
0 引言
隨著科技的發(fā)展,智能設(shè)備大量涌現(xiàn),其中智能汽車作為典型代表之一,對其進行研究開發(fā)也相當(dāng)普遍,當(dāng)然人與這些智能化設(shè)備之間快捷可靠的交互方式很多,其中語音辨識技術(shù)以其獨特的趣味性成為了人與智能系統(tǒng)交互方式中的熱點。本文所設(shè)計的智能小車利用語音辨識技術(shù),實現(xiàn)自動前進、后退、左拐、右拐和停車。
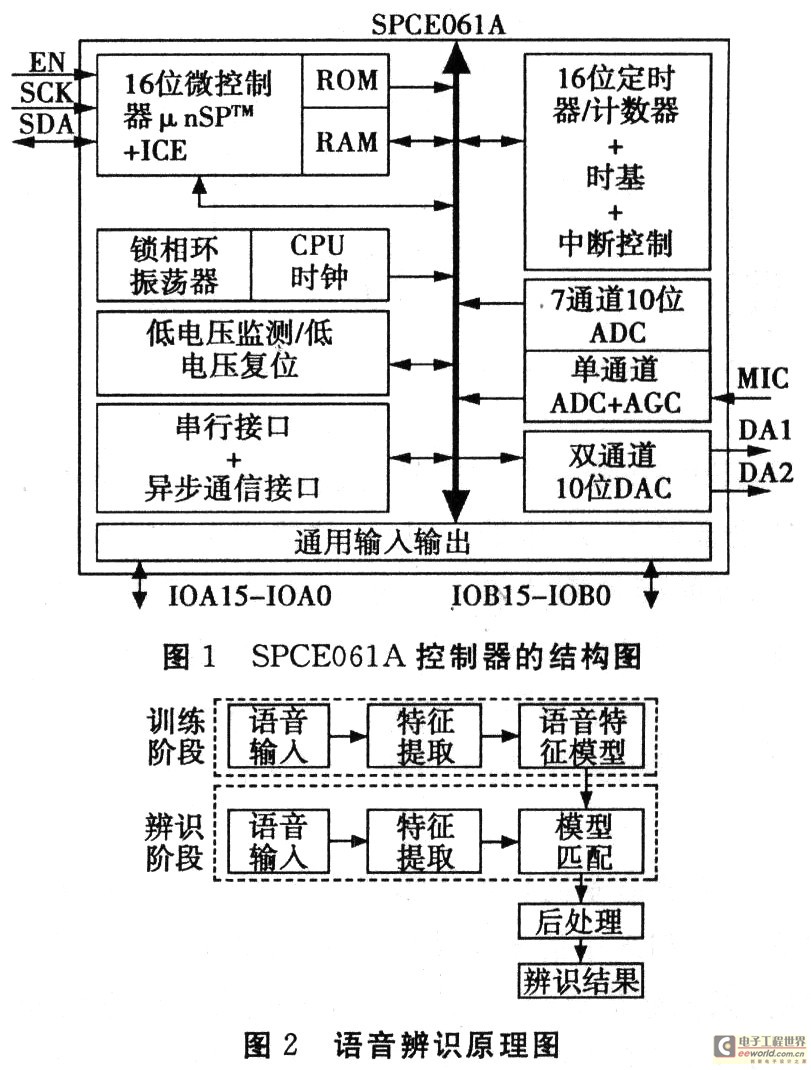
1 智能車語音辨識系統(tǒng)的開發(fā)平臺SPCE061A
采用語音辨識技術(shù)構(gòu)建的智能小車的語音辨識系統(tǒng)實現(xiàn)了小車的自動行駛,而SPCE061A控制器是構(gòu)建語音辨識系統(tǒng)的開發(fā)平臺。
SPCE061A是一款16位獨具語音特色的控制器,片內(nèi)采用的μ‘nSPTM(microcontroller and signal processor)核心處理器,具有較高的處理速度,能夠完成16位算術(shù)邏輯運算、16×16位硬件乘法運算和DSP內(nèi)積濾波運算、能夠快速處理復(fù)雜的數(shù)字信號,不需要額外的專用語音控制芯片,就能實現(xiàn)語音的編解碼等,既節(jié)省了設(shè)計成本,又能滿足一定的控制要求。控制器采用模塊化架構(gòu),集成了ICE(在線仿真)、鎖相環(huán)振蕩器、時基控制器、7通道10位AD轉(zhuǎn)換器、單通道AD+AGC(自動增益)轉(zhuǎn)換器、雙通道10位DA轉(zhuǎn)換器、通用異步通信接口、串行輸入輸出接口、電壓監(jiān)控等模塊,其結(jié)構(gòu)如圖1所示。
2 語音辨識的基本原理
語音辨識是建立在對人的語音交互過程的基礎(chǔ)上,它是一種多維模式辨識過程,分為訓(xùn)練和辨識兩個階段,其基本原理圖如圖2所示。辨識過程主要包括語音信號的預(yù)處理、特征提取、語音模型庫、模式匹配、后處理等幾個環(huán)節(jié)。預(yù)處理包括濾波、采樣和量化、加窗、端點檢測、預(yù)加重等過程,然后對預(yù)處理后的語音信號樣本進行分析處理,從中提取出語音特征信息,建立特征模型;之后開始模式匹配,將輸入語音信號的特征與已有的特征模型進行對比,如果兩者達到一定的匹配度,則輸入的語音被辨識。機器語音辨識處理的過程與人對語音辨識處理的過程基本上是一致的,目前主流的語音辨識技術(shù)是基于統(tǒng)計模式辨識的基本理論。
3 基于SPCE061A的語音辨識系統(tǒng)在智能小車上的實現(xiàn)
