
摘 要: 通過對目前應(yīng)用廣泛的軟構(gòu)件檢索技術(shù)的研究,提出了一種基于軟構(gòu)件描述文本信息抽取的檢索方法。該方法利用中文分詞技術(shù)和向量空間模型中“詞頻與倒文檔頻度”算法抽取關(guān)鍵詞,通過《知網(wǎng)》語義相似度,計算用戶需求與可重用軟構(gòu)件的匹配度,實現(xiàn)了對軟構(gòu)件的語義檢索,能實現(xiàn)模糊查詢,具有一定的張弛能力。
關(guān)鍵詞: 構(gòu)件檢索;向量空間模型;知網(wǎng);語義相似度;信息抽取
隨著軟件開發(fā)規(guī)模的增大,軟件構(gòu)件技術(shù)被認為是解決軟件危機的有效途徑,基于構(gòu)件的軟件開發(fā)CBSD(Component Based Software Development)[1]成為有效提高軟件生產(chǎn)率、縮短軟件產(chǎn)品交付時間和提高軟件質(zhì)量的新方法。
傳統(tǒng)的軟構(gòu)件的檢索方法[2]主要有三種:基于外部索引的檢索、基于內(nèi)部靜態(tài)索引的檢索和基于內(nèi)部動態(tài)索引的檢索。其中以構(gòu)件的刻面表示以及在此基礎(chǔ)上的構(gòu)件檢索技術(shù)已得到軟件復(fù)用界的重視和應(yīng)用[3]。著名的REBOOT構(gòu)件庫[4]提出了可重用軟件構(gòu)件基于刻面的分類檢索方案。國內(nèi)的青鳥構(gòu)件庫[5]采用以刻面分類為主、多種分類模式相結(jié)合的方法對構(gòu)件進行分類描述。
傳統(tǒng)的基于關(guān)鍵字或刻面描述的軟件構(gòu)件的檢索由于缺少特定領(lǐng)域語義信息,使得用戶在查詢所需要的構(gòu)件時,有時很難對構(gòu)件的各個刻面作出準確的描述,因此在查準率和查全率上存在不足。準確地理解用戶的查詢請求是構(gòu)件檢索的一個重要問題,本文針對與軟構(gòu)件如影隨形的自然語言描述,提出一種基于軟構(gòu)件描述文本信息抽取的檢索方法。該方法采用自然語言描述軟構(gòu)件的實現(xiàn),并由系統(tǒng)利用自然語言處理技術(shù)抽取軟構(gòu)件特征信息和需求的特征信息,然后利用特征匹配和《知網(wǎng)》詞匯語義相似度計算獲得候選的結(jié)果。
1 軟構(gòu)件檢索系統(tǒng)體系結(jié)構(gòu)
有效的構(gòu)件檢索機制能夠降低構(gòu)件查找和理解的成本,檢索方式對構(gòu)件描述和用戶查詢的依賴是本文研究的主體部分。本文設(shè)計了基于文本描述的軟構(gòu)件檢索系統(tǒng)體系結(jié)構(gòu),如圖1所示。其各部分功能如下:
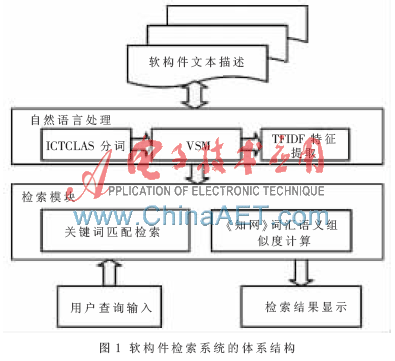
(1)軟構(gòu)件文本描述主要是將系統(tǒng)數(shù)據(jù)庫中有關(guān)軟構(gòu)件的文本描述信息提取出來進行自然語言處理,并將處理返回的結(jié)果存儲起來;主要負責(zé)與用戶交互,為用戶提供查詢接口,通過用戶輸入生成查詢條件,并將滿足條件的軟構(gòu)件信息返回給用戶。
(2)自然語言處理模塊主要是將數(shù)據(jù)庫的軟構(gòu)件文本描述信息集合在一起,通過ICTCLAS分詞技術(shù)獲得帶標注的分詞結(jié)果,并根據(jù)VSM中TFIDF的計算方法為每個軟構(gòu)件描述文本提取特征項并存儲;
(3)檢索模塊分為兩種方式:一種是將用戶查詢的特征與抽取出的軟構(gòu)件特征項通過《知網(wǎng)》詞匯語義相似度計算來獲取查詢結(jié)果,此種方法主要實現(xiàn)了軟構(gòu)件的語義檢索,是本文研究的重點;另一種是用戶查詢的特征與軟構(gòu)件特征項之間的匹配檢索。
這種層次結(jié)構(gòu)的體系模式將各模塊的功能相互獨立,有利于系統(tǒng)的維護與擴展,確保了系統(tǒng)的穩(wěn)定性和可維護性。
2 軟構(gòu)件檢索實現(xiàn)分析
