
摘 要: 提出了一種基于WordNet和GVSM的文本相似度算法,通過(guò)語(yǔ)義的路徑長(zhǎng)度和路徑深度計(jì)算兩個(gè)詞的語(yǔ)義相似度,結(jié)合改進(jìn)的GVSM模型計(jì)算文本相似度,并對(duì)基于TFIDF-VSM模型和本文方法進(jìn)行了比較。實(shí)驗(yàn)結(jié)果表明,該算法取得了更好的準(zhǔn)確率和效率。
關(guān)鍵詞: 文本相似度;語(yǔ)義相似度;詞網(wǎng);廣義向量空間模型
文本相似度計(jì)算在文本信息處理相關(guān)領(lǐng)域有著廣泛的應(yīng)用。目前,文本相似度的研究主要有三種方式:(1)篇章與篇章之間的相似度計(jì)算[1];(2)短語(yǔ)與篇章之間的相似度計(jì)算;(3)短語(yǔ)與篇章中段落的相似度計(jì)算。文本相似度計(jì)算方法主要有隱性語(yǔ)義索引模型、向量空間模型、廣義向量空間模型、基于屬性論的方法、基于海明距離的計(jì)算方法、基于數(shù)字正文的重構(gòu)方法等。基于語(yǔ)義的相似度計(jì)算方法相關(guān)的研究主要有:使用WordNet進(jìn)行相似度計(jì)算的方法;使用同義詞詞林進(jìn)行相似度計(jì)算的方法[2];使用知網(wǎng)《HowNet》知識(shí)結(jié)構(gòu)進(jìn)行相似度計(jì)算的方法[3]。廣義向量空間模型(GVSM) 是20世紀(jì)80年代由Wong提出[4],在詞語(yǔ)消歧研究[1]、文本檢索研究[5]等方面得到了很好的應(yīng)用。
本文使用WordNet進(jìn)行相似度計(jì)算的方法,采用廣義向量空間模型, 并對(duì)廣義向量空間模型進(jìn)行了擴(kuò)展,得到了新的廣義向量空間模型。通過(guò)WordNet計(jì)算兩個(gè)詞的語(yǔ)義相似度,把語(yǔ)義相似度應(yīng)用到GVSM模型中來(lái)計(jì)算文本相似度。實(shí)驗(yàn)結(jié)果表明,該算法取得了較好的準(zhǔn)確率和效率。
1 背景知識(shí)介紹
1.1 向量空間模型
向量空間模型(VSM)是20世紀(jì)70年代末由Salton等[6]提出的一種代數(shù)模型。在近30年內(nèi),向量空間模型(VSM)被廣泛應(yīng)用到信息檢索、文本分類、文本聚類等領(lǐng)域,并取得了很好的效果。其基本思想是:假設(shè)詞與詞之間是不相關(guān)的,以向量表示文本,每個(gè)維度對(duì)應(yīng)于一個(gè)單獨(dú)的詞,則(w1,w2,w3,…,wn)文檔dk可以看成相互獨(dú)立的詞條(t1,t2,t3,…,tn),為了表示詞條的重要程度,給每個(gè)詞條賦予相應(yīng)的權(quán)值wi,其中文檔dk可用向量(w1,w2,w3,…,wn)表示。向量空間模型中的文檔相似度計(jì)算方法為:
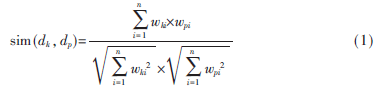
其中wki、wpi分別是詞ti在dk和dp的權(quán)值,n是向量的維度。向量空間模型的前提是假設(shè)詞與詞之間是不相關(guān)的,但這種假設(shè)不現(xiàn)實(shí),因?yàn)樵~與詞之間往往存在語(yǔ)義相關(guān)。
1.2 廣義向量空間模型
廣義向量空間模型GVSM擴(kuò)展的VSM模型,GVSM引入了詞與詞之間的相關(guān)度,并提出了一個(gè)新的向量空間,每個(gè)向量ti被表示成2n維向量mr,其中r=1,2,…,2n。文檔相似度計(jì)算方法為:
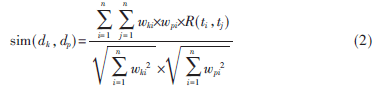
其中wki、wpi分別是詞ti在dk和dp的權(quán)值,R(ti,tj)是詞ti和tj的相關(guān)度。
1.3 WordNet介紹