智能小車的語音控制系統(tǒng)以SPCE061A控制器和語音輸入電路、語音輸出電路為硬件基礎(chǔ),語音輸入電路如圖3所示,其中VMIC提供傳聲器的電源,VSS是系統(tǒng)的模擬地,VCM為參考電壓,1腳和2腳分別是傳聲器X1的正極、負極的輸入引腳,連接SPCE061A的MICP、NICN管腳上。當(dāng)對著傳聲器講話時,1腳和2腳將隨著傳聲器輸入的聲音產(chǎn)生變化的波形,并在SPCE061A的兩個端口處形成兩路反相的波形,送到SPCE061A控制器內(nèi)部的運算放大器進行音頻放大,經(jīng)過放大的音頻信號,通過 ADC轉(zhuǎn)化器轉(zhuǎn)化為數(shù)字量,保存到相應(yīng)的寄存器中。語音輸出電路如圖4所示,其中VDDH為參考電壓,VSS是系統(tǒng)的模擬地。音頻信號由SPCE061A 的DAC引腳輸出送到電路的9端,通過音量電位器R9的調(diào)節(jié)端送到集成音頻功率放大器SPY0030,經(jīng)音頻放大后,音頻信號從SPY0030輸出經(jīng)J2 端口外接揚聲器播放聲音。

SPCE061A配有專用的麥克接口用于語音訓(xùn)練和辨識階段的語音輸入,16位的定時/計數(shù)器用于語音信號的控制采樣,內(nèi)置的硬件乘法器和內(nèi)積運算保證了辨識算法的運行。在軟件方面,凌陽科技提供一個語音辨識函數(shù)庫bsrv222SDL.lib,它能夠完成特定人語音的連續(xù)辨識,包括訓(xùn)練函數(shù)和辨識函數(shù),還可以將訓(xùn)練好的特征模型導(dǎo)入和導(dǎo)出等。
由于語音命令的特征模型要保存到RAM中,所以首先擦除SPCE061A中的RAM,與語音訓(xùn)練做準(zhǔn)備。訓(xùn)練模式啟動后,系統(tǒng)播放語音提示,提示用戶語音訓(xùn)練已啟動,接下來用戶可按照系統(tǒng)提示依次對各條命令進行訓(xùn)練,在訓(xùn)練過程中,如訓(xùn)練成功則由語音提示進行下一條命令進行訓(xùn)練,若失敗,也會提示用戶繼續(xù)訓(xùn)練此條語音,全部命令訓(xùn)練完畢后系統(tǒng)將準(zhǔn)備進行語音辨識;當(dāng)向控制器發(fā)出語音命令時,聲波通過麥克端口輸入,將相應(yīng)的信號傳遞到SP-CEO61A處理芯片,經(jīng)編解碼電路和數(shù)字信號處理后,在芯片中通過相關(guān)程序與預(yù)先植入的語音庫中的命令進行比較辨識,根據(jù)辨識的結(jié)果進行判斷,轉(zhuǎn)換為能被系統(tǒng)辨識的信號,從而對被監(jiān)控系統(tǒng)進行控制。語音辨識的過程如圖5所示。

智能小車的語音辨識系統(tǒng)在SPCE061A上的實現(xiàn)過程可分為以下五個階段,如圖6所示。
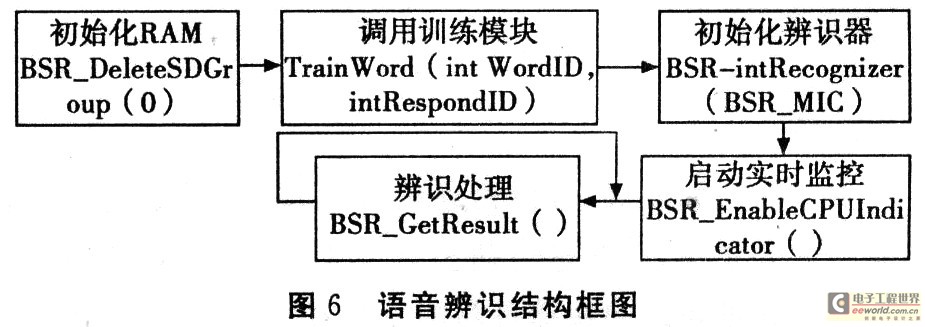
(1)初始化RAM
語音命令的特征模型被保存在SPCE061A的內(nèi)部
RAM中,如果所需的RAM空間被舊的特征模型數(shù)據(jù)占滿,新特征模型則無法保存到RAM中,利用BSR_DeleteS-DGroup(0)函數(shù)可以把 RAM空間中所有的特征模型刪除,釋放出所需的空間。當(dāng)RAM擦除成功BSR_DeleteS-DGroup(0)函數(shù)返回0,否則返回-1。
