
摘 要: 本體映射的關(guān)鍵技術(shù)是本體相似度計算。本文基于已有的V-Doc(虛擬文檔)技術(shù)提出一種新的NV-Doc本體相似度計算方法,其中不僅用到了本體中實(shí)體自身以及其第一層相鄰節(jié)點(diǎn)的信息,而且還充分利用了第二層相鄰節(jié)點(diǎn)的信息。
關(guān)鍵詞: 語義網(wǎng);本體映射;虛擬文檔;本體相似度
本體是共享概念化的明確具體規(guī)范,隨著語義網(wǎng)的發(fā)展,本體的應(yīng)用越來越多。用RDF[1]或OWL[2]書寫的Web本體在語義網(wǎng)的出現(xiàn)和應(yīng)用方面起到了很大作用,本體的數(shù)量也與日俱增。
Web的分布式特點(diǎn)使得大量的本體由不同組織開發(fā),并且在很大程度上覆蓋相同或者相交的領(lǐng)域,因此Web本體之間存在一定的相似性,但相關(guān)領(lǐng)域的不同本體之間也存在很大的異構(gòu)性。
解決本體異構(gòu)問題的最好方法是本體映射。本體映射的目的是架起異構(gòu)本體之間的橋梁,在使用不同本體的Web應(yīng)用之間建立互操作,從而實(shí)現(xiàn)語義網(wǎng)環(huán)境下數(shù)據(jù)的集成與管理。而本體映射的關(guān)鍵技術(shù)是本體的相似度計算,即計算兩個不同本體中實(shí)體之間的相似度,當(dāng)相似度值大于某個給定的閾值時,可以認(rèn)為這兩個實(shí)體之間存在著一定的語義關(guān)系。
目前,關(guān)于本體相似度計算方法的自動化程度不高,而且不能充分利用本體的各種描述信息。已有的V-Doc技術(shù)能夠較好地解決這兩方面的問題,但也存在一些不足。
基于虛擬文檔的本體相似度計算方法V-Doc[3]將本體看成一個有向圖,圖中的每個節(jié)點(diǎn)對應(yīng)本體中的一個實(shí)體,為每個實(shí)體自動建立虛擬文檔,充分利用了節(jié)點(diǎn)自身和鄰接節(jié)點(diǎn)的描述信息。但該方法也存在不足:節(jié)點(diǎn)的特征不僅與鄰接節(jié)點(diǎn)有關(guān),而且還與鄰接節(jié)點(diǎn)的鄰接節(jié)點(diǎn)信息有關(guān),即實(shí)體的描述信息還應(yīng)該考慮節(jié)點(diǎn)的第二層鄰接節(jié)點(diǎn)的信息。針對其不足,本文提出一種新的基于虛擬文檔的本體相似度計算方法NV-Doc。
1 V-Doc簡介
1.1 虛擬文檔的構(gòu)建
虛擬文檔是為了描述概念特點(diǎn)而建立起來的文檔,為每一個節(jié)點(diǎn)構(gòu)建虛擬文檔,充分利用節(jié)點(diǎn)自身和鄰接節(jié)點(diǎn)的描述信息。
定義1 (URIrefs描述):假設(shè)e是一個URIref,對e的描述通過與其有關(guān)的名字、標(biāo)簽、注釋和其他自然語言描述信息組成,其定義[3]為:

1.2 相似度計算
本體中每一個實(shí)體(節(jié)點(diǎn))的描述信息(語言學(xué)特征)通過該節(jié)點(diǎn)的虛擬文檔表示。因此,兩個本體中實(shí)體的相似度可通過計算與之對應(yīng)的兩虛擬文檔之間的相似度而得到,即虛擬文檔之間的相似度就是實(shí)體之間的相似度。虛擬文檔之間的相似度通過在信息檢索領(lǐng)域應(yīng)用廣泛的向量空間模型VSM(Vector Space Model)[4]方法計算。將兩個待匹配的虛擬文檔用向量空間中的一個向量表示,當(dāng)然在相似度計算之前還要對文檔進(jìn)行預(yù)處理,如分詞、去除停用詞、提取詞干等。向量空間模型中,關(guān)鍵詞的權(quán)重使用TF/IDF技術(shù)[5]表示。由此可以得到一個N×W的矩陣X,其中N是虛擬文檔的個數(shù),W表示所有虛擬文檔中token的總數(shù)。可以通過矩陣與其倒置矩陣的積得到虛擬文檔之間的相似矩陣,最后規(guī)范化相似矩陣,使相似度值在[0,1]區(qū)間內(nèi)。規(guī)范化后所得矩陣即為虛擬文檔之間的相似度矩陣,每個值也代表了兩個虛擬文檔之間的相似度,從而得到與之對應(yīng)的兩實(shí)體之間的相似度。
2 NV-Doc
2.1 改進(jìn)的虛擬文檔
為RDF圖中每一個節(jié)點(diǎn)構(gòu)建虛擬文檔,不僅用到節(jié)點(diǎn)自身以及相鄰第一層的鄰居節(jié)點(diǎn)信息,還用到節(jié)點(diǎn)第二層的鄰接節(jié)點(diǎn)信息。
定義3 (改進(jìn)的虛擬文檔):假設(shè)e是一個URIref,e的虛擬文檔NVD(e)的表示方程為:

2.2 簡單示例
假設(shè)一個簡單的本體片段模型如圖1所示。
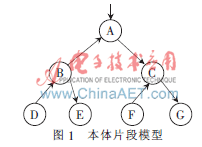
按照式(3)得到節(jié)點(diǎn)A的虛擬文檔為:

3 實(shí)驗(yàn)結(jié)果及分析
3.1 實(shí)驗(yàn)數(shù)據(jù)
實(shí)驗(yàn)數(shù)據(jù)選用基于KAON2的開源資源Framework for Ontology Alignment and Mapping中所提供的Test Ontologies and Alignments。從中選用本體規(guī)模較小的russia1.owl和russia2.owl作為數(shù)據(jù)源,其中russia1中共有49個節(jié)點(diǎn),russia2中共有51個節(jié)點(diǎn)。進(jìn)一步的實(shí)驗(yàn)選用數(shù)據(jù)集OAEI 2005 benchmark tests中的五組規(guī)模稍大的本體作為數(shù)據(jù)源。 本文兩次實(shí)驗(yàn)中各參數(shù)的取值不變:α1、α2、α3、α4的值分別為1.0、0.5、0.25、0.25,參數(shù)γ1、γ2、γ3、γ4的值分別取0.1、0.1、0.05、0.05。各參數(shù)的取值借鑒Falcon-OA[6]系統(tǒng)在程序中所給的參數(shù)值。對于實(shí)體的描述,第一層鄰接節(jié)點(diǎn)一般比第二層鄰接節(jié)點(diǎn)更有影響力,所以γ3、γ4分別取0.05、0.05,比γ1、γ2的值0.1、0.1都小是有道理的。
本文采用查準(zhǔn)率和查全率的綜合評估函數(shù)以及運(yùn)行時間作為評價標(biāo)準(zhǔn)對實(shí)驗(yàn)結(jié)果進(jìn)行評估。

3.2 實(shí)驗(yàn)結(jié)果及分析
本文主要的改進(jìn)之處是提出新的算法來構(gòu)建本體中實(shí)體的虛擬文檔,虛擬文檔間的相似度計算也是通過描述的方法實(shí)現(xiàn),初步實(shí)驗(yàn)結(jié)果如表1所示。

初步實(shí)驗(yàn)結(jié)果:表明改進(jìn)的算法雖然在運(yùn)行時間上有所延長,但查準(zhǔn)率和查全率都有所提高,而且這種時間消耗不是很大。
其次,為了再一次驗(yàn)證NV-Doc較V-Doc的可行性,對數(shù)據(jù)集OAEI 2005 benchmark tests中的五組本體進(jìn)行實(shí)驗(yàn),最后得到的實(shí)驗(yàn)結(jié)果如圖2、圖3所示。
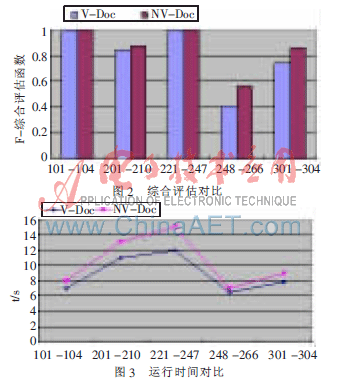
再次實(shí)驗(yàn)結(jié)果表明,NV-Doc能夠取得比V-Doc更好的查全率和查準(zhǔn)率,雖然在效率方面不及V-Doc,但從整體上來看,效率上的部分損失換來更好的查準(zhǔn)率和查全率也是值得的。
本文針對計算本體中實(shí)體相似度存在的問題提出改進(jìn)方法,充分利用實(shí)體自身和實(shí)體的第一層及第二層鄰接節(jié)點(diǎn)的描述信息(即實(shí)體的語言學(xué)上的特征)。實(shí)驗(yàn)結(jié)果分析表明,改進(jìn)后的算法在查準(zhǔn)率和查全率方面優(yōu)于原先的算法。下一步的研究工作是:一方面將此方法和其他計算本體相似度的方法有效結(jié)合,從而更有效地實(shí)現(xiàn)本體映射;另一方面是減少運(yùn)行時間,提高效率。最后還要充分利用本體其他的描述信息,如本體的屬性、關(guān)系、實(shí)例等。
參考文獻(xiàn)
[1] KLYNE G, CARROLL J J. Resource description framework (RDF): concepts and abstract syntax.//W3C Recommendation 10 February 2004. Latest version is available at http://www.w3. org/TR/rdf-concepts/.
[2] Patel-Schneider P F, HAYES P, HORROCKS I. OWL web ontology language semantics and abstract syntax. W3C Recommendation 10 February 2004. Latest version is available at http: //www. w3. org/ TR/owl-semantics/.
[3] QU Yuzhong, HU Wei, CHENG Gong. Constructing virtual documents for ontology matching[C]//Proceedings of the 15th International Conference on W orld W ide W eb.Edinburgh,Scotland: [S.n.],2006.
[4] VIJAY V, RAGHAVAN S K, WONG M. A critical analysis of vector space model for information retrieval. JASIS, 1986: 37(5), 279-287.
[5] SALTON G, MCGILL M. Introduction to modern information retrieval[M]. McGraw-Hill Book Company,1984.
[6] Hu Wei, Qu Yuzhong. Falcon-AO: a practical ontology matching system[C]. Web Semantics: Science, Services and Agents on theWorldWideWeb, 2008: 237-239.