器與存儲(chǔ)介質(zhì)之間的接口模塊,提供訪問存儲(chǔ)介質(zhì)的地址、數(shù)據(jù)和控制信號(hào)線。
(4)FIFO控制模塊:DMA控制器中共有6個(gè)32字節(jié)的緩存隊(duì)列,分別為每個(gè)通道所占用,在爆發(fā)式的傳輸中,可以緩存慢速存儲(chǔ)設(shè)備中的數(shù)據(jù),從而提高DMA控制器的傳輸速度。
(5)通道優(yōu)先級(jí)仲裁模塊:當(dāng)多個(gè)DMA通道同時(shí)提出DMA申請(qǐng)時(shí),需要進(jìn)行通道的優(yōu)先級(jí)仲裁,在這里使用硬件優(yōu)先級(jí)仲裁。
此外,還有中斷和事件響應(yīng)模塊,用以保證DMA的實(shí)時(shí)傳輸。
1.2 傳統(tǒng)DMA在實(shí)時(shí)圖像處理應(yīng)用中的局限
首先,在傳統(tǒng)的DMA設(shè)計(jì)[1-2]中,端口模塊只采用一組數(shù)據(jù)線、地址線和控制線,連接DMA需要連接的所有存儲(chǔ)介質(zhì);并且當(dāng)多個(gè)通道需要同時(shí)占用數(shù)據(jù)線、地址線和控制線時(shí),只采用硬件優(yōu)先級(jí)仲裁的方式來處理。這樣,對(duì)于大量DMA應(yīng)用的實(shí)時(shí)圖像處理系統(tǒng)" title="實(shí)時(shí)圖像處理系統(tǒng)">實(shí)時(shí)圖像處理系統(tǒng),DMA的傳輸效率并不高,影響了整個(gè)系統(tǒng)的圖像處理效果。所以,需要對(duì)DMA的端口模塊和優(yōu)先級(jí)仲裁模塊做一些改進(jìn),以便有效地改善DMA的數(shù)據(jù)傳輸速率。而且,DMA的數(shù)據(jù)傳輸路徑也可以改進(jìn)。
其次,圖像數(shù)據(jù)本身的一些格式特點(diǎn)和所要求的圖像處理算法決定了一個(gè)實(shí)時(shí)圖像處理系統(tǒng)中的數(shù)據(jù)傳輸并不是一種簡(jiǎn)單的數(shù)據(jù)傳輸,而是要求DMA的數(shù)據(jù)傳輸同時(shí)具有矩陣傳輸、翻轉(zhuǎn)傳輸?shù)裙δ埽瑏砑涌靾D像處理的速度和滿足一些圖像處理算法的要求。而普通DMA的地址產(chǎn)生模塊并沒有這樣的設(shè)計(jì)。
2 DMA控制器的優(yōu)化
2.1 端口模塊
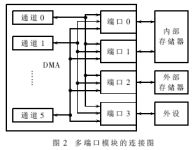
本文實(shí)現(xiàn)的DMA控制器中,DMA控制器支持多端口模式,可以在各個(gè)存儲(chǔ)介質(zhì)之間進(jìn)行數(shù)據(jù)的并行傳輸。通過增加一些硬件復(fù)雜度,大大提高了系統(tǒng)數(shù)據(jù)傳輸?shù)牟⑿卸取?BR>圖2為DMA控制器的端口模塊連接圖。DMA控制器通過4個(gè)端口連接內(nèi)部存儲(chǔ)器、外部存儲(chǔ)器和外部設(shè)備。通道和端口相互獨(dú)立,每個(gè)通道可以獨(dú)立申請(qǐng)占用端口資源。端口將各個(gè)通道產(chǎn)生的控制、地址和數(shù)據(jù)信號(hào)通過多路選擇連接到端口對(duì)應(yīng)的存儲(chǔ)介質(zhì)。當(dāng)多個(gè)通道同時(shí)收到DMA請(qǐng)求時(shí),如果所訪問的端口不沖突,則每個(gè)通道可以各自獨(dú)立地通過所訪問的端口資源進(jìn)行DMA傳輸,從而提高DMA數(shù)據(jù)傳輸?shù)男省?/P>
2.2 通道優(yōu)先級(jí)仲裁模塊
