
摘 要: 針對(duì)建立數(shù)據(jù)倉庫時(shí)數(shù)據(jù)源存在結(jié)構(gòu)多樣性和語義異質(zhì)性的問題,提出了本體驅(qū)動(dòng)ETL過程的設(shè)計(jì)方法。通過元數(shù)據(jù)抽象以及語義建立本體,并運(yùn)用OWL實(shí)現(xiàn)本體;再根據(jù)局部本體與全局本體之間的關(guān)系建立本體映射;最后運(yùn)用本體映射和本體推理驅(qū)動(dòng)ETL過程。該方法能有效解決數(shù)據(jù)源異構(gòu)問題,并實(shí)現(xiàn)ETL過程的部分自動(dòng)化。
關(guān)鍵詞: ETL;OWL;本體
隨著數(shù)據(jù)挖掘技術(shù)的不斷發(fā)展,數(shù)據(jù)倉庫已經(jīng)能夠有效地將數(shù)據(jù)集成到結(jié)構(gòu)一致的數(shù)據(jù)存儲(chǔ)環(huán)境中,從而使分散、不一致的操作數(shù)據(jù)轉(zhuǎn)換為方便查詢和分析所需的信息。但由于數(shù)據(jù)源具有異構(gòu)性,企業(yè)需要一個(gè)能夠從所有平臺(tái)和環(huán)境中抽取數(shù)據(jù),再將數(shù)據(jù)轉(zhuǎn)換后加入目標(biāo)數(shù)據(jù)倉庫的高效處理過程,這個(gè)過程就是數(shù)據(jù)的抽取、轉(zhuǎn)換、裝載,即ETL(Extract-Transform-Load)。
數(shù)據(jù)源異構(gòu)問題主要表現(xiàn)在:(1)結(jié)構(gòu)的多樣性,如不同的數(shù)據(jù)庫,不同的數(shù)據(jù)類型和不同的概要設(shè)計(jì)等;(2)語義異質(zhì)性,這包括不同的命名定義和不同的表示格式[1]。
基于傳統(tǒng)的XML元數(shù)據(jù)編碼方法的ETL過程已經(jīng)不能很好地解決數(shù)據(jù)源異構(gòu)問題。首先,XML在處理元數(shù)據(jù)語義上存在兩個(gè)問題[2]:(1)同一概念有多種詞匯表示;(2)同一個(gè)詞有多種含義(概念)。因此XML無法對(duì)元數(shù)據(jù)進(jìn)行準(zhǔn)確的描述,這會(huì)直接影響ETL過程的效果。其次,必要的轉(zhuǎn)換和內(nèi)部模式映射依舊依賴手工操作,這不僅費(fèi)時(shí)而且還容易出錯(cuò)。
為此,本文提出了一種本體驅(qū)動(dòng)ETL過程的設(shè)計(jì)方法。
1 ETL和本體論
1.1 ETL概念
ETL是負(fù)責(zé)將數(shù)據(jù)從源加載到目標(biāo)數(shù)據(jù)倉庫的過程,也是構(gòu)建數(shù)據(jù)倉庫的重要環(huán)節(jié)。ETL包括以下三個(gè)過程[3]:(1)抽取,數(shù)據(jù)抽取是捕獲數(shù)據(jù)源的過程,即將數(shù)據(jù)從各種原始的業(yè)務(wù)系統(tǒng)中讀取出來,這是所有工作的前提。(2)轉(zhuǎn)換,按照預(yù)先設(shè)計(jì)的規(guī)則將抽取得到的數(shù)據(jù)進(jìn)行轉(zhuǎn)換、清洗,處理一些冗余、歧義、不完整、違反業(yè)務(wù)規(guī)則的數(shù)據(jù),統(tǒng)一數(shù)據(jù)的粒度,使本來異構(gòu)的數(shù)據(jù)格式統(tǒng)一起來。(3)裝載,將轉(zhuǎn)換后的數(shù)據(jù)按照計(jì)劃增量全部導(dǎo)入到數(shù)據(jù)倉庫中。
ETL作為DW的核心和靈魂,大約占整個(gè)DW項(xiàng)目60%~80%的時(shí)間。在現(xiàn)實(shí)應(yīng)用中ETL的執(zhí)行效率往往成為實(shí)施DW項(xiàng)目的瓶頸,而ETL規(guī)則的設(shè)計(jì)和實(shí)施又是其中工作量最大的部分。
1.2 本體論和OWL
Ontology概念起源于哲學(xué)領(lǐng)域,即“對(duì)世界上客觀存在物的系統(tǒng)描述”。但其明確定義是在1991年由Neches[4]等人引入人工智能領(lǐng)域。其后在1993年Gruber和1997年Borst也給出了Ontology的定義。直到1998年Studer[5]等人在前人基礎(chǔ)上給出了較為廣泛接受的概念,即“Ontology是共享概念模型的明確的形式化規(guī)范說明”,并指出該定義包含四層含義:概念模型(conceptualization)、明確(explicit)、形式化(formal)和共享(share)。此外2001年Hendler[6]也試圖作出解釋。
