
摘 要: 運(yùn)用自組織特征映射神經(jīng)網(wǎng)絡(luò)的工作原理和具體實(shí)現(xiàn)算法進(jìn)行故障診斷分析,在對(duì)已有神經(jīng)網(wǎng)絡(luò)聚類分析方法概括和總結(jié)的基礎(chǔ)上,結(jié)合實(shí)驗(yàn)數(shù)據(jù)、仿真數(shù)據(jù)對(duì)自組織特征映射算法故障模型診斷進(jìn)行研究,得出了有意義的結(jié)論。
關(guān)鍵詞: 數(shù)據(jù)挖掘;神經(jīng)網(wǎng)絡(luò)聚類;自組織特征映射;特征提取
實(shí)時(shí)監(jiān)測(cè)設(shè)備運(yùn)行狀況,在運(yùn)行參數(shù)發(fā)生變化時(shí)及時(shí)報(bào)警并提示操作人員進(jìn)行檢查,對(duì)于保障設(shè)備的正常運(yùn)行具有重要的意義。傳統(tǒng)的故障診斷方法一般都是采用基于知識(shí)的故障診斷系統(tǒng),以領(lǐng)域?qū)<液筒僮魅藛T的啟發(fā)性主觀經(jīng)驗(yàn)知識(shí)為基礎(chǔ),經(jīng)過(guò)產(chǎn)生式推理和演繹推理來(lái)獲得大量的規(guī)則,從而獲得診斷故障原因和部位。但由于基于知識(shí)的故障診斷系統(tǒng)不具有學(xué)習(xí)功能,知識(shí)的獲取途徑只有通過(guò)專家或操作人員總結(jié)經(jīng)驗(yàn)獲取,從而制約了其進(jìn)一步的發(fā)展[1,2]。
神經(jīng)網(wǎng)絡(luò)是模擬人腦結(jié)構(gòu)開(kāi)發(fā)的一種并行運(yùn)算的數(shù)字算法,由輸入層、輸出層和隱層組成,可以用來(lái)建立輸入輸出之間復(fù)雜的映射關(guān)系。由于具有良好的記憶聯(lián)想功能,因此在故障診斷領(lǐng)域得到了廣泛的應(yīng)用。但是傳統(tǒng)BP神經(jīng)網(wǎng)絡(luò)只能用于確定性關(guān)系的學(xué)習(xí),不能處理矛盾樣本,而故障診斷系統(tǒng)中的數(shù)據(jù)有些具有一定的離散性,因此需要將輸入層的確定性信息模糊化之后變成模糊量,將傳統(tǒng)神經(jīng)網(wǎng)絡(luò)變?yōu)槟:窠?jīng)網(wǎng)絡(luò),將與故障運(yùn)行參數(shù)相對(duì)應(yīng)的隸屬度數(shù)值作為輸入,從而使神經(jīng)網(wǎng)絡(luò)系統(tǒng)更加適合設(shè)備故障狀態(tài)的描述。
1 自組織映射算法
1.1 拓?fù)錂C(jī)構(gòu)與權(quán)值調(diào)整
1981年KOHONEN T教授提出一種自組織特征映射SOFM(Self-Organizing Feature Map),又稱為SOM網(wǎng)或Kohonen網(wǎng)。他認(rèn)為當(dāng)一個(gè)神經(jīng)網(wǎng)絡(luò)接受外界輸入模式時(shí)將會(huì)分為不同的對(duì)應(yīng)區(qū)域,各區(qū)域?qū)斎肽J骄哂胁煌捻憫?yīng)特征。SOFM網(wǎng)共兩層,輸入層模擬感知外界輸入信息的視網(wǎng)膜 ,輸出層模擬做出響應(yīng)的大腦皮層。輸入層各神經(jīng)元通過(guò)權(quán)向量將外界信息匯集到輸出層的各神經(jīng)元。輸出層屬于競(jìng)爭(zhēng)層,神經(jīng)元的排列有多種形式,如一維線陣、二維平面陣和三維刪格陣。輸出按照二維平面組織是SOFM網(wǎng)最典型的組織方式,結(jié)構(gòu)如圖1所示。SOFM網(wǎng)采用的學(xué)習(xí)算法是在“勝者為王”算法基礎(chǔ)上改進(jìn)的,主要區(qū)別在于調(diào)整權(quán)向量與側(cè)抑制的方式不同。SOFM學(xué)習(xí)算法中不僅獲勝神經(jīng)元本身要調(diào)整權(quán)向量,其周圍的神經(jīng)元在其影響下也要不同程度地調(diào)整權(quán)向量。權(quán)向量的調(diào)整函數(shù)稱為墨西哥帽函數(shù)。由于該函數(shù)的復(fù)雜性,在實(shí)際中采用較為簡(jiǎn)化的大禮帽函數(shù)或廚師帽函數(shù)來(lái)處理。