如果考慮通道對(duì)端口的訪問可能產(chǎn)生沖突,則需要引入通道優(yōu)先級(jí)仲裁的設(shè)計(jì)。在實(shí)際的系統(tǒng)應(yīng)用中,每個(gè)DMA通道的請(qǐng)求對(duì)實(shí)時(shí)性要求是不同的。因此,通常的DMA控制器中都集成有通道硬件優(yōu)先級(jí)的設(shè)計(jì)[1,2],有效地為各DMA通道的資源請(qǐng)求服務(wù)。對(duì)實(shí)時(shí)性要求較高的DMA通道請(qǐng)求,將通道優(yōu)先級(jí)設(shè)為最高,而對(duì)數(shù)據(jù)量大且實(shí)時(shí)性無特殊要求的DMA通道請(qǐng)求,將通道優(yōu)先級(jí)設(shè)為最低。優(yōu)先級(jí)高的通道優(yōu)先占用端口資源。但是這樣簡(jiǎn)單的設(shè)計(jì),只是讓各個(gè)通道去排隊(duì)占用端口資源,在通道優(yōu)先級(jí)相同的情況下,需要等到一個(gè)通道的所有數(shù)據(jù)傳輸結(jié)束后,下一個(gè)通道才能占用端口資源,這使整個(gè)系統(tǒng)的處理效率降低。
引入相同優(yōu)先級(jí)的通道,能夠分時(shí)共享端口資源,本文采用Round-Robin策略實(shí)現(xiàn)這種分時(shí)共享機(jī)制[4]。端口對(duì)于相同優(yōu)先級(jí)的通道請(qǐng)求,根據(jù)Round-Robin仲裁算法,輪流響應(yīng)各個(gè)DMA通道的傳輸請(qǐng)求,讓相同優(yōu)先級(jí)的通道可以分時(shí)工作,避免某個(gè)通道占用端口資源時(shí)間過長(zhǎng),以提高系統(tǒng)的傳輸效率。
圖3為DMA通道優(yōu)先級(jí)的仲裁策略。每個(gè)通道的優(yōu)先級(jí)由控制寄存器的相應(yīng)位設(shè)定。通道的請(qǐng)求信號(hào)為chanx_req,根據(jù)通道的優(yōu)先級(jí)產(chǎn)生高優(yōu)先級(jí)請(qǐng)求信號(hào)cx_req_h和低優(yōu)先級(jí)請(qǐng)求信號(hào)cx_req_l。
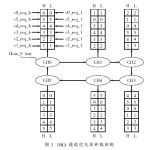
優(yōu)先級(jí)仲裁模塊的通道輪詢機(jī)制使用狀態(tài)機(jī)實(shí)現(xiàn)。狀態(tài)機(jī)共有6個(gè)狀態(tài),分別為選中通道0~5的狀態(tài)。每個(gè)狀態(tài)都包含一個(gè)通道優(yōu)先級(jí)的排序隊(duì)列。各個(gè)通道根據(jù)高優(yōu)先級(jí)請(qǐng)求信號(hào)cx_req_h和低優(yōu)先級(jí)請(qǐng)求信號(hào)cx_req_l進(jìn)入通道優(yōu)先級(jí)排序隊(duì)列的相應(yīng)位置,從高到低排序。沒有請(qǐng)求的通道不參加排序。例如通道0、2、4有cx_req_h,通道1、3有cx_req_l,通道5沒有請(qǐng)求信號(hào)。若當(dāng)前狀態(tài)為選中通道0,排序的結(jié)果為2-4-0-1-3;若當(dāng)前狀態(tài)為選中通道2,排序的結(jié)果為4-0-2-3-1。
狀態(tài)機(jī)在當(dāng)前正在進(jìn)行的數(shù)據(jù)傳輸結(jié)束后,根據(jù)當(dāng)前通道的優(yōu)先級(jí)排序隊(duì)列進(jìn)行優(yōu)先級(jí)仲裁,跳轉(zhuǎn)到通道優(yōu)先級(jí)排序隊(duì)列中排隊(duì)最靠前的通道所對(duì)應(yīng)的狀態(tài),從而產(chǎn)生選中通道的選中信號(hào)。