W3C為本體的開發(fā)提供了一種網(wǎng)絡(luò)本體語言O(shè)WL[7](Web Ontology Language),該語言包含了三種表達(dá)能力依次增強(qiáng)的子語言,即OWL Lite、OWL DL和OWL Full。OWL Lite支持只需要一個(gè)分類層次和簡單約束的用戶;OWL DL 支持需要最強(qiáng)表達(dá)能力的推理系統(tǒng)的用戶,且這個(gè)推理系統(tǒng)必須確保計(jì)算的完全性和可判定性,OWL DL包括了OWL語言的所有語言成分,但使用時(shí)必須符合一定的約束,受到一定的限制;OWL Full支持那些不需要可計(jì)算保證的,但能在完全自由的RDF上進(jìn)行最強(qiáng)描述的用戶,包含OWL的全部語言成分并取消了OWL DL中的限制。
相比于傳統(tǒng)XML,OWL有更豐富的建模原語,能夠表達(dá)語義并描述復(fù)雜邏輯關(guān)系,可以解決XML無法對(duì)元數(shù)據(jù)進(jìn)行準(zhǔn)確描述的問題。而且本體語言還可以通過建立本體映射,并運(yùn)用本體推理來實(shí)現(xiàn)部分必要轉(zhuǎn)換和內(nèi)部模式映射的自動(dòng)化。因此引入本體驅(qū)動(dòng)ETL過程能有效地解決數(shù)據(jù)源異構(gòu)問題,并實(shí)現(xiàn)ETL過程的部分自動(dòng)化。
1.3 本體驅(qū)動(dòng)ETL的一般步驟
運(yùn)用本體理論指導(dǎo)ETL過程的一般步驟為確定領(lǐng)域本體、尋找本體映射以及選擇適當(dāng)?shù)谋倔w推理規(guī)則。具體過程為:
(1)用本體論的理論知識(shí)指導(dǎo)元數(shù)據(jù)的確立,然后運(yùn)用本體語言建立本體。
(2)建立局部本體到全局本體之間的關(guān)系,即本體映射。包括一個(gè)領(lǐng)域基本概念之間的層次關(guān)系,同時(shí)要滿足不同局部本體之間的相互查詢需求。目前有很多種本體映射的方法,如GLUE[8]方法是一種利用概念的實(shí)例作為計(jì)算概念間相似度的依據(jù),然后通過機(jī)器學(xué)習(xí)技術(shù)尋找單獨(dú)分開存儲(chǔ)的概念與自治本體之間的語義映射;SF(Similarity Flooding)[9]是一種基于相鄰概念節(jié)點(diǎn)之間的相似傳遞性的算法;H-MATCH[10]是一種動(dòng)態(tài)分布式本體匹配的算法。
(3)本體推理,即通過一定的規(guī)則推理出本體內(nèi)部或是局部本體與全局本體之間的關(guān)系,來幫助確立映射關(guān)系。KAON2[11]是一個(gè)OWL推理機(jī)制,帶SWRL子集DLsafe擴(kuò)展;Pellet[12]是一個(gè)用Java構(gòu)建的推理機(jī)制,專門為OWL推理設(shè)計(jì)的,這兩種工具都可以用來推理。
(4)將本體推理所得到的映射轉(zhuǎn)化為熟悉的ETL過程。
2 基于本體的ETL架構(gòu)設(shè)計(jì)
在對(duì)本體論和ETL過程研究的基礎(chǔ)上,本文提出了基于本體的ETL架構(gòu)設(shè)計(jì),這一架構(gòu)包括三個(gè)主要階段:(1)元數(shù)據(jù)抽象階段:任務(wù)是從數(shù)據(jù)源中抽取元數(shù)據(jù),然后將元數(shù)據(jù)抽象為本體。它包括局部本體和全局本體的定義。(2)本體映射階段:目的就是找到局部本體和全局本體內(nèi)部以及它們之間的語義關(guān)聯(lián),解決不同本體間的知識(shí)共享和重用使使用者更好地認(rèn)識(shí)結(jié)構(gòu)和語義領(lǐng)域的異構(gòu)。本體映射的方法之一是計(jì)算兩個(gè)本體的相似性。(3)基于ETL規(guī)則的本體推理階段:即根據(jù)ETL的一般規(guī)則來制定本體推理規(guī)則,幫助從映射關(guān)系中找到隱含的與相沖突的之間的關(guān)系。如果數(shù)據(jù)源更傾向于用自動(dòng)化過程開發(fā),則對(duì)映射階段進(jìn)行描述的推理至關(guān)重要,特別是ETL過程。從數(shù)據(jù)源到目標(biāo)數(shù)據(jù)倉庫的ETL過程如圖1所示。