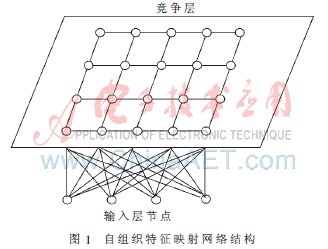

(6)結(jié)束檢查。訓(xùn)練結(jié)束是以學(xué)習(xí)率?濁(t)是否衰減到0或某個(gè)預(yù)定的正小數(shù)為條件,不滿足條件則回到步驟(2)[3,4]。
2 自組織映射算法在故障診斷中的處理
2.1 理論依據(jù)
任何聚類算法的參數(shù)對(duì)聚類結(jié)果都具有直接的影響,當(dāng)考慮高維數(shù)據(jù)的時(shí)候,合理的降維是一個(gè)很重要的方面,降維應(yīng)該遵循一定的方法。在算法中處理高維數(shù)據(jù)時(shí)將更高維密集單元的搜索限制在子空間密集單元的交集中,這種候選空間的確定采用基于關(guān)聯(lián)規(guī)則挖掘中的先驗(yàn)性質(zhì),該性質(zhì)在所有空間中利用數(shù)據(jù)項(xiàng)的先驗(yàn)知識(shí)以裁減空間。采用的性質(zhì)是:如果數(shù)據(jù)在k維單元是密集的,則它在k-1維空間上的投影也是密集的。也就是說(shuō),給定一個(gè)k維的候選密集單元,檢查它的k-1維投影單元,如果發(fā)現(xiàn)任何一個(gè)不是密集的,則知道第k維的單元也不是密集的[5]。由此進(jìn)一步得出結(jié)論,如果聚類的某一維是密集的,則它對(duì)于整個(gè)k維聚類也是可用的,否則,在整個(gè)k維數(shù)據(jù)聚類中不起作用。把這一關(guān)聯(lián)規(guī)則挖掘中的性質(zhì)應(yīng)用到故障特征屬性的降維中。
SOFM的數(shù)據(jù)壓縮和特征抽取的功能,將高維空間的樣本在保持拓?fù)浣Y(jié)構(gòu)不變的條件下投影到低維空間,在高維空間中很多模式的分布具有復(fù)雜特性,但當(dāng)映射到低維空間后,由于維度和節(jié)點(diǎn)數(shù)量(從多維對(duì)象映像到二維的神經(jīng)網(wǎng)絡(luò)節(jié)點(diǎn))的降低,其規(guī)律很明顯。
2.2 算法
2.2.1 預(yù)處理:選擇合適的維參與映射
自組織特征映射網(wǎng)絡(luò)聚類是模型聚類的一種,其自組織學(xué)習(xí)過(guò)程也可以描述為:對(duì)于每一個(gè)網(wǎng)絡(luò)的輸入,只調(diào)整一部分權(quán)值,使權(quán)向量更接近或更偏離輸入矢量,這一調(diào)整過(guò)程,就是競(jìng)爭(zhēng)學(xué)習(xí)。隨著不斷學(xué)習(xí),所有權(quán)向量都在輸入矢量空間相互分離,形成了各自代表輸入空間的一類模式,這就是自組織映射網(wǎng)絡(luò)的特征自動(dòng)識(shí)別的聚類功能。每個(gè)故障模式參數(shù)樣本作為聚類的一個(gè)“典型”,可以根據(jù)新對(duì)象與哪個(gè)參數(shù)樣本最相似(基于某種距離計(jì)算方法)而將其分派到相應(yīng)的聚類中。被診斷設(shè)備狀態(tài)可以由一系列的特征參數(shù)來(lái)描述,一旦設(shè)備出現(xiàn)某個(gè)故障或多個(gè)故障,其狀態(tài)特征參數(shù)也會(huì)發(fā)生相應(yīng)的變化。