
1 LZW算法及其改進算法
LZW壓縮算法在壓縮的過程中自適應(yīng)建立一個字典,以后的數(shù)據(jù)同字典中的數(shù)據(jù)相匹配,匹配上則輸出字典的索引。由于表示字典的索引所用的比特數(shù)遠小于字符的比特數(shù),從而達到壓縮的效果。這個生成的字典不需要隨著壓縮的數(shù)據(jù)一同傳輸,而是能夠根據(jù)壓縮的數(shù)據(jù)在解壓時重新動態(tài)生成一模一樣的字典。
LZW編碼原理如圖1所示,在進行壓縮時首先把字典中的前256(0~255)項初始為全部的256個8位字符,分別為十進制數(shù)0~255。當(dāng)輸入第一個字符時,總是在字典中可以找到,直到新的字符X不在字典詞條中時,便將字符串IX加入到字典的第256項,以此類推。以字符串流5,6,7,8,9,5,5,6,6,7,8,9,5,…為例,表1給出了字典存儲的物理結(jié)構(gòu)和壓縮過程中字典項的讀寫示意。壓縮后編碼輸出為5,6,7,8,9,5,256,257,259,…。

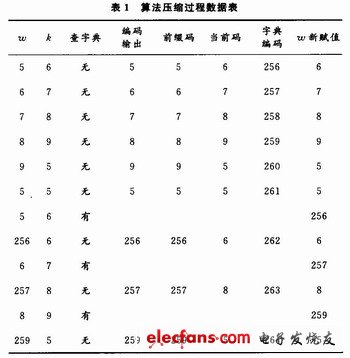
傳統(tǒng)的LZW壓縮算法采用8位數(shù)據(jù)輸入,固定長度編碼輸出,隨著字典內(nèi)容的不斷增多,輸出編碼的位數(shù)不斷增加勢必造成資源的浪費,也會損失壓縮率。另外,由于字典的容量有限,隨著壓縮過程的進行,字典會被填滿,若是簡單的不再向字典中增加內(nèi)容,那么后面的壓縮率就會降低,而如果將字典全部清除重新建立字典,在字典建立初期壓縮率也是很低的。針對以上不足,文獻對LZW算法做以下改進:采用12位數(shù)據(jù)作為壓縮輸入,變長度的碼字輸出。
壓縮字典最多可容納16 384個碼,共分為三部分,其中0~4 095為12位輸出,4 096~8 191為13位,8 192~16 383為14位。每當(dāng)輸出長度變化時,同時輸出一個變長標(biāo)識,便于解碼器解碼。
2 LZW算法FPGA實現(xiàn)
2.1 算法實現(xiàn)硬件結(jié)構(gòu)
LZW數(shù)據(jù)壓縮算法的FPGA硬件實現(xiàn),其內(nèi)部功能模塊劃分如圖2所示。
2.3 仿真結(jié)果
清空字典存儲器模塊,初始化信號,將可能出現(xiàn)的單字符存入字典,壓縮時新傳續(xù)存地址為4096,新字符串輸入時產(chǎn)生相應(yīng)的哈希表地址與偏移量;然后讀字典存儲器相應(yīng)地址的內(nèi)容,如內(nèi)容為空則輸出輸入的數(shù)據(jù),并把相應(yīng)內(nèi)容存入字典,如內(nèi)容匹配,則繼續(xù)輸入下一數(shù)據(jù),否則(即發(fā)生沖突)產(chǎn)生新的哈希表地址,重新讀取字典,進行判斷、比較。仿真時序如圖3所示.
仿真結(jié)果:輸入數(shù)據(jù)為5,6,7,8,9,5,6,7,8,9,5,6,7,…;輸出數(shù)據(jù)為5,6,7,8,9,4 098,4 100,4 102,…。仿真結(jié)果與理論計算值一致。
3 結(jié) 論
LZW算法邏輯簡單,實現(xiàn)速度快,擅長于壓縮重復(fù)出現(xiàn)的字符串;無需事先統(tǒng)計各字符的出現(xiàn)概率,一次掃描即可;相對于其他算法,更有利于硬件實現(xiàn)。本文利用FPGA實現(xiàn)了改進的LZW壓縮算法,仿真證明其算法具有很高壓縮率,適合工程的實際應(yīng)用。