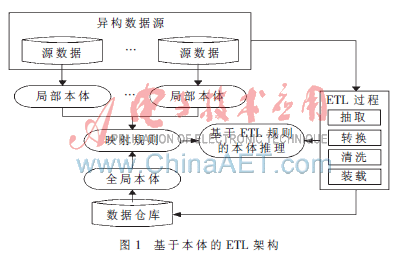
3 本體驅(qū)動(dòng)的ETL過程
假設(shè)有兩個(gè)主要實(shí)體,即客戶和訂單,整個(gè)設(shè)置如表1所示。一個(gè)客戶有一個(gè)名字(包括他/她的姓和名)和相應(yīng)的地址(其中包括他/她的國家、城市和街道)。一個(gè)訂單包括一個(gè)特定的日期,其格式可以為“日/月/年”或“月/日/年”。訂單的價(jià)格有美元和人民幣兩種貨幣表現(xiàn)形式。還有購貨數(shù)量,其訂貨形式為“零售”或“批發(fā)”。而且有兩個(gè)數(shù)據(jù)源分別是以O(shè)racle數(shù)據(jù)庫和SQL Server 2005存儲(chǔ)客戶購買商品的資料。

3.1 本體建立
3.1.1 建立局部本體
在構(gòu)建局部本體前,先用本體理論指導(dǎo)理清字段間的關(guān)系,需明確以下關(guān)系:字段“country”、“city”和“street”是字段“address”的一部分;字段“mmddyy”和“ddmmyy”是字段“date”的不同類型;字段“retail”和“wolesale”是字段“amount”的兩種售出形式。
在明確了上述關(guān)系的基礎(chǔ)上,開始建立局部本體。以表1中數(shù)據(jù)源1(DS1)為例進(jìn)行說明,采用數(shù)據(jù)源的名字作為局部本體owl名,每個(gè)表對(duì)應(yīng)一個(gè)類(概念),實(shí)例數(shù)據(jù)源1的DBMS為Oracle,以下是為DS1建立局部本體的主要OWL語句。
<owl:Class rdf:ID="#s_customer"/>//定義客戶類中的元素
<owl:DatatypeProperty rdf:ID="s_table">
<rdfs:range rdf:resource="http://www.w3.org/2001/
XMLSchema#string"/>
<rdfs:domain rdf:resource="#s_customer"/>
</owl:DatatypeProperty>
<owl:Class rdf:ID="cid">
<rdfs:subClassOf rdf:resource="#s_customer"/>
</owl:Class>
3.1.2 建立全局本體
全局本體可以通過集成各個(gè)數(shù)據(jù)源所包括的領(lǐng)域信息而得到。它就像一個(gè)共享的詞匯庫,建立了數(shù)據(jù)源領(lǐng)域的知識(shí)模型,且為數(shù)據(jù)源提供了公共的語義描述,從而做到將系統(tǒng)的全局視圖進(jìn)行語義化描述,從而解決不同局部本體之間的語義異構(gòu)性。
對(duì)于全局本體元素的定義基本可以借鑒對(duì)DS1元素的定義。建立全局本體還有一個(gè)重要的任務(wù)就是確定術(shù)語,從而對(duì)數(shù)據(jù)源有一個(gè)全局的把握。本例的術(shù)語有:客戶、訂單、地址、名字、數(shù)額、價(jià)格和日期。
3.2 本體映射
本體映射有多種方法,在實(shí)際應(yīng)用中,可以將這些方法結(jié)合起來使用。因此發(fā)現(xiàn)以下關(guān)系:
<owl:Class rdf:ID="city"> //表明city與street是
不相交的關(guān)系。
<rdfs:subClassOf rdf:resource="# s_customer "/>
<owl:disjointWith>
<owl:Class rdf:ID="street">
</owl:disjointWith>
</owl:Class>
以上是運(yùn)用OWL DL描述映射關(guān)系包括層次、等價(jià)、交集、并集、互補(bǔ)和不相交關(guān)系。在此運(yùn)用OWL DL提供的rdfs:用subClassOf聲明一個(gè)類是通過另一個(gè)或多個(gè)類的子類創(chuàng)建層次關(guān)系,用equivalentProperty以描述本體中屬性間的等價(jià)關(guān)系,用disjointWith描述了類之間不相交關(guān)系。
