
摘 要: 為了能夠充分地挖掘、分享和重復利用本體中的知識,提出一種基于映射關系的分簇方法,先通過已存在的高質量的本體映射關系,對原本體和目標本體分別進行分簇,再挖掘出實體間潛在的關系。通過實驗證明,采用改進的映射方法提高了本體映射的質量,采用具有完善實體關系的映射結果提高了檢索系統(tǒng)的準確率和查全率。
關鍵詞: 分簇;本體映射;實體關系發(fā)現(xiàn)
隨著越來越多的本體被開發(fā),以及持續(xù)性和高效性的知識訪問需求不斷提高,本體知識的充分挖掘、分享和重復利用已成為本體庫優(yōu)化的重要研究內容。由于本體的獨立開發(fā)性,導致在相同或者重疊領域本體中實體的定義和實體間的關系有所不同,即本體間的互操作性較低。本體映射已成為當今本體研究中的熱點,它是解決并促進本體間互操作性問題的重要方法。但是要更充分地挖掘、分享和重復利用本體知識,該方法還需要不斷地改進和優(yōu)化。本體映射過程中存在以下兩個問題:
(1)基于特征低相似性進行本體映射的質量不高。目前對語義、詞匯和結構特性相似度較高的本體進行映射,在一定范圍內其映射質量是較高的,但是大部分本體的建模粒度都不相同,導致本體中實體表示的詞匯和結構特性都不相同,即本體中實體的特征相似度較低,所以采用基于詞匯和結構特征的相似性進行本體映射的質量不高。
(2)映射結果中實體關系不夠完善。目前大量本體映射方法在建立了本體映射關系后不會對實體關系進行分析和處理,導致本體映射結果的實體關系不夠完善,應用質量較低。
1 相關工作
目前大多數(shù)的本體映射方法(例如ASMOV[1-2]和RiMOM[3]等)是基于詞匯和結構特征的相似性進行本體映射的,在一定范圍內映射質量較高,但當兩個本體的建模粒度不相同時,采用基于這些特征相似性進行本體映射的質量就較低。例如,石灰在原本體中包括氧化鈣和氫氧化鈣,在目標本體中包括煅燒石灰、熟石灰、石灰乳和消石灰,這兩個本體中用不同的術語描述相同的信息石灰,采用傳統(tǒng)的本體映射方法測量得到的映射準確度低于1%,本體映射時就無法建立實體間高質量的映射關系。為解決這一問題,可以重復利用已存在的高質量本體映射關系,提高本體映射的質量。調查本體映射關系重復利用的目的在于利用多對一或者一對多的實體映射關系實現(xiàn)分簇的過程,從而獲取準確的匹配信息。
本文以最新的ASMOV映射系統(tǒng)[4]為基礎。它是一種半自動化本體映射過程,聯(lián)合了元素級和結構級的相似度測量,使用本體中四種不同特征相似度的加權平均值作為實體間的總相似度,采用了語義驗證要求遵守的規(guī)則來判斷是否建立映射鏈接的技術,以確保建立的映射鏈接不包含語義矛盾,但是其映射匹配的準確率和查全率還有待提高。針對本體映射過程中存在的問題以及ASMOV在映射匹配質量方面的不足,提出了一種基于分簇的本體映射方法OMMC(Ontology Mapping Method based on Clumping),該方法有助于建立本體間高質量的映射關系,通過高質量的映射關系再進行實體間關系的再發(fā)現(xiàn),從而提高了本體映射的應用質量。
2 基于分簇的本體映射
基于分簇的本體映射的流程是:先將原本體和目標本體分別進行分簇,再將分簇后的原本體和目標本體應用于ASMOV映射系統(tǒng)中的本體映射,主要包括分簇和建立映射鏈接兩個模塊。
2.1 分簇
定義1 簇。利用已存在的高質量的本體映射關系,在多對一的映射場景下,一個本體O中的多個實體和另一個本體中的相同實體匹配,則將這多個實體看做是一個簇,本體O可劃分為多個簇。