WordNet由普林斯頓大學(xué)認(rèn)知科學(xué)實(shí)驗(yàn)室在1985年建立,是一部在線詞典數(shù)據(jù)庫(kù)系統(tǒng),采用了與傳統(tǒng)詞典不同的方式,即按照詞義而不是詞形來(lái)組織詞匯信息。WordNet將英語(yǔ)的名詞、動(dòng)詞、形容詞、副詞組織為Synsets,每一個(gè)Synset表示一個(gè)基本的詞匯概念,并在這些概念之間建立了包括同義關(guān)系(synonymy)、反義關(guān)系(antonymy)、上下位關(guān)系(hypernymy & hyponymy)、部分關(guān)系(meronymy)等多種語(yǔ)義關(guān)系。不同的邊代表不同的語(yǔ)義關(guān)系。
2 文檔相似度計(jì)算
2.1 語(yǔ)義相似度計(jì)算
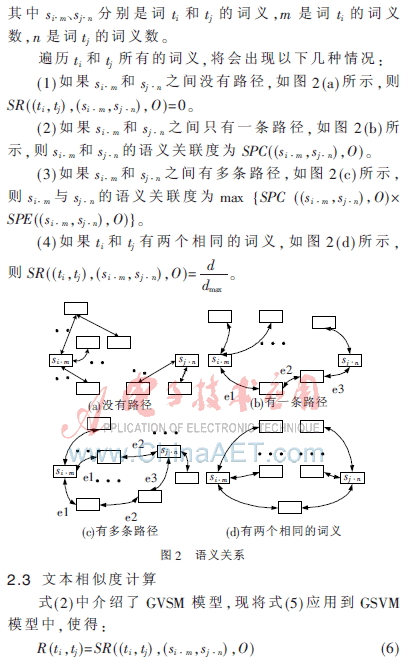
本文模型中使用WordNet衡量?jī)蓚€(gè)詞的語(yǔ)義關(guān)系。分別考慮了路徑長(zhǎng)度SPC(Semantic Path Compactness)和路徑深度SPE(Semantic Path Elaboration),給定兩個(gè)詞的語(yǔ)義相關(guān)度SR(Semantic Relatedness)由SPC和SPE合并得出。下面給出相關(guān)定義。

2.2 語(yǔ)義網(wǎng)絡(luò)構(gòu)建
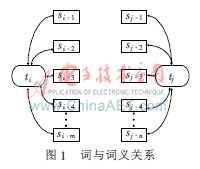
為了計(jì)算兩個(gè)詞的語(yǔ)義關(guān)聯(lián)度,需要構(gòu)建語(yǔ)義網(wǎng)絡(luò),采用了文獻(xiàn)[7]的方法。相比較其他方法,它嵌入所有可用的WordNet的語(yǔ)義信息并提供了豐富的語(yǔ)義表達(dá)。根據(jù)所采用語(yǔ)義網(wǎng)絡(luò)建設(shè)模式,每種類型的邊將被賦予各自的權(quán)值,權(quán)重越高說(shuō)明它們的語(yǔ)義關(guān)聯(lián)度越高(如上位/下位邊的權(quán)值定義為0.57)。詞與詞義的關(guān)系在語(yǔ)義網(wǎng)中如圖1所示。

3 實(shí)驗(yàn)
利用上述方法,本文實(shí)現(xiàn)了基于WordNet的語(yǔ)義相似度計(jì)算程序模塊。為了對(duì)相似度計(jì)算結(jié)果更好地進(jìn)行分析,本文評(píng)價(jià)的方案放在文本分類系統(tǒng)中,以觀察不同計(jì)算方法對(duì)文本分類系統(tǒng)性能的影響。
3.1 實(shí)驗(yàn)評(píng)價(jià)標(biāo)準(zhǔn)
評(píng)價(jià)標(biāo)準(zhǔn)是在測(cè)試過(guò)程中所使用的一些用來(lái)評(píng)價(jià)分類器分類準(zhǔn)確度的量化標(biāo)準(zhǔn)。本文采用常用的三種標(biāo)準(zhǔn),它們?cè)诓煌姆矫鎭?lái)評(píng)價(jià)一個(gè)分類器。
準(zhǔn)確率(precision)= (分類正確的文本數(shù))/(實(shí)際分類的文本數(shù))
召回率(recall)= (分類正確的文本數(shù))/(應(yīng)有分類正確的文本數(shù))

3.2 實(shí)驗(yàn)結(jié)果與分析
本文實(shí)驗(yàn)是在Windows XP操作系統(tǒng)、Eclipse開(kāi)發(fā)環(huán)境下,通過(guò)Java語(yǔ)言實(shí)現(xiàn)。實(shí)驗(yàn)是在1 GB內(nèi)存、P4 3.0 GHz CPU的PC機(jī)下進(jìn)行的。實(shí)驗(yàn)數(shù)據(jù)集采用的是20-Newsgroups文本數(shù)據(jù)集。20-Newsgrops是在UseNet上下載的20個(gè)類的新聞組討論英文文章。數(shù)據(jù)集共有20個(gè)類,每個(gè)類大約1 000篇。20-Newsgroups是一個(gè)比較常用的文本數(shù)據(jù)集。出于效率考慮,本實(shí)驗(yàn)選取其中的5個(gè)類別,針對(duì)不同數(shù)量的訓(xùn)練文本進(jìn)行了實(shí)驗(yàn),實(shí)驗(yàn)分別選取了200、400、600、1 000、2 000篇文本平均分配到編號(hào)為A、B、C、D、E的5個(gè)集合。分別對(duì)基于TFIDF-VSM[3]模型和本文提出的基于WordNet的GVSM模型進(jìn)行了比較實(shí)驗(yàn)。本文采用KNN[8]分類器進(jìn)行評(píng)價(jià),測(cè)試結(jié)果記錄了上述5種情況分類器的準(zhǔn)確率、召回率、F1值。