檢索實現(xiàn)是本文研究的重點,尤其是實現(xiàn)軟構(gòu)件的語義檢索。通過上面軟構(gòu)件檢索系統(tǒng)的體系結(jié)構(gòu)圖可以看出,自然語言處理部分是實現(xiàn)語義檢索的基礎(chǔ),自然語言處理的準確度直接影響到檢索結(jié)果的查全率和查準率。
下面簡單介紹ICTCLAS漢語分詞系統(tǒng)和VSM的研究現(xiàn)狀,并詳細介紹語義檢索的實現(xiàn)過程。
2.1 ICTCLAS漢語分詞簡介
分詞系統(tǒng)[6]ICTCLAS(Institute of Computing Technology,Chinese Lexical Analysis System)是由中科院計算所的張華平、劉群所開發(fā)的一套獲得廣泛好評的分詞系統(tǒng)。它先通過層疊形馬爾可夫模型CHMM(Hierarchical Hidden Markov Model)進行分詞,通過分層,既增加了分詞的準確性,又保證了分詞的效率。ICTCLAS分詞速度單機500 KB/s,分詞精度98.45%,是世界上最好的漢語詞法分析器,并且在國內(nèi)973專家組組織的評測中獲得了第一名。
2.2 向量空間模型
向量空間模型VSM(Vector Space Model)由Salton等人于上世紀60年代末提出,并成功應(yīng)用于著名的SMART系統(tǒng),是目前最為成熟且應(yīng)用最為廣泛的文本表示模型之一[7]。它把對文本內(nèi)容的處理簡化為向量空間中的向量,用“詞頻與倒文檔頻度”TFIDF(Term-Frequency Inverse-Document-Frequency)[8]進行特征項賦權(quán)值,來表征某個特征項對該文本內(nèi)容的重要程度。其中TFIDF將一個特征項在某個文檔中的重要性和在整個文檔數(shù)據(jù)全集中的重要性結(jié)合起來,成為一個統(tǒng)一的度量值。它說明一個在單個文檔中頻度很高,而在整個數(shù)據(jù)全集中頻度很低的詞是更加重要的詞。
本文在自然語言處理過程中對文本關(guān)鍵詞的抽取正是提取VSM中TFIDF值較高的特征項,將通過此方法獲得的所有特征項按權(quán)值大小排序,提取滿足閾值或一定數(shù)目的最優(yōu)特征作為最終表達該文本特征的特征項集。
2.3 《知網(wǎng)》詞匯語義相似度計算
《知網(wǎng)》(HowNet)[9]是一部比較詳盡的語義知識詞典,是一個以漢語和英語詞義所代表的概念為描述對象,以揭示概念間及概念所具有的屬性間關(guān)系為基本內(nèi)容的常識知識庫。概念與義原是《知網(wǎng)》中的兩個主要概念。每一個詞可以表達為幾個概念,每個概念又可由若干個義原來描述。

以上是《知網(wǎng)》詞匯語義相似度的計算方法,是本文的一個重要部分,精確的詞匯匹配度是下一步檢索的基礎(chǔ)工作。
2.4 檢索模塊
通過抽取軟構(gòu)件文本描述特征項來實現(xiàn)基于語義的檢索是本文研究的重點。通過對相似度計算模塊得到的數(shù)據(jù)進行處理分析,是實現(xiàn)檢索的關(guān)鍵步驟,其主要處理流程如圖2所示。
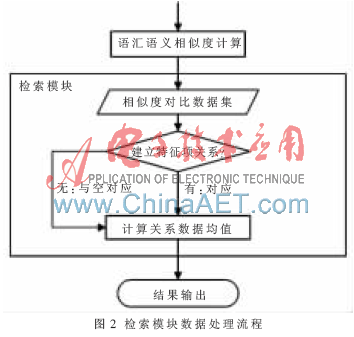
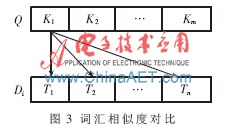
假設(shè)用戶查詢關(guān)鍵詞集合為Q{K1,K2,…,Km},某一軟構(gòu)件的文本描述向量空間模型的特征項表示為集合Di{T1,T2,…,Tn},其中Tj{j=1,2,…,n)為經(jīng)過自然語言處理的描述該構(gòu)件的特征項。
一般將兩個集合中的特征項兩兩比較得到的相似度的平均值作為它們的相似度,如此一個集合任意兩個特征項之間的相似度都為1,集合才能與它本身100%相似。本文采用以下算法為這兩個集合進行相似度計算:
(1)利用《知網(wǎng)》詞匯語義相似度,將Q中每個關(guān)鍵字與Di中每個特征項進行相似度計算,如圖3所示。得到Term_Sim{Sim(K1,T1),Sim(K1,T2),…,Sim(Ki,Tj),…,Sim(Km,Tn)}為相似度值集合,共m×n個數(shù)據(jù)。