從圖3中可以看出,不同狀態(tài)的通道優(yōu)先級(jí)排序隊(duì)列可以保證狀態(tài)機(jī)的跳轉(zhuǎn)按一個(gè)硬件優(yōu)先級(jí)加輪詢的方式進(jìn)行。
通過這樣的方式,就可以讓多個(gè)需要訪問同一端口的通道分時(shí)共享端口資源,從而提高整個(gè)系統(tǒng)數(shù)據(jù)傳輸?shù)牟⑿卸取?BR>2.3 通道數(shù)據(jù)傳輸路徑
DMA通道的數(shù)據(jù)傳輸分為單個(gè)傳輸和爆發(fā)傳輸兩種類型。
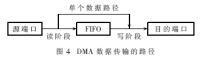
在通常的DMA控制器設(shè)計(jì)中,每個(gè)通道通過一個(gè)FIFO緩存讀入數(shù)據(jù)。在讀訪問階段,數(shù)據(jù)從源端口傳輸?shù)酵ǖ赖腇IFO中;在寫訪問階段,數(shù)據(jù)從通道的FIFO傳輸?shù)侥康亩丝凇_@樣,當(dāng)端口連接的存儲(chǔ)介質(zhì)為慢速設(shè)備時(shí),可以大大提高DMA通道的傳輸速度。但是當(dāng)通道的傳輸類型為單個(gè)傳輸時(shí),如果傳輸?shù)臄?shù)據(jù)還要經(jīng)過FIFO緩存,則每個(gè)數(shù)據(jù)單元的傳輸至少浪費(fèi)1個(gè)時(shí)鐘周期,因此對(duì)數(shù)據(jù)通路要進(jìn)行適當(dāng)?shù)膬?yōu)化。
DMA數(shù)據(jù)傳輸?shù)穆窂饺鐖D4所示。當(dāng)傳輸類型為單個(gè)傳輸時(shí),增加一個(gè)數(shù)據(jù)單元的前向反饋路徑,數(shù)據(jù)不必經(jīng)過FIFO緩存,從源端口讀到后,直接寫入目的端口中,可以減少1個(gè)時(shí)鐘周期的傳輸延遲。
2.4 地址生成模塊
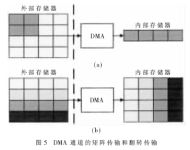
在很多實(shí)時(shí)圖像處理系統(tǒng)的應(yīng)用中(如子圖抽取和圖像翻轉(zhuǎn)等應(yīng)用),DMA通道的數(shù)據(jù)傳輸并不是簡(jiǎn)單的地址遞增、遞減或不變傳輸,而是要求DMA通道以一些特殊的地址增長(zhǎng)模式進(jìn)行傳輸,如圖5(a)所示的矩陣傳輸和圖5(b)所示的翻轉(zhuǎn)傳輸。
當(dāng)DMA數(shù)據(jù)傳輸只是連續(xù)地址(memory)或是不變地址(外設(shè)的FIFO)的數(shù)據(jù)傳輸時(shí),只需要有一種地址調(diào)整方式,即基本調(diào)整方式。基本調(diào)整方式是指地址根據(jù)數(shù)據(jù)字長(zhǎng)和通道控制寄存器的相應(yīng)位來選擇連續(xù)遞增、連續(xù)遞減或不變的方式[2]。而這種方式不支持傳輸數(shù)據(jù)源地址和目的地址不連續(xù)或不變的情況(如圖5所示)。用軟件編程實(shí)現(xiàn)這些功能,會(huì)浪費(fèi)大量的CPU時(shí)間。
本文設(shè)計(jì)的DMA控制器引入了二維數(shù)據(jù)傳輸?shù)乃枷?SUP>[3,4]。為了支持矩陣傳輸和翻轉(zhuǎn)傳輸功能,需要增加另外一種地址調(diào)整方式——索引調(diào)整方式。另外需增加四個(gè)寄存器:幀計(jì)數(shù)寄存器、單元計(jì)數(shù)寄存器、單元索引寄存器和幀索引寄存器。并在通道的控制寄存器中增加指示地址模式的mode位(包括遞增、遞減、不變和索引)。
