
摘 要: 核外計(jì)算中,由于I/O操作速度比較慢,所以對(duì)文件的訪問(wèn)時(shí)間占的比例較大。如果使文件操作和計(jì)算重疊則可以大幅度地提高運(yùn)行效率。軟件數(shù)據(jù)預(yù)取是一種有效的隱藏存儲(chǔ)延遲的技術(shù),通過(guò)預(yù)取使數(shù)據(jù)在實(shí)際使用之前從硬盤(pán)讀到緩存中,提高了緩存(cache)的命中率,降低了讀取數(shù)據(jù)的時(shí)間。通過(guò)設(shè)置兩個(gè)緩沖區(qū)來(lái)輪流存放本次和下一次讀入的數(shù)據(jù)塊,實(shí)現(xiàn)訪存完全命中cache的效果,使Cholesky分解并行程序執(zhí)行核外計(jì)算的效率得到了大幅度的提高。同時(shí),I/O操作的時(shí)間與CPU的執(zhí)行時(shí)間的比例也是影響效率的主要因素。
關(guān)鍵詞: 預(yù)取; 核外; 并行; 集群; Cholesky分解
隨著科學(xué)技術(shù)的迅猛發(fā)展,人們需要處理的數(shù)據(jù)量迅速增長(zhǎng)。大規(guī)模并行應(yīng)用涉及的數(shù)據(jù)量是非常驚人的,內(nèi)存容量常常不能滿(mǎn)足涉及到大數(shù)據(jù)量計(jì)算問(wèn)題的存儲(chǔ)需求。因待處理數(shù)據(jù)無(wú)法全部讀入內(nèi)存,所以只能保存數(shù)據(jù)到外部磁盤(pán)系統(tǒng)。當(dāng)程序運(yùn)行時(shí),某個(gè)時(shí)刻只能將部分?jǐn)?shù)據(jù)調(diào)入內(nèi)存并參加計(jì)算,并且在適當(dāng)?shù)臅r(shí)候?qū)懟赝獯妫ㄟ^(guò)某種策略實(shí)現(xiàn)內(nèi)外存數(shù)據(jù)的交換。由于運(yùn)算過(guò)程中數(shù)據(jù)并沒(méi)有全部存放在內(nèi)核存儲(chǔ)器中,所以稱(chēng)之為核外計(jì)算。核外計(jì)算程序中包含大量的文件操作,因訪問(wèn)磁盤(pán)數(shù)據(jù)的速度比較慢,所以在處理大數(shù)據(jù)量問(wèn)題時(shí),I/O性能顯然要超過(guò)CPU性能而成為重要的限制因素。因此,如何對(duì)核外數(shù)組進(jìn)行合理調(diào)度與高效訪問(wèn)是解決核外計(jì)算應(yīng)用問(wèn)題的關(guān)鍵。
利用三角分解式求解對(duì)稱(chēng)正定方程組是一種有效方法。單行卷簾存儲(chǔ)Cholesky分解[1]使每個(gè)節(jié)點(diǎn)所分配的數(shù)據(jù)最多相差一行,但是這種劃分方式的通信開(kāi)銷(xiāo)比較大。多行卷簾存儲(chǔ)Cholesky分解[2]可以減少通信開(kāi)銷(xiāo),充分利用節(jié)點(diǎn)的緩存,但是沒(méi)有充分考慮緩存的效率問(wèn)題,因?yàn)榫彺婵梢詫?duì)程序性能帶來(lái)巨大的改變。遞歸算法[3]通過(guò)將矩陣分塊使各個(gè)子矩陣的運(yùn)算能夠在高速緩存中進(jìn)行,以提高運(yùn)算效率,同時(shí)遞歸算法良好的數(shù)據(jù)局部性和矩陣遞歸的分塊,使其非常適合分層多級(jí)存儲(chǔ)的計(jì)算機(jī)結(jié)構(gòu)。但是在遞歸調(diào)度算法中,非對(duì)角塊的運(yùn)算不能充分利用計(jì)算機(jī)的分級(jí)存儲(chǔ)結(jié)構(gòu)。