對原本體和目標本體分別進行分簇,原本體和目標本體都被劃分為多個簇,得到一個原本體的劃分和一個目標本體的劃分。以農業(yè)領域的本體S和本體T為例,原本體S是PWP(Prism Web Pages)定義的一個中文本體,包含1 028個實體,S和本體PWP1已存在本體映射關系,通過它們之間的映射關系進行分簇,可將S劃分為196個簇,S中一個簇的映射關系如表1所示;目標本體T是FAO(Food and Agriculture Organization)定義的一個中文本體,包含2 420個實體,T和本體FAO1已存在本體映射關系,通過它們之間的映射關系進行分簇,將T劃分為357個簇,T中一個簇的映射關系如表2所示。
2.2 建立映射鏈接
對原本體S和目標本體T分別進行分簇,得到了兩個穩(wěn)定性劃分PS和PT后,直接進入本體映射匹配階段,在ASMOV系統(tǒng)中,對本體S和目標本體T采用OMMC方法進行映射的過程如圖1所示。
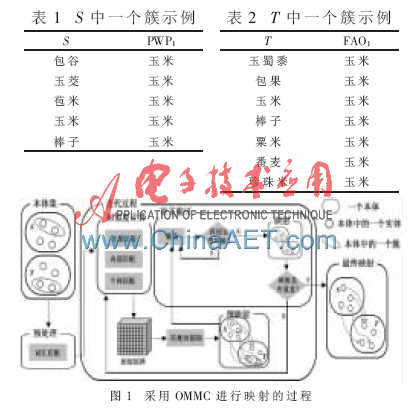
本體映射的核心模塊是相似度計算,改進的ASMOV映射過程在相似度計算時要優(yōu)先考慮在一個簇中的實

運行改進后的ASMOV系統(tǒng)步驟如下:
(1)數(shù)據(jù)準備。準備好已經分簇的原本體和目標本體。
(2)預處理階段進行詞匯匹配。利用一個詞庫來計算概念、屬性和個體的詞匯相似度。
(3)進行相似度計算。包括外部關系、內部匹配和個體匹配相似度的計算,并將計算結果放入相似度矩陣中。
(4)從相似矩陣中提取兩個本體中相似度最高的匹配對實體集,依據(jù)這些實體集找到對應的簇,建立簇中實體間多對多的映射關系,并放入預映射模塊中。
(5)對預映射模塊中的映射關系集進行語義驗證,即通過一些已定義的規(guī)則進行驗證并修剪無效的映射關系,且將連接無效映射關系的實體間相似度置零。循環(huán)執(zhí)行步驟(3)~步驟(5),直到本體S或T中所有簇都執(zhí)行一遍迭代過程。
(6)提取最終的本體映射關系。
3 實體關系的再發(fā)現(xiàn)
在建立了高質量的本體映射關系后,連接每一條映射關系的兩個實體間都可發(fā)現(xiàn)新的關系,主要包括父類關系發(fā)現(xiàn)、子類關系發(fā)現(xiàn)和等價類關系發(fā)現(xiàn)。
規(guī)則1 父類關系發(fā)現(xiàn)是指若連接一條映射關系的兩個實體的父類不同,那么這兩個實體的父類可以合并,同時對合并后的父類消除重復,最后這兩個實體得到了相同的新的父類集合,依此類推應用于每一條映射關系中。如圖2所示,建立實體C4和實體E2的映射關系以后,C4和E2的父類都為C1和E1,若C1與E1重復,那么去除重復后C4和E2的父類都為C1或者E1。

規(guī)則2 子類關系發(fā)現(xiàn)是指若連接一條映射關系的兩個實體的子類不同,那么這兩個實體的子類可以合并,同時對合并后的子類消除重復,最后這兩個實體得到了相同的新的子類集合,依此類推應用于每一條映射關系中。如圖3所示,建立C4和E2的映射關系以后,C4和E2的子類都為C5、C6、C7和E4,若E4與C5、C6和C7其中一個重復,那么去除重復后C4和E2的子類都為C5、C6和C7。