?索引調(diào)整方式的計(jì)算過程如圖6所示。將傳輸?shù)臄?shù)據(jù)分成二維,一次傳輸?shù)目倲?shù)據(jù)塊由若干個(gè)幀組成,而每個(gè)傳輸幀又由多個(gè)數(shù)據(jù)單元構(gòu)成,每個(gè)數(shù)據(jù)單元根據(jù)控制寄存器中的數(shù)據(jù)字長(zhǎng)可以是字節(jié)、字或是長(zhǎng)字。相應(yīng)的傳輸計(jì)數(shù)寄存器也有兩個(gè),即幀計(jì)數(shù)寄存器和單元計(jì)數(shù)寄存器。與基本調(diào)整方式不同,索引調(diào)整方式可以根據(jù)傳輸?shù)臄?shù)據(jù)單元是否是當(dāng)前幀的最后一個(gè)數(shù)據(jù)單元進(jìn)行不同的地址調(diào)整。單元索引寄存器中存放普通調(diào)整值,幀索引寄存器中存放幀尾調(diào)整值。每一幀除了最后一次數(shù)據(jù)傳輸以外,其余的傳輸都由單元索引決定地址寄存器的增量。如果讀寫的是該幀的最后一個(gè)數(shù)據(jù)單元,則用幀索引做地址調(diào)整。當(dāng)幀計(jì)數(shù)寄存器和單元計(jì)數(shù)寄存器都為0時(shí),DMA傳輸結(jié)束。

雖然這樣的改進(jìn)不會(huì)提高DMA數(shù)據(jù)的傳輸速率,但是可以節(jié)省整個(gè)系統(tǒng)的時(shí)間。如果通過軟件的方式完成矩陣傳輸和翻轉(zhuǎn)傳輸?shù)裙δ芤螅枰獔?zhí)行額外的CPU運(yùn)算時(shí)間。現(xiàn)通過設(shè)置通道寄存器,可以在DMA傳輸?shù)耐瑫r(shí),完成矩陣地址計(jì)算和翻轉(zhuǎn)地址計(jì)算等功能要求,并且不占用額外的CPU時(shí)間,提高了整個(gè)系統(tǒng)的效率。
3 DMA設(shè)計(jì)的驗(yàn)證
為了驗(yàn)證DMA的設(shè)計(jì)是否能滿足實(shí)時(shí)圖像系統(tǒng)的高速實(shí)時(shí)要求,是否能在數(shù)據(jù)傳輸?shù)耐瑫r(shí)完成子圖抽取功能,搭建了一個(gè)運(yùn)動(dòng)小目標(biāo)檢測(cè)" title="小目標(biāo)檢測(cè)">小目標(biāo)檢測(cè)系統(tǒng),系統(tǒng)的框架見圖7。在此系統(tǒng)中,對(duì)DMA設(shè)計(jì)的有效性進(jìn)行測(cè)試。

小目標(biāo)檢測(cè)系統(tǒng)是一個(gè)雙核系統(tǒng)。ARM922T是主處理器,負(fù)責(zé)整個(gè)系統(tǒng)的控制及與外界的數(shù)據(jù)交互。DSP CORE是協(xié)處理器,負(fù)責(zé)運(yùn)動(dòng)小目標(biāo)檢測(cè)算法的運(yùn)算。整個(gè)系統(tǒng)的工作流程:PC機(jī)將采集到的352×288的運(yùn)動(dòng)小目標(biāo)灰度圖數(shù)據(jù)通過100M網(wǎng)線傳送到以太網(wǎng)接口模塊,ARM922T將輸入的數(shù)據(jù)存放到片外的存儲(chǔ)器SRAM,并通知DSP進(jìn)行數(shù)據(jù)處理和傳輸。DSP數(shù)據(jù)處理時(shí)采用片內(nèi)雙緩存機(jī)制,一塊緩存數(shù)據(jù)的運(yùn)算可以部分或全部與另一塊緩存的數(shù)據(jù)在DMA傳輸過程中并行,并由DMA的事件觸發(fā)功能和中斷反饋功能保證數(shù)據(jù)運(yùn)算和數(shù)據(jù)傳輸過程的并行。最后小目標(biāo)檢測(cè)算法檢測(cè)出來的小目標(biāo)的坐標(biāo)值(行和列)反饋到PC機(jī),在PC機(jī)上演示源圖像和結(jié)果圖像。