分塊Cholesky分解[4-5]通過(guò)精心的挑選塊的大小,使每個(gè)塊都能充分地利用一級(jí)緩存,并且合理地劃分塊的大小還能使每個(gè)塊常駐內(nèi)存。參考文獻(xiàn)文[4]充分利用了系統(tǒng)硬件的并行機(jī)制以使通信與計(jì)算重疊,減少了節(jié)點(diǎn)的等待時(shí)間。同時(shí)通過(guò)矩陣元素的重排使每個(gè)塊都被連續(xù)存儲(chǔ),以充分利用計(jì)算機(jī)的多層次存儲(chǔ)結(jié)構(gòu),減少數(shù)據(jù)拷貝和內(nèi)部的變化。但是這些算法只在數(shù)據(jù)量較小的情況下適用;當(dāng)數(shù)據(jù)量較大時(shí),數(shù)據(jù)將無(wú)法一次性讀入內(nèi)存,因此引進(jìn)了核外計(jì)算的概念。
本文對(duì)Cholesky分解的并行算法進(jìn)行了深入的研究,給出的核外算法通過(guò)預(yù)取[6-7]的方法使得數(shù)據(jù)在實(shí)際使用之前從硬盤(pán)移到緩存中,從而進(jìn)一步提高了緩存的命中率,減少了文件讀取的時(shí)間。
1基本概念

1.2 預(yù)取方法
在核外計(jì)算中數(shù)據(jù)存儲(chǔ)在磁盤(pán)上,只有CPU對(duì)數(shù)據(jù)進(jìn)行處理時(shí)才將其讀入內(nèi)存緩沖區(qū),處理完成后寫(xiě)回文件。這樣,核外計(jì)算過(guò)程就可以描述成:讀入核外數(shù)組文件的一塊數(shù)據(jù)到內(nèi)存緩沖區(qū),進(jìn)行計(jì)算等處理,處理完成后將其寫(xiě)回?cái)?shù)組文件;讀取下一塊數(shù)據(jù),進(jìn)行數(shù)據(jù)處理,處理完成后寫(xiě)回文件。如此反復(fù)執(zhí)行,直到整個(gè)核外數(shù)組處理完成后結(jié)束。顯而易見(jiàn),這是一個(gè)順序流水線,執(zhí)行I/O操作與CPU進(jìn)行計(jì)算是順序執(zhí)行的;由于二者在執(zhí)行前需彼此等待,所以程序的執(zhí)行效率非常低。于是考慮到,當(dāng)I/O操作的數(shù)據(jù)與CPU執(zhí)行計(jì)算的數(shù)據(jù)無(wú)相關(guān)性時(shí),可以把對(duì)下一個(gè)數(shù)據(jù)塊的I/O操作與對(duì)當(dāng)前數(shù)據(jù)塊的計(jì)算重疊起來(lái),這樣就可以隱藏I/O的延遲,達(dá)到縮短整個(gè)程序運(yùn)行時(shí)間的目的。圖1所示為數(shù)據(jù)預(yù)取前后的對(duì)比。

本算法采用雙緩沖區(qū)的方式,即為一個(gè)核外數(shù)組分配兩個(gè)內(nèi)存緩沖區(qū)buffer[2],輪流存放本次和下一次讀入的數(shù)據(jù)塊。用預(yù)取的方法對(duì)第s個(gè)子文件更新,其偽碼如下:
(1)主節(jié)點(diǎn)將第一個(gè)子文件讀入內(nèi)存數(shù)組buffer[0]中,并將其廣播出去;
(2)依次用已分解的子文件更新第s個(gè)子文件,即對(duì)ka=1,2,……,s-1循環(huán):
若該節(jié)點(diǎn)是主節(jié)點(diǎn),做以下工作:①讀入第ka個(gè)文件到buffer[ka%2]中;②發(fā)送第ka個(gè)文件;
若該節(jié)點(diǎn)是從節(jié)點(diǎn),則做以下工作:①用第ka-1個(gè)文件更新第s個(gè)文件;②接收第ka個(gè)文件。