(2)將相似度值中最大的值所對應(yīng)的Ki和Tj建立對應(yīng)關(guān)系。
(3)將包含Ki和Tj的相似度值從Term_Sim中刪除。
(4)重復(fù)(2)和(3),直到所有的相似度值都被刪除。
(5)沒有建立起對應(yīng)關(guān)系的關(guān)鍵字或特征項與空對應(yīng)。
(6)將包含Ki的相似度值取算術(shù)平均值。
把上面得到的平均值作為用戶查詢與軟構(gòu)件之間的相似度度量值,將滿足閾值的軟構(gòu)件信息按照相似度值的遞減順序輸出。
3 實驗結(jié)果
根據(jù)以上描述,實現(xiàn)了在ERP領(lǐng)域軟構(gòu)件的檢索,檢索結(jié)果如圖4所示。

實驗從ERP軟構(gòu)件描述數(shù)據(jù)庫中抽取出相似度較高的軟構(gòu)件作為候選結(jié)果輸出。其中,“成本管理”經(jīng)過ICTCLAS分詞、VSM處理得到的關(guān)鍵詞是:“成本”、“產(chǎn)品”、“計算”等,與用戶檢索關(guān)鍵詞“成本”、“分析”比較,相似度值是72.22%。在查詢結(jié)果中點擊相應(yīng)的項目,會詳細顯示對構(gòu)件的描述,可以幫助用戶更清晰地了解該構(gòu)件的信息,從而從候選結(jié)果中選擇符合要求的軟構(gòu)件。
本文提出了一種基于文本信息抽取的軟構(gòu)件檢索方法,并對軟構(gòu)件檢索系統(tǒng)的體系結(jié)構(gòu)、功能模塊進行了詳細介紹,優(yōu)化了關(guān)鍵字集合相似度計算;并且針對傳統(tǒng)軟構(gòu)件檢索中語義缺失的缺點,實現(xiàn)了對軟構(gòu)件的語義檢索的目的,有利于進行基于軟構(gòu)件的軟件開發(fā)。另外,本系統(tǒng)還有尚待改進的地方,例如:擴充分詞詞典,保證領(lǐng)域術(shù)語的完整性;增加軟構(gòu)件的圖形描述,實現(xiàn)多功能檢索等,這些問題也是下一步研究工作的重點。
參考文獻
[1] BROWN A W, WALLNAU K C. The current state of CBSE[J]. IEEE Software,1998,15(5):37-46.
[2] 劉韜,范菁,熊麗榮.構(gòu)件的檢索技術(shù)研究及其在信用領(lǐng)域構(gòu)件庫中的應(yīng)用[D].杭州:浙江工業(yè)大學(xué),2008.
[3] 舒遠仲,陳志勇,彭曉紅,等.基于刻面分類描述的構(gòu)件檢索方法研究[J]. 計算機工程與科學(xué), 2010,32(11):156-160.
[4] MOREL J M, FAGET J. The REBOOT environment[C].In: Prieto-Diaz R,Frakes WB eds.Processdings of the 2nd International Workshop on Software Reusability Advances in Software,Lucca:IEEE Computer Society Press,1993:80-88.
[5] CHANG J C, LI K Q,GUO L F,et al. Representing and retrieving reusable software components in JB(Jadebird)System[J]. Electronica Journal,2000,28(8):20-24.
[6] ICTCLAS分詞系統(tǒng)研究[EB/OL].(2010-08-24).http://wenku.baidu.com/view/2eeb4afff705cc175527093f.html.
[7] 楊小平,丁浩,黃都培.基于向量空間模型的中文信息檢索技術(shù)研究[J].計算機工程與應(yīng)用,2003(15):109-111.
[8] 王曉龍,關(guān)毅.計算機自然語言處理[M].北京:清華大學(xué)出版社,2005.
[9] 劉群,李素建.基于《知網(wǎng)》的詞匯語義相似度計算[C].臺北:第三屆漢語詞匯語義學(xué)研討會論文集,2002:59-76.