因而,特定的特征參數(shù)值反映了相應(yīng)的設(shè)備故障。在故障診斷領(lǐng)域,當(dāng)設(shè)備處于故障狀態(tài)時(shí),將特征參數(shù)呈現(xiàn)出的特定取值稱之為故障征兆,即不同的故障征兆對(duì)應(yīng)著不同的故障類型;通常,設(shè)備的故障類型不止一種,因此用故障域來(lái)表述設(shè)備可能出現(xiàn)的多種故障類型,用征兆域來(lái)表述可能出現(xiàn)的多種故障征兆。由此可見(jiàn),可以認(rèn)為故障診斷即進(jìn)行由征兆域到故障域的模式識(shí)別,或是由征兆域到故障模式的具有聯(lián)想能力的判別分類[6-8]。
需要指出的是,文本型數(shù)據(jù)轉(zhuǎn)換以后應(yīng)該作為分類數(shù)據(jù)來(lái)處理。一般,在聚類過(guò)程中,如果分類維和密集維表示的是非空間屬性中不同特征的某個(gè)方面,包括太密集的數(shù)據(jù)或者太分散的數(shù)據(jù),都不適合進(jìn)入聚類,如果不是作為分類數(shù)據(jù),則太集中的數(shù)據(jù)不會(huì)對(duì)聚類產(chǎn)生影響,只會(huì)增加處理的時(shí)間。而太分散的數(shù)據(jù)會(huì)對(duì)聚類結(jié)果產(chǎn)生不良的影響。但是對(duì)于表示同一特征的不同維來(lái)說(shuō),有些維是密集的,有些維不是密集的,因此需要在這些維中選擇合適的維進(jìn)行聚類。
2.2.2 診斷實(shí)例
在故障診斷分析應(yīng)用中,用戶應(yīng)該根據(jù)聚類的目的先選擇一些候選維,準(zhǔn)備參與聚類。取X1~X10 作為征兆參數(shù),在系統(tǒng)中各自參數(shù)點(diǎn)具有不同特點(diǎn),在發(fā)生可能的故障時(shí),它們的變化范圍和方向各不相同,對(duì)征兆參數(shù)進(jìn)行歸一化處理,如表1所示。

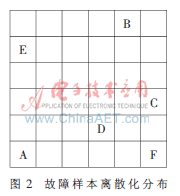
應(yīng)用自組織特征映射網(wǎng)絡(luò)來(lái)模擬模糊聚類故障診斷的全過(guò)程,應(yīng)用Matlab工具箱進(jìn)行編程,根據(jù)故障樣本,利用newsom創(chuàng)建網(wǎng)絡(luò)的競(jìng)爭(zhēng)層為6×6的結(jié)構(gòu),網(wǎng)絡(luò)結(jié)構(gòu)是可以調(diào)整的,可以根據(jù)數(shù)據(jù)規(guī)模進(jìn)行調(diào)整,然后輸入樣本p(如表1參數(shù)值進(jìn)行訓(xùn)練),利用函數(shù)train和函數(shù)sim對(duì)網(wǎng)絡(luò)進(jìn)行訓(xùn)練,并對(duì)故障樣本進(jìn)行模糊聚類。由于訓(xùn)練步數(shù)大小影響著網(wǎng)絡(luò)的聚類性能,分別設(shè)置100、200和500步對(duì)網(wǎng)絡(luò)進(jìn)行訓(xùn)練,觀察性能[7,8];選用聚類效果較好的訓(xùn)練步數(shù)為500步的網(wǎng)絡(luò),利用自組織特征映射網(wǎng)絡(luò)選取聚類數(shù)目為6類,應(yīng)用訓(xùn)練數(shù)據(jù)對(duì)網(wǎng)絡(luò)進(jìn)行訓(xùn)練,保存網(wǎng)絡(luò)參數(shù)的訓(xùn)練結(jié)果,以及訓(xùn)練數(shù)據(jù)的離散結(jié)果,然后利用訓(xùn)練后的網(wǎng)絡(luò)對(duì)測(cè)試數(shù)據(jù)進(jìn)行離散化處理,即可得到離散化結(jié)果,如圖2所示,可見(jiàn)6種故障模式分別占據(jù)不同區(qū)域,可作為故障診斷故障基準(zhǔn)。