(3)若該節(jié)點(diǎn)是從節(jié)點(diǎn),則用第s-1個(gè)文件更新第s個(gè)文件。
2 用預(yù)取算法實(shí)現(xiàn)Cholesky分解
2.1 Cholesky分解并行算法的思想
將大規(guī)模矩陣A連續(xù)拆分成q個(gè)子文件,并將其儲(chǔ)存到主節(jié)點(diǎn)中。主節(jié)點(diǎn)一次調(diào)入內(nèi)存一個(gè)子文件,依次對(duì)各子文件進(jìn)行Cholesky分解,直至最后一個(gè)子文件分解完畢。所以只要拆分的子文件大小不超過(guò)空閑內(nèi)存的范圍,算法就可以運(yùn)行。其算法流程見(jiàn)圖2,具體步驟如下:
(1)文件拆分過(guò)程
由主節(jié)點(diǎn)機(jī)進(jìn)行矩陣拆分存儲(chǔ)的操作,打開(kāi)存儲(chǔ)于硬盤(pán)中的A.txt文件,依內(nèi)存容量的需要進(jìn)行拆分,讀取相應(yīng)規(guī)模的數(shù)據(jù),生成子文件,并將這些子文件j.txt(j=1,2,3)存儲(chǔ)回硬盤(pán)。
(2)A陣的Cholesky分解過(guò)程
考慮到Cholesky分解過(guò)程中的依賴(lài)關(guān)系,對(duì)其由上至下依次進(jìn)行分解。由于在三角分解中,既需要分解后的上三角,又需要分解后的下三角,所以可以將分解后的上三角復(fù)制到下三角。這樣既可以減少運(yùn)算量又可以減少存儲(chǔ)量。在分解過(guò)程中利用其并行性,主節(jié)點(diǎn)打開(kāi)第一個(gè)子文件1.txt后,賦值給a6×15,再將a廣播出到各個(gè)從節(jié)點(diǎn)。每個(gè)從節(jié)點(diǎn)經(jīng)卷簾計(jì)算出分解因子后,廣播出去,如此地計(jì)算kb=2次,該子文件的Cholesky分解完畢。當(dāng)1.txt計(jì)算結(jié)束后,主節(jié)點(diǎn)打開(kāi)下一個(gè)子文件2.txt,賦值給a6×15,再將a廣播到各個(gè)從節(jié)點(diǎn)。同時(shí)主節(jié)點(diǎn)還要打開(kāi)分解完畢的子文件1.txt,賦值給aa6×15(即buffer[0]),再將aa廣播到各個(gè)從節(jié)點(diǎn)。各個(gè)從節(jié)點(diǎn)用aa6×15卷簾去更新a6×15,更新完畢后a6×15再像上面的操作,每個(gè)從節(jié)點(diǎn)卷簾的計(jì)算出分解因子后,廣播出去,如此的計(jì)算kb=2次后,主節(jié)點(diǎn)打開(kāi)下一個(gè)子文件3.txt,進(jìn)行如文件2.tx的操作。
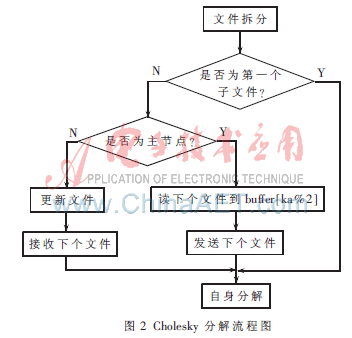
2.2 Cholesky分解并行算法的描述
將A連續(xù)拆分存儲(chǔ)到q個(gè)子文件中,依次對(duì)各子文件進(jìn)行Cholesky分解,直至對(duì)最后一個(gè)子文件分解后,原大規(guī)模系數(shù)矩陣已被拆分到幾個(gè)小文件中存儲(chǔ)。將節(jié)點(diǎn)機(jī)分別標(biāo)記為P0,P1…Pnp,np代表從節(jié)點(diǎn)機(jī)個(gè)數(shù),P0代表主節(jié)點(diǎn),kb表示在一個(gè)子文件中單個(gè)節(jié)點(diǎn)機(jī)計(jì)算的行數(shù),s是子文件依次分解的循環(huán)控制變量,ka表示讀取已分解子文件的循環(huán)控制變量,在拆分后a∈R[kb×np]×n,aa∈R[kb×np]×n。具體步驟如下:
(1)文件拆分
主節(jié)點(diǎn)機(jī)打開(kāi)存于硬盤(pán)中的A.txt文件,按內(nèi)存容量的需要進(jìn)行拆分,讀取相應(yīng)規(guī)模的數(shù)據(jù),生成q個(gè)子文件。
其中,q=n/(np×kb),q×np×kb=nn/(np×kb)+1,其他
(2)A矩陣的Cholesky分解過(guò)程
①1.txt(s=0)的Cholesky分解:(a)主節(jié)點(diǎn)打開(kāi)1.txt,讀取文件內(nèi)容,賦值到a[np*kb][n]數(shù)組中,并將數(shù)組a廣播出去。(b)從節(jié)點(diǎn)myid(myid=1,2,……,np)將數(shù)組a中的第i行(i%np=myid-1)進(jìn)行Cholesky分解。(c)從節(jié)點(diǎn)將已分解的對(duì)角元素賦給數(shù)組d[n]。(d)從節(jié)點(diǎn)用數(shù)組a已分解的元素重寫(xiě)其下三角。(e)從節(jié)點(diǎn)將分解后的數(shù)組a寫(xiě)回主節(jié)點(diǎn)。
②文件j.txt(s=1,2,……,q-1,j=s+1)的Cholesky分解:(a)主節(jié)點(diǎn)打開(kāi)并讀取j.txt內(nèi)容,賦值到a且將其廣播出去。(b)用預(yù)取的方法對(duì)第j個(gè)子文件更新。即主節(jié)點(diǎn)依次打開(kāi)已分解文件ka.txt(ka=0,1,…,s-1),賦值給buffer[ka%2],并將buffer[ka%2]廣播出去。在各個(gè)從節(jié)點(diǎn)根據(jù)buffer[ka%2]的值更新數(shù)組a值的同時(shí),主節(jié)點(diǎn)讀取下一個(gè)已分解的文件。(c)用數(shù)組buffer[ka%2]的元素重寫(xiě)數(shù)組a的下三角。(d)將數(shù)組a進(jìn)行Cholesky分解。(e)將數(shù)組a本次分解的對(duì)角線元素賦值給數(shù)組d[n]。(f)用數(shù)組a本次分解的元素重寫(xiě)其下三角。(g)將分解后的數(shù)組a寫(xiě)回主節(jié)點(diǎn)。
2.3 算法的復(fù)雜度分析
對(duì)于點(diǎn)對(duì)點(diǎn)的通信,測(cè)量開(kāi)銷(xiāo)使用乒乓法:節(jié)點(diǎn)0發(fā)送m個(gè)字節(jié)給節(jié)點(diǎn)1;節(jié)點(diǎn)1從節(jié)點(diǎn)0接收m個(gè)字節(jié)后,立即將消息發(fā)回節(jié)點(diǎn)0。總的時(shí)間除以2,即可得到點(diǎn)到點(diǎn)通信時(shí)間,也就是執(zhí)行單一發(fā)送或接收操作的時(shí)間。通信開(kāi)銷(xiāo)的解析表達(dá)式是消息長(zhǎng)度m(字節(jié))的線性函數(shù):tcomm(m)=Ts+Tb×m;其中Ts表示通信的啟動(dòng)時(shí)間,Tb表示發(fā)送每個(gè)字節(jié)所需時(shí)間(它是帶寬的倒數(shù))。由于MPI_Bcast 函數(shù)采用樹(shù)算法,所以一次MPI_Bcast的通信開(kāi)銷(xiāo)為tcomm(s)×logP。Cholesky分解的執(zhí)行時(shí)間可分為子文件的更新時(shí)間和自身分解時(shí)間。