3.3 基于ETL規(guī)則的本體推理
通過單純的本體映射,只是找出了本體之間存在的一般關(guān)系。還需要運(yùn)用基于適當(dāng)規(guī)則的本體推理進(jìn)一步指導(dǎo)ETL過程,即基于ETL規(guī)則的本體推理。
通過本體推理,可以找出每一個(gè)數(shù)據(jù)和數(shù)據(jù)倉庫之間的關(guān)系,例如:等價(jià)關(guān)系、包含關(guān)系、父子關(guān)系、兄弟關(guān)系。對(duì)于本例,通過本體推理可以發(fā)現(xiàn)如下關(guān)系:(1)等價(jià)關(guān)系。id1字段等價(jià)于id2字段,并且有相同的關(guān)系,從而推出字段id1與字段tid等價(jià)。(2)包含關(guān)系。字段cus_address與字段country、 city和street是包含關(guān)系,因字段cus_address與字段address等價(jià),從而可以推導(dǎo)出字段address也包含字段country、city和street 。(3)兄弟關(guān)系。很容易發(fā)現(xiàn)每個(gè)類下面的屬性之間都是兄弟關(guān)系,即互不相交。
在已經(jīng)明確以上關(guān)系的情況下,還需要用ETL規(guī)則指導(dǎo)本體推理。為了完成ETL過程,需要把DS1中的city、street和country字段通過一定的規(guī)則加載成為DW中的address字段。因city、 street和country三個(gè)字段是互不相交的,可知DS1中的city、street和country字段可以構(gòu)成DW中的address字段。在ETL規(guī)則和推理規(guī)則的指導(dǎo)下可知city、street和country三個(gè)字段必須先組合在一起,然后再加載到目標(biāo)數(shù)據(jù)庫中。
同理,可以推導(dǎo)出從name字段中抽取出firstname和lastname兩個(gè)字段。為了完成數(shù)據(jù)源字段name加載到目標(biāo)數(shù)據(jù)庫,根據(jù)ETL規(guī)則需要將字段name拆分成字段firstname和字段lastname,然后再加載到目標(biāo)數(shù)據(jù)庫。
因price字段有兩種貨幣形式,在把該字段從數(shù)據(jù)源加載到目標(biāo)數(shù)據(jù)庫的過程中需要注意將數(shù)據(jù)源的貨幣先轉(zhuǎn)換成對(duì)應(yīng)目標(biāo)數(shù)據(jù)庫的字段或是對(duì)應(yīng)的中間字段,然后再加載到目標(biāo)數(shù)據(jù)庫。在實(shí)際ETL過程中先將該字段過濾,然后對(duì)格式與目標(biāo)數(shù)據(jù)庫不一致的price字段進(jìn)行格式轉(zhuǎn)換。
3.4 本體驅(qū)動(dòng)的ETL過程
經(jīng)過本體映射和推理,得到了一系列的相關(guān)關(guān)系。然后在上述基礎(chǔ)上完成本例的數(shù)據(jù)從數(shù)據(jù)源到目標(biāo)數(shù)據(jù)倉庫的加載過程,具體步驟為:
(1)確定簡單操作及可以直接從源到目標(biāo)的操作。
(2)從源節(jié)點(diǎn)開始引進(jìn)ETL數(shù)據(jù)轉(zhuǎn)換操作,對(duì)相對(duì)復(fù)雜的轉(zhuǎn)化過程引入中間節(jié)點(diǎn);然后從中間節(jié)點(diǎn)出發(fā),繼續(xù)采取額外的轉(zhuǎn)換直至到達(dá)目標(biāo)節(jié)點(diǎn)。
(3)結(jié)合ETL規(guī)則做最后的規(guī)范,如圖2所示。
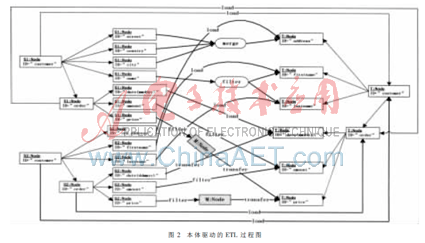
