
摘 要: 提出一種語音命令控制車載音響操作的設(shè)計方案,以德國Infineon公司新推出的具有DSP和單片機雙核的SoC語音處理芯片UniSpeech-SDA80D51為核心組成非特定人車載音響語音控制系統(tǒng),并實現(xiàn)了系統(tǒng)樣機的研制。該系統(tǒng)在江淮同悅SL1102C1型車載音響上進行了語音控制實測,實測數(shù)據(jù)表明系統(tǒng)語音識別率可達到95%。
關(guān)鍵詞: 非特定人語音識別;車載音響語音控制;UniSpeech-SDA80D51;隱馬爾可夫模型
隨著現(xiàn)代電子技術(shù)的發(fā)展,越來越多的車載電器被加入到車身電子行列中,其在使得汽車性能改善的同時,增加了汽車駕駛操作的復(fù)雜度,也給行車過程帶來了不安全的隱患。隨著語音識別算法的改進和新一代專用語音處理芯片的問世,出現(xiàn)了使用語音控制代替手動控制的車載電器,從而減輕駕駛員手動操作負擔(dān),大大提高行車安全系數(shù)。
目前我國的車身電子語音控制主要集中在汽車導(dǎo)航系統(tǒng)的應(yīng)用上,沒有充分發(fā)揮語音識別技術(shù)在車身電子中的應(yīng)用價值。本文首次提出了一種的以專用語音處理芯片UniSpeech-SDA80D51為核心組成非特定人車載音響語音控制系統(tǒng)的設(shè)計方案,并實現(xiàn)了系統(tǒng)樣機的研制。該系統(tǒng)在江淮同悅SL1102C1型車載音響上進行了語音控制實驗,實驗數(shù)據(jù)表明系統(tǒng)語音識別率可達到95%,為下一步項目產(chǎn)品化開發(fā)奠定了基礎(chǔ)。
1 車載音響語音控制系統(tǒng)
非特定人車載音響語音控制系統(tǒng)結(jié)構(gòu)框圖如圖1 所示。