因此,Cholesky分解時(shí)間:Tc=Tg+Tf,其中Tg是子文件更新時(shí)間,Tf是自身的分解時(shí)間。在文件的更新時(shí)間中,又細(xì)化為讀文件時(shí)間Td、計(jì)算時(shí)間Tj和通信時(shí)間Tt。為了減少分解的執(zhí)行時(shí)間,本文通過(guò)預(yù)取的方法使更新過(guò)程中的讀文件與計(jì)算重疊,使得Cholesky分解的時(shí)間開(kāi)銷(xiāo):Tc<Tf+Td+Tj+Tt。當(dāng)文件的讀取與計(jì)算完全重疊時(shí),Cholesky分解的時(shí)間可表示為T(mén)c=Tf+Tt+max(Td,Tj)。
子文件的大小是通過(guò)參數(shù)kb(1≤kb≤n/np)而設(shè)定的,當(dāng)kb=n/np時(shí)相當(dāng)于無(wú)文件劃分并行求解;當(dāng)kb=1時(shí),在每個(gè)子文件中每個(gè)節(jié)點(diǎn)機(jī)只計(jì)算一行,此時(shí)的通信量最大(按照這種分配方法劃分?jǐn)?shù)據(jù)后,每個(gè)處理器上須存儲(chǔ)的內(nèi)容為kb×np×n規(guī)模的矩陣A)。因此算法的并行執(zhí)行時(shí)間:Tn=T1+Tc+T2,其中,T1為劃分子文件消耗的時(shí)間,Tc是Cholesky分解時(shí)間,T2為冗余的控制和管理開(kāi)銷(xiāo)。
3 實(shí)驗(yàn)測(cè)試與結(jié)果分析
實(shí)驗(yàn)環(huán)境采用由5臺(tái)主頻為2.8 GHz的Intel Xeon CPU,內(nèi)存為ECC DDR-2 SDRAM 2 GB的Dell PowerEdge 2850構(gòu)建的集群。該集群運(yùn)行Linux RH9操作系統(tǒng),并且建立了MPI并行編程環(huán)境。本文測(cè)試的兩個(gè)程序分別為:帶狀循環(huán)劃分的核外程序out和帶狀循環(huán)劃分的核外預(yù)取程序pre。
表1表示當(dāng)A的階數(shù)n=2 478,核外Cholesky分解各個(gè)部分的執(zhí)行時(shí)間對(duì)比。表2表示了在節(jié)點(diǎn)數(shù)np分別為2,3,4,5時(shí),Cholesky分解中的子文件更新各個(gè)部分的時(shí)間對(duì)比(kb=10,n=2 479)。圖3為核外預(yù)取程序相對(duì)于核外程序更新時(shí)間的效率提高百分比。

由表1可見(jiàn),在求解過(guò)程中Cholesky分解中的更新部分占了大部分時(shí)間,所以提高更新部分的執(zhí)行率能明顯縮短總的執(zhí)行時(shí)間。
由表2可見(jiàn),預(yù)取方法使得子文件的更新時(shí)間平均縮短了15%左右。
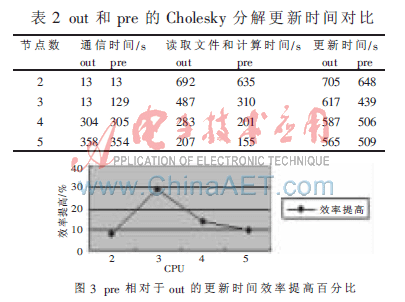
圖3表明,核外預(yù)取分解并行算法的效率明顯好于核外分解并行算法,并且隨著節(jié)點(diǎn)個(gè)數(shù)的增加,提高的效率先增大后減小。這是因?yàn)殡S著節(jié)點(diǎn)數(shù)目的增加,子文件容量增加,計(jì)算量增加,計(jì)算與文件讀取的重疊時(shí)間越多。在節(jié)點(diǎn)數(shù)np=3時(shí),效率提高幅度最大。當(dāng)節(jié)點(diǎn)數(shù)np>3時(shí),隨著節(jié)點(diǎn)數(shù)的增加通信時(shí)間急劇增加,而計(jì)算時(shí)間逐漸減少,計(jì)算與文件讀取的重疊時(shí)間減少,所以執(zhí)行效率提高的幅度降低。