說明:對(duì)于數(shù)據(jù)源中的“customer”、“order”、“firstname”和“lastname”等字段可以直接從源加載到目標(biāo)。字段“street”、“country”和“city”三者合在一起可以構(gòu)成目標(biāo)字段“address”。而“date”字段需通過轉(zhuǎn)換,“name”字段需要拆分,“amount”字段需要過濾。對(duì)于“price”字段,首先過濾,然后轉(zhuǎn)換。最后用ETL規(guī)則規(guī)范整個(gè)過程。
本文提出了一個(gè)本體驅(qū)動(dòng)的ETL過程的架構(gòu)模型;在此基礎(chǔ)上,建立了本體、找出了本體間的映射并在ETL規(guī)則的基礎(chǔ)上進(jìn)行了本體推理;最后通過實(shí)例圖表的方式展現(xiàn)了本體驅(qū)動(dòng)ETL過程。本體的應(yīng)用使ETL過程更加靈活、高效,并且架構(gòu)中的ETL過程可以部分實(shí)現(xiàn)自動(dòng)化,從而解決了數(shù)據(jù)源結(jié)構(gòu)異構(gòu)和語義異構(gòu)的集成問題。
參考文獻(xiàn)
[1] ZHANG Zhuo Lun,WANG Su Fen.A framework model study for ontology-driven ETL processes[C].IEEE International Conference on Wireless Communications, Networking and Mobile computing, 2008.
[2] 鄧志鴻,唐世渭,張銘,等.Ontology研究綜述[J].北京大學(xué)學(xué)報(bào)(自然科學(xué)版),2002,38(5):730-737.
[3] 張忠平,趙瑞珍.基于元數(shù)據(jù)驅(qū)動(dòng)的ETL架構(gòu)設(shè)計(jì)[J].計(jì)算機(jī)應(yīng)用與軟件,2009,26(6):61-63.
[4] NECHES R, FIKES R E, GRUBER T R, et al. Enabling technology for knowledge sharing[J]. Artificial Intelligence,1991,12(3):36-56.
[5] STUDER R, BENJAMINS V R, FENSEL D. Knowledge engineering: principles and methods[J]. Data and Knowledge Engineering, 1998, 25:161-197.
[6] HENDLER J A. Agents and the semantic web[J]. IEEE Intelligent Systems, 2001,16(2):30-37.
[7] W3C Candidate Recommendation.OWL Web Ontology Language Guide[EB/OL].[2003-08-18].http://www.w3.org/TR/2003/CR-owl-guide-20030818/.
[8] ANHAI D, JAYANT M, PEDRO D, et al. Learning to map between ontologies on the semantic web[C].Proceedings of the Eleventh International World Wide Web Conference, 2002.
[9] MELNIK S,GARCIA-MOLINA H,RAHM E. Similarity flooding: a versatile garph matching algorithm[C]. On Data Engineering(ICDE),2002.
[10] CASTANO S, FERRARA A, MONTANELLI S. An algorithm for dynamically matching ontologies in peer based systems Berlin[C]. Proc of the 1st Workshop on Semantic Web and Databases,2003,231-250.
[11] KAON2[EB/OL].[2008-01-14].http://kaon2.semanticweb.org/.
[12] Pellet:OWL 2 Reasoner for Java[EB/OL].[2008-10-27]. http://clarkparsia.com/pellet.