目前,各模塊的RTL設(shè)計(jì)和基于雙核系統(tǒng)的前端驗(yàn)證均已完成,并且已經(jīng)將此雙核系統(tǒng)成功地移植到FPGA平臺(tái)上。此平臺(tái)的核心單元由Xilinx的virtexⅡ 6000(X2V6000)、spartanⅢ 5000(X3S5000)和Altera的EPXA1(內(nèi)含ARM922T硬核)構(gòu)成。多FPGA互聯(lián)帶來的龐大的可編程邏輯及EPXA1內(nèi)置的ARM Core能真實(shí)地模擬雙核系統(tǒng)環(huán)境。
在PC機(jī)顯示界面上的實(shí)時(shí)顯示速度為25幀/秒,圖像的視覺效果比較理想。在一幀352×288的灰度圖像的處理過程中,從算法運(yùn)算的時(shí)鐘周期數(shù)和DMA數(shù)據(jù)傳輸所耗費(fèi)的時(shí)鐘周期數(shù)對(duì)比來看(見表1),DMA的數(shù)據(jù)傳輸和DSP CORE的算法運(yùn)算幾乎可以完全并行,充分發(fā)揮了DSP的核心運(yùn)算功能。由于此次應(yīng)用的小目標(biāo)檢測(cè)算法并不是一個(gè)運(yùn)算非常復(fù)雜的算法,因此可以說明DMA的傳輸速率達(dá)到了實(shí)時(shí)系統(tǒng)的要求。同時(shí),DSP中運(yùn)行的小目標(biāo)檢測(cè)算法是基于背景比對(duì)的灰度圖算法,每次處理的圖像范圍是7×7的一個(gè)子圖,在DMA傳輸?shù)耐瑫r(shí)進(jìn)行子圖的抽取功能也得到了驗(yàn)證。實(shí)踐證明:本文提出的DMA設(shè)計(jì)結(jié)構(gòu)在實(shí)際的圖像處理系統(tǒng)中完全可以達(dá)到高速實(shí)時(shí)要求,并且可以在傳輸?shù)耐瑫r(shí)滿足子圖抽取等圖像算法的要求。

本文基于實(shí)時(shí)圖像處理系統(tǒng)對(duì)DMA的需求分析,提出了適用于實(shí)時(shí)圖像處理系統(tǒng)中的DMA接口模塊和數(shù)據(jù)傳輸路徑的設(shè)計(jì)與優(yōu)化,并針對(duì)子圖抽取等圖像算法需求改進(jìn)了地址產(chǎn)生模塊的設(shè)計(jì)結(jié)構(gòu)。從FPGA上的驗(yàn)證結(jié)果來看,此DMA設(shè)計(jì)具有高速實(shí)時(shí)性能,同時(shí)也能滿足圖像算法的子圖抽取等需求,完全適用于實(shí)時(shí)圖像處理系統(tǒng)的應(yīng)用。
參考文獻(xiàn)
[1] 史昕蕾,楊軍,陸生禮.嵌入式SoC中的DMA控制器的設(shè)計(jì)與優(yōu)化.電子工程師,2004,(1).
[2] 唐威,劉佑寶,劉軍華.DMA控制器件的設(shè)計(jì)和仿真.微電子學(xué)和計(jì)算機(jī),2002,(12).
[3] 劉書明.Tiger SHARC DSP應(yīng)用系統(tǒng)設(shè)計(jì).北京:電子工業(yè)出版社,2004.
[4] TMS320VC5501/5502 DSP Direct memory access(DMA) controller reference guide.TI,2003.
[5] OPAP5912 Multimedia processor direct memory access(DMA) support reference guide.TI,2003.