(2)調(diào)用訓(xùn)練模塊
語音訓(xùn)練過程通過調(diào)用函數(shù)im BSR_Train(int Corn-mandID,int TraindMode)來完成,CommandID為命令序號,范圍從0x100到0x105,并且對于每組訓(xùn)練語句都是唯一的。TraindMode為訓(xùn)練次數(shù),為1表示使用者訓(xùn)練一次,為2表示訓(xùn)練者訓(xùn)練兩次。為了增強可靠性,最好訓(xùn)練兩次,否則辨識的命令就會傾向于噪音,訓(xùn)練次數(shù)是2時,兩次一定會有一些差異,所以一定要保證兩次訓(xùn)練結(jié)果盡量接近。當(dāng)int BSR_Train返回0時表明語音訓(xùn)練成功。
(3)初始化辨識器
用來定義語音輸入來源,可以通過調(diào)用函數(shù)void BSR_InitRecognizer(int AudioSource)完成,其中參數(shù)Audio-Source為0時表示MIC語音輸入,為1時表示LINE_IN模擬電壓輸入。當(dāng)主程序調(diào)用該函數(shù)時,語音辨識器便打開8kHz采用頻率的FIQ_TMA中斷,并將采樣得到的語音數(shù)據(jù)填入語音辨識器的數(shù)據(jù)隊列中。
(4)啟動實時監(jiān)控
實時監(jiān)控是用來觀察語音辨識是否正常工作,如果辨識正常則會產(chǎn)生脈寬為16ms連續(xù)穩(wěn)定方波,否則會產(chǎn)生不穩(wěn)定的波形,此時需要刪除命令或優(yōu)化程序,否則將會丟失語音數(shù)據(jù),產(chǎn)生辨識出錯信息。完成此功能可以通過調(diào)用BSR_EnableCPUIndicator()函數(shù)來完成。
(5)辨識處理
由函數(shù)int BSR_GetResult()完成語音辨識處理,當(dāng)無命令辨識出來時,函數(shù)返回0;辨識器停止未初始化或辨識未激活返回-1;當(dāng)辨識不合格時返回-2;當(dāng)辨識出來時返回命令的序號。
4 實驗與結(jié)論
實驗中智能小車的正確辨識率在90%以上,實驗過程中發(fā)現(xiàn)影響小車正常辨識的因素主要包括周圍環(huán)境的噪音、人與小車的距離等,這些需要在今后的工作改正。需要說明的是在訓(xùn)練過程中中,每條語音命令的長度不要超過13 s,訓(xùn)練后得到的語音模型保存在RAM中,每條命令占用96Word。由于RAM空間有限,同時可辨識的語音命令為5條,為了運行復(fù)雜的辨識程序,必須通過擴展必要的存儲芯片完成系統(tǒng)的功能。
這種語音控制的智能小車機器人不僅可以將來為人服務(wù),稍加擴展,就可以在多種不適合人作業(yè)的場合替代人執(zhí)行任務(wù),因此這種語音控制小車機器人具有重要的學(xué)術(shù)研究價值。