系統(tǒng)的主要功能是:語音采集模塊(由定向拾音器組成)用于采集駕駛員發(fā)出的語音命令信號,由語音識別模塊實現(xiàn)信號的A/D轉(zhuǎn)換,并對轉(zhuǎn)換的數(shù)字信號進行語音識別處理,最終輸出與語音命令相對應(yīng)的詞條編碼信息。控制模塊對接收的詞條編碼信號進行邏輯分析與處理并產(chǎn)生對應(yīng)的控制信號,通過系統(tǒng)I/O接口驅(qū)動車載音響動作,完成駕駛員的語音命令。
1.1 語音識別模塊
語音識別模塊主要由UniSpeech-SDA80D51芯片及外圍電路組成。
SDA80D51是德國Infineon公司專為語音識別和語音處理應(yīng)用領(lǐng)域新推出的專用芯片,采用高集成度的SoC系統(tǒng)結(jié)構(gòu),以0.18 μm半導(dǎo)體工藝制造,SDA80D51的基本結(jié)構(gòu)如圖2所示。
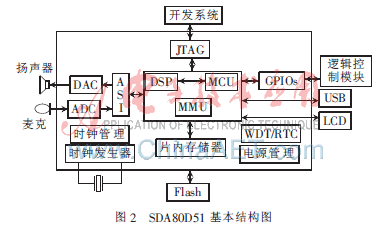
SDA80D51片內(nèi)集成了直接雙訪問快速SRAM、2路ADC和2路DAC、多種通信接口和通用GPIO等部件。SDA80D51工作方式以M8051為主控制芯片,主要完成系統(tǒng)配置和SPI、PWM、I2C、GPIO等接口的控制以及語音數(shù)據(jù)的傳輸工作;DSP核心OAK為協(xié)處理器,完成語音識別算法、語音編解碼算法等語音處理工作。
非特定人語音信號由定向拾音器輸入,經(jīng)過SDA80D51內(nèi)部的數(shù)據(jù)采集模塊進行A/D轉(zhuǎn)換,再經(jīng)過識別程序的預(yù)處理、端點檢測、特征參數(shù)提取、模板匹配等處理,選擇識別詞表中最接近的詞條序號作為識別結(jié)果,識別結(jié)果通過GPIO口輸出。
1.2 控制模塊
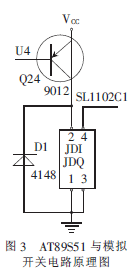
控制模塊由MCU和模擬開關(guān)電路構(gòu)成,本模塊主要完成對語音識別模塊輸出的詞條編碼信號進行邏輯分析和處理,通過模擬開關(guān)電路產(chǎn)生對應(yīng)功能的控制信號控制音響的動作。其中MCU選用美國ATMEL公司產(chǎn)品AT89S51,綜合AT89S51輸出I/O信號電壓特性和SL1102C1音響控制面板電阻式分流鍵盤電路的特點,確定使用繼電器模擬SL1102C1控制面板按鍵的閉合和斷開動作。AT89S51和繼電器模擬開關(guān)電路原理圖如圖3所示。
1.3 音響模塊
本設(shè)計是基于SL1102C1型汽車音響。SL1102C1是專門為中檔轎車設(shè)計的汽車音響,具有MP3播放、收音機和顯示時間等功能,目前大量使用在江淮同悅轎車上。SL1102C1前板共有開關(guān)機/靜音、音效、播放/暫停等15個按鍵和一個用來調(diào)節(jié)音量的編碼開關(guān)。
SL1102C1前板上的按鍵為電壓采樣識別方式,按鍵包含短按和長按兩種動作,AT89S51輸出電壓為TTL電平,直接采用I/O信號驅(qū)動音響按鍵動作容易引起誤識別,造成系統(tǒng)誤操作,因此本文采用圖3所示的模擬開關(guān)電路,很好地解決了上述問題。當(dāng)AT89S51接收到語音編碼信號后,立即進行邏輯分析并輸出對應(yīng)的控制信號驅(qū)動相應(yīng)繼電器吸合模擬按鍵動作,按鍵的短按和長按功能是通過軟件實現(xiàn)的。
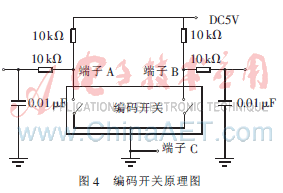
模擬開關(guān)電路還適用于SL1102C1前板上的編碼開關(guān),編碼開關(guān)具有音量調(diào)節(jié)功能,其工作原理如圖4所示。
由圖4可知,編碼開關(guān)上有A、B、C三個端子,開關(guān)旋鈕左、右旋轉(zhuǎn)時,A、B端子輸出對應(yīng)的脈沖信號。當(dāng)MCU收到操作編碼開關(guān)的語音命令信號后,驅(qū)動繼電器動作,控制端子A、B輸出信號,模擬開關(guān)旋鈕功能。
2 系統(tǒng)軟件設(shè)計
系統(tǒng)的軟件包括非特定人語音識別模塊和邏輯控制模塊。
2.1 非特定人語音識別模塊
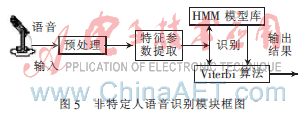
非特定人語音識別模塊基于HMM模型算法。該算法通過對大量語音數(shù)據(jù)進行數(shù)據(jù)統(tǒng)計,建立識別詞條的統(tǒng)計模型語音庫,然后從待識別語音中提取特征,與模型庫進行匹配,由比較匹配分數(shù)得到識別結(jié)果,并通過SDA80D51的GPIO口輸出識別結(jié)果對應(yīng)的詞條編碼信號。語音識別模塊主要由信號預(yù)處理、特征參數(shù)提取、模型匹配和Viterbi算法部分組成,非特定人語音識別模塊框圖如圖5所示。
2.1.1 信號預(yù)處理
信號預(yù)處理部分主要完成輸入語音信號的采樣、 模/數(shù)轉(zhuǎn)換功能。A/D變換由SDA80D51內(nèi)嵌12位A/D變換器實現(xiàn),采樣頻率固定為8 kHz。
2.1.2 特征參數(shù)提取
特征參數(shù)提取基于語音幀,采用分幀提取特片。先對語音信號進行重疊分幀,前一幀和后一幀重疊一半(幀信號重疊是體現(xiàn)相鄰兩幀數(shù)據(jù)之間的相關(guān)性),幀長為25 ms,對每幀提取一次語音特片。
語音信號是聲道響應(yīng)和聲門激勵信號的卷積。分別求聲道傳輸函數(shù)和聲門激勵信號的對數(shù)頻率響應(yīng),由于聲門激勵信號的頻率響應(yīng)和聲道傳輸函數(shù)在頻譜的變化快慢不同,如將頻率軸視為時間軸,則聲門激勵信號的頻率響應(yīng)對應(yīng)于“高頻”區(qū);而聲道傳輸函數(shù)對應(yīng)于“低頻”區(qū),處在不同區(qū)域就易于分辨。
MFCC參數(shù)屬于感知頻域倒譜參數(shù),反映了語音信號短時幅度譜的特征。p維MFCC參數(shù)的具體計算提取過程如下:
(1)用DFFT對每幀s(n:m)計算線性頻譜,計算頻譜模的平方為功率譜;
(2)功率譜經(jīng)過Mel濾波器組獲得D個參數(shù)X(i),D是Mel濾波器組中三角形濾波器的數(shù)量;
(3)對X(i)做對數(shù)運算和離散余弦變換,余弦變換計算公式如下:

式中的Y(i)是第i個Mel濾波器的對數(shù)能量輸出,i=1,2,…,D。
2.1.3 HMM語音識別算法
隱馬爾可夫采用概率統(tǒng)計模型描述語音信號,HMM模型建立在Markov鏈基礎(chǔ)上,使用Markov鏈來模擬語音信號統(tǒng)計特性的變化。HMM模型為雙重隨機過程,其一是Markov鏈,由(π,A)描述狀態(tài)的轉(zhuǎn)移,輸出為狀態(tài)序列;另一個是隨機過程,由B描述,在統(tǒng)計意義上B反映了狀態(tài)和觀察值之間的對應(yīng)關(guān)系,輸出為觀察值矢量序列。Markov鏈中狀態(tài)和時間參數(shù)都是離散的Markov過程。
Viterbi算法是一種幀同步動態(tài)規(guī)整算法,在給定觀察值序列和模型時,Viterbi算法給出了一個概率密度P(Q,O|λ)最大的狀態(tài)序列。Viterbi算法包括初始化、遞推、終止、路徑回溯和確定最佳狀態(tài)序列。

對于語音處理而言,因Q的變化,P(Q,O|λ)取值范圍很大,而P(Q,O|λ)的最大值占了全部P(Q,O|λ)的很大的成分,所以可以用Viterbi算法來計算P(O|λ)。
2.2 控制模塊
控制模塊的主要功能是:在AT89S51查詢到語音詞條信號后,查表獲得詞條編碼,根據(jù)編碼判斷對應(yīng)按鍵是長按或短按,分別進入相應(yīng)的子程序處理。在子程序中,輸出語音命令所對應(yīng)的I/O控制信號驅(qū)動繼電器吸合模擬按鍵或編碼開關(guān)動作,并及時復(fù)位I/O口。控制模塊還具有完全兼容手動控制的功能,在語音控制操作的同時也可以進行手動操作,手動的優(yōu)先級高于語音命令,這樣可以避免語音控制和手動控制之間發(fā)生沖突。
控制模塊部分程序代碼如下:

3 系統(tǒng)實測結(jié)果
本系統(tǒng)在江淮同悅SL1102C1型車載音響上進行了非特定人語音識別率和模擬開關(guān)動作準確率測試。由于汽車音響的語音詞條為2到4個字,語音識別率實驗內(nèi)容為車載音響常用2字詞條指令18條、3字詞條指令12條、4字詞條指令10條,實驗對象為6人(4男、2女,普通話和方言),實驗環(huán)境為實驗室環(huán)境。為了提高系統(tǒng)的識別率,系統(tǒng)采用奧林巴斯ME52定向麥克,提高了麥克接收范圍,系統(tǒng)測試結(jié)果如表1所示。

由表1可知,系統(tǒng)的識別率與語音指令詞條字數(shù)、麥克接收距離、說話人方言有關(guān)。男聲和女聲的識別率接近。
在系統(tǒng)控制電路實驗中,模擬開關(guān)動作達到了較高的準確率,測試結(jié)果為98%以上,只要控制程序運行正常,各路繼電器就能按照程序安排執(zhí)行閉合和斷開模擬手動開關(guān)操作。
實現(xiàn)汽車電器的語音控制是未來車載電器的發(fā)展趨勢,越來越多的解決方案被提出和驗證。本文設(shè)計在SL1102C1型車載音響上使用SDA80D51芯片,實現(xiàn)了車載音響非特定人的語音識別與控制。由于該芯片集成度高,需要外圍模塊少,所以設(shè)計的硬件電路簡單,便于調(diào)試檢測。該設(shè)計得到的樣機,有較高的識別率,工作穩(wěn)定、可擴展性強,達到預(yù)期的設(shè)計目標,整個設(shè)計方案和實現(xiàn)方法是可行的。由于語音識別率隨著環(huán)境、說話人不同而變化,雖然HMM算法在噪聲很小的環(huán)境下可以獲得很高的識別率,但當(dāng)測試語音或者環(huán)境中含有不同程度的噪聲污染時,語音識別系統(tǒng)的性能會有所下降。提高系統(tǒng)的抗噪性和魯棒性是語音識別系統(tǒng)走向?qū)嵱没年P(guān)鍵之一。
參考文獻
[1] 楊行峻,遲惠生.語音信號數(shù)字處理[M].北京:電子工業(yè)出版社,1995.
[2] Inifneon. UniSpeech2V2.0 Functional Specification [Z]. Infineon Technologies AG, 2002.
[3] 韓紀慶,張磊,鄭鐵然.語音信號處理[M].北京:清華大學(xué)出版社,2004.
[4] 王海青.基于CDHMM的口令式語音識別系統(tǒng)及其DSP實現(xiàn)[D]. 合肥:中國科學(xué)技術(shù)大學(xué),2003.
[5] BURCHARD B, ROMER R, FOX O. A single chip phoneme based HMM speech recognition system for consumer applications[J]. Consumer Electronics, IEEE Transactions on, 2000, 46(3): 914-919.
[6] Masao Namiki, Takayuki Hamamoto, Seiichiro Hangai.Spoken word recognition with digital cochlea using 32 DSP-boards, IEEE Trans. on Acoust, Speech, Signal Processing, 2001,2:969-972.