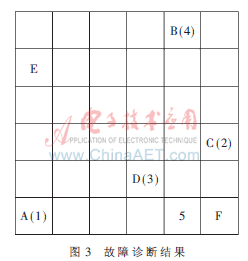
競(jìng)爭(zhēng)層輸出的不同的神經(jīng)元代表了不同的故障類型,系統(tǒng)某種故障與標(biāo)準(zhǔn)樣本的故障類型越相似,在競(jìng)爭(zhēng)層上的興奮神經(jīng)元的幾何位置也就越接近。模擬某電子設(shè)備的典型故障,試驗(yàn)中選取了5個(gè)故障樣本,經(jīng)模糊量化后得到待檢故障模式,如表2所示。

將其輸入到已訓(xùn)練好的SOFM神經(jīng)網(wǎng)絡(luò),在競(jìng)爭(zhēng)層中出現(xiàn)了圖3的分類結(jié)果。第1組故障樣本輸出的幾何距離Di最接近故障形式A,表明該故障形式為末級(jí)組件電路故障;同理,可判斷第2組故障樣本的故障形式為激勵(lì)產(chǎn)生故障;第3組和第4組故障樣本的輸出分別與D和B的位置重合,表明第3組和第4組故障樣本的故障形式分別為PIN開(kāi)關(guān)故障和前級(jí)組件電路故障;第5組故障樣本的輸出最接近F,表明該故障形式可能為饋線故障。診斷結(jié)果與仿真機(jī)模擬的故障一致。
模糊聚類分析是依據(jù)客觀事物間的特征、親疏程度和相似性,通過(guò)建立模糊相似關(guān)系,對(duì)客觀事物進(jìn)行分類的數(shù)學(xué)方法。用模糊聚類分析方法處理帶有模糊性的聚類問(wèn)題更客觀、靈活和直觀,且計(jì)算更加簡(jiǎn)便。實(shí)踐表明,它突破了常規(guī)邏輯推理方法的局限,在很少先驗(yàn)知識(shí)的情況下,能快速而準(zhǔn)確地解決故障診斷問(wèn)題。
參考文獻(xiàn)
[1] 楊軍,馮振聲,黃考利,等.裝備智能故障診斷技術(shù)[M]. 北京:國(guó)防工業(yè)出版社,2004:119-122.
[2] 何青,張海巖,張志.基于C8051F的便攜式多通道數(shù)據(jù)采集系統(tǒng)[J].儀器儀表學(xué)報(bào),2006,27(6):140-141.
[3] WANG X,ILTON H.DBRS:a density based spatial clustering method with random sampling[C].Proceedings of the 7th PAKDD.Seoul,Korea,2003:563-575.
[4] TROST B,L IANG M.Mechanical fault detection using fuzzy index fusion[J].International Journal of Machine Tools & Manufacture,2007(47):1702-1714.
[5] CZESLAW T K,TERESA O K.Neural networks application for induction motor faults diagnosis[J].Mathematics and Computers in Simulation,2003(63):435-448.
[6] 程昌銀,李琳.模糊神經(jīng)網(wǎng)絡(luò)故障診斷研究[J].武漢理工大學(xué)學(xué)報(bào),2002,24(1):220-225.
[7] 羅志勇.雷達(dá)系統(tǒng)智能故障診斷技術(shù)研究[D].西安:西北工業(yè)大學(xué),2006.
[8] PAKKANEN J.The evolving tree,a new kind of self-organizing neural network[C].Proceedings of the Workshop on Self-Organizing Maps,Kitakyushu,Japan,2003:311-316.