在合并父類、子類及等價類關系時,以T為目標,且需互相說明彼此之間的關系,如果發(fā)生沖突,則調用以下沖突處理規(guī)則進行解決。
規(guī)則 4 類層次結構沖突處理[6]。以目標本體中類層次結構為基準,刪除原本體的沖突結構,保證關系合并中類層次結構的完整性。例如在本體S中的C2和C3是等價類,在本體T中的E1是E2的父類,若C2和E1建立了映射關系,C3和E2建立了映射關系,則先合并E2,然后合并E1,本體中C2和C3既是父子關系又是等價關系,此時就存在類層次沖突問題,以本體T層次結構為基準,把C2和C3的等價類關系刪除。
4 實驗評估
4.1 改進ASMOV前后映射質量比較實驗
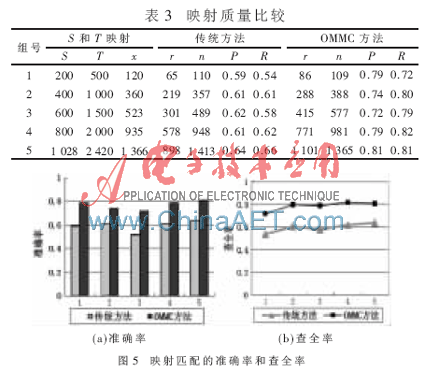
在ASMOV的測試場景中,逐步對本體S和本體T進行映射檢測,獲取的參數(shù)包括標準配對數(shù)x、配對總數(shù)量n和配對總數(shù)n中準確的配對數(shù)r,通過獲取的參數(shù)值來計算匹配的準確率P和查全率R,其計算公式為P=r/n和R=r/x。經過多次測試改進前后的方法,證明采用OMMC方法得到的映射匹配質量均明顯提高,相對于傳統(tǒng)方法,在相同條件下采用OMMC方法使得匹配的準確率和查全率均提高了約0.2。比較結果如表3和圖5所示。
4.2 關系再發(fā)現(xiàn)前后映射結果應用的質量比較實驗
本文提出的分簇方法是在已存在的高質量的本體映射關系中發(fā)現(xiàn)本體內部結構,即將本體劃分為若干個簇。在映射匹配時采用以簇為單位替換以實體為單位的ASMOV方法,建立高質量的本體映射關系,然后對實體關系進行再發(fā)現(xiàn),完善了映射結果的實體關系。將實體關系完善前后的映射結果應用于海量農業(yè)信息語義檢索系統(tǒng)中,用多組請求信息分別進行檢索,比較檢索結果的準確率和查全率。
海量農業(yè)信息語義檢索系統(tǒng)總體框架主要包括本體管理、數(shù)據(jù)獲取、請求管理、請求信息匹配、海量農業(yè)信息處理及語義請求客戶端6個部分。通過網(wǎng)絡爬蟲工具采集海量農業(yè)信息,并對爬下的網(wǎng)頁進行信息的抽取和整理,抽取和整理后的網(wǎng)頁可保存在海量農業(yè)信息數(shù)據(jù)庫中作為檢索時的資源庫。為使實驗能夠更準確和更快速得出結論,選擇了整理好的10萬個網(wǎng)頁作為資源庫,運用該系統(tǒng)進行實驗的具體步驟如下:
(1)清除本體庫中已經存在的本體信息,將本體及映射結果添加到本體庫中。
(2)將本體庫中的本體信息與海量農業(yè)信息相關聯(lián),即運行信息標注與詞頻計算、倒排表建立和農業(yè)信息聚類3個模塊,并將關聯(lián)信息存入海量農業(yè)信息數(shù)據(jù)庫中。
(3)通過配置文件管理接口設置配置文件信息,如本體庫中等價類、父類和子類各自所占的權重等。
(4)啟動系統(tǒng)服務器,在用戶檢索接口輸入用戶需要檢索的信息。
(5)計算檢索結果的準確率和查全率。
在建立高質量的本體映射鏈接后得到映射結果M1,在完善映射結果M1中的實體關系后得到映射結果M2,將M1和M2分別應用于海量農業(yè)信息語義檢索系統(tǒng)中,運行該系統(tǒng)進行實驗,輸入多組檢索數(shù)據(jù),計算檢索結果的準確率和查全率,如圖6所示。通過比較分析可知,對采用了M2的系統(tǒng)進行檢索,得到了較高的準確率和查全率,從而表明了完善映射結果中的實體關系對本體映射應用的重要性。

本文提出一種基于映射關系的分簇方法,首先通過各自已有的映射關系,對原本體和目標本體分別進行分簇,再采用改進的ASMOV映射系統(tǒng),建立高質量的映射關系,并完善實體間的關系。通過對比采用OMMC方法和傳統(tǒng)方法的ASMOV系統(tǒng)的映射質量,可知采用OMMC方法具有一定的優(yōu)越性,即匹配結果更準確和全面;通過對比完善實體關系前后本體映射結果應用的質量,可知完善了實體關系的映射結果應用于檢索系統(tǒng)中,提高了檢索系統(tǒng)的準確率和查全率。
參考文獻
[1] Jérme Euzenat,MEILICKE C,STUCKENSCHMIDT H,et al.Ontology alignment evaluation initiative:six years of experience[C].Proceedings of the Journal on Data Semantics XV.Berlin Heidelberg:Springer,2011:158-192.
[2] JEAN-MARY Y R,SHIRONOSHITA E P,KABUKA M R. Ontology matching with semantic verification[J].Web Semantics,2009,7(3):235-251.
[3] Wang Zhichun,Zhang Xiao,Hou Lei,et al.RiMOM results for OAEI 2010[C].Proceedings of the 5th International Workshop on Ontology Matching(OM-2010) collocated with the 9th International Semantic Web Conference(ISWC-2010).Shanghai:CEUR-WS,2010:195-202.
[4] ASMOV Results for OAEI 2007[EB/OL].[2012-06-30].http://ftp.informatik.rwth-aachen.de/Publications/CEUR-WS/Vol-304/paper12.pdf,2007.
[5] 張釙.基于語義的網(wǎng)絡服務匹配機制的研究與實現(xiàn)[D]. 北京:清華大學,2005.
[6] 羅正海.面向語義Web服務的本體合并研究[D].大連:大連海事大學,2009.