本文通過(guò)對(duì)Cholesky分解并行算法的研究,表明預(yù)取方法是計(jì)算核外稠密線性方程組的有效方法,非常有利于縮短I/O與CPU速度間的差距。數(shù)據(jù)預(yù)取的方法可以做到計(jì)算與I/O并行,即在計(jì)算一塊數(shù)據(jù)的同時(shí)讀入下一塊要處理的數(shù)據(jù)。為了存放預(yù)取的數(shù)據(jù),本文采用雙緩沖區(qū)的方式,即為一個(gè)核外數(shù)組分配兩個(gè)內(nèi)存緩沖區(qū),輪流存放本次和下一次讀入的數(shù)據(jù)塊。此外,預(yù)取方法同樣適用于QR分解、LU分解、高斯削去等其他線性代數(shù)問(wèn)題。當(dāng)然采用數(shù)據(jù)預(yù)取技術(shù)時(shí),I/O操作時(shí)間與CPU執(zhí)行時(shí)間的比例是保證預(yù)取效果的關(guān)鍵。
事實(shí)上,Cholesky分解也可以采用數(shù)據(jù)重用的方法。通過(guò)減少對(duì)子文件的讀取次數(shù),可以進(jìn)一步提高Cholesky分解算法的效率。由于目前分布存儲(chǔ)計(jì)算機(jī)的處理速度都很高,而其網(wǎng)絡(luò)通信速度較慢,所以用增加計(jì)算和通信粒度的辦法來(lái)降低通信成本。
參考文獻(xiàn)
[1] 遲學(xué)斌. Transputer上Cholesky分解的并行實(shí)現(xiàn)[J]. 計(jì)算數(shù)學(xué),1993(3):289-294.
[2] 王順緒,周樹(shù)荃.卷簾行存儲(chǔ)下的一種并行Cholesky分解及其在PAR95上的實(shí)現(xiàn)[J].南京航空航天大學(xué)學(xué)報(bào),1999,31(4):428-432.
[3] 陳建平. Jerzy Wasniewski,Cholesky分解遞歸算法與改進(jìn)[J].計(jì)算機(jī)研究與發(fā)展,2001,38(8):923-926.
[4] GUSTAVSON F G, KARLSSON L, KAGSTRO B M. Distributed SBP cholesky factorization algorithms with nearoptimal scheduling[J]. ACM Transactions on Mathematical Software, 2009, 36(2):1-25.
[5] ANDERSEN B S, GUNNELS J A, GUSTAVSON F G, et al. A fully portable high performance minimal storage hybrid format cholesky algorithm[J]. ACM Transactions on Mathematical Software, 2005,31(2):201-227.
[6] 丁文魁,汪劍平,向華,等.p-HPF并行編譯系統(tǒng)核外計(jì)算的實(shí)現(xiàn)及優(yōu)化策略[J].計(jì)算機(jī)學(xué)報(bào),1999,22(10):1042-1049.
[7] 姚維.Linux下一種磁盤(pán)節(jié)能的預(yù)取算法[J].計(jì)算機(jī)系統(tǒng)應(yīng)用,2010,19(7):91-94.