實(shí)驗(yàn)結(jié)果表明,采用基于WordNet的GVSM模型比基于TFIDF-VSM模型具有更高的準(zhǔn)確率、召回率、F1值。分析發(fā)現(xiàn)當(dāng)文本數(shù)越多時(shí),文本分類的準(zhǔn)確率、召回率、F1值越高。
本文提出了一個(gè)新的文本相似度計(jì)算方法,將其成功地應(yīng)用在文本分類當(dāng)中,實(shí)驗(yàn)證明得到了很好的效果。首先基于WordNet構(gòu)建了語(yǔ)義網(wǎng),分別考慮路徑長(zhǎng)度SPC和路徑深度SPE來(lái)計(jì)算兩個(gè)詞的語(yǔ)義關(guān)聯(lián)度;然后將其應(yīng)用在GVSM模型中計(jì)算文本相似度;最后應(yīng)用在文本分類中,得到了較高的分類準(zhǔn)確率和召回率。下一步準(zhǔn)備將其應(yīng)用到信息檢索中,以提高信息檢索的準(zhǔn)確率與效率。
參考文獻(xiàn)
[1] WILLETT P. Recent trends in hierarchical document clustering: a critical review. Inf Process and Manage, 1988:577-597.
[2] 夏天.漢語(yǔ)詞語(yǔ)語(yǔ)義相似度計(jì)算研究[J].計(jì)算機(jī)工程,2007,33(6):191-194.
[3] 李峰,李芳.中文詞語(yǔ)語(yǔ)義相似度計(jì)算——基于《知網(wǎng)》2000[J].中文信息學(xué)報(bào),2007,21(3):99-105.
[4] WONG, S. K. M. Wojciech Ziarko, Patrick C. N. Wong. Generalized vector spaces model in information retrieval.SIGIR ACM, 1985.
[5] TSATSARONIS G, PANAGIOTOPOULOU V. A generalized vector space model for text retrieval based on semantic relatedness. Proceedings of the EACL 2009 Student Research Workshop, 2009:70-78.
[6] SALTON, MCGILL M J. Introduction to modern information retrieval. McGraw-Hill, 1983.
[7] VAZIRGIANNIS T M. Word sense disambiguation with spreadingactivation networks generated from thesauri[C]. In Proc. of the 20th IJCAI, 2007:1725-1730.
[8] HALL P, PARK B U, SAMWORTH R J. Choice of neighbor order in nearest-neighbor classification. Annals of Statistics: 2008:2135-2152.
[9] Qinglin Guo. The similarity computing of documents based on VSM. IEEE International Computer Software and Applications Conference. 2008:585-586.