
摘 要: 在K-匿名模型的基礎(chǔ)上提出了(s,d)-個性化K-匿名隱私保護模型,該模型能很好地解決屬性泄漏問題,并通過實驗證明了該模型的可行性。
關(guān)鍵詞: K-匿名;隱私保護;個性化;屬性泄漏
隨著互聯(lián)網(wǎng)技術(shù)的飛速發(fā)展,基于網(wǎng)絡(luò)的虛擬社會逐步形成,信息的收集、加工、傳播更加快捷。現(xiàn)代社會是信息高度共享的社會,使得數(shù)據(jù)庫安全問題日益突出,其中對數(shù)據(jù)的竊取、篡改和破壞直接危害著數(shù)據(jù)庫的安全,成為亟待解決的問題。隨著數(shù)據(jù)挖掘技術(shù)的興起,大量的信息如:病人就診信息、學(xué)生學(xué)籍信息、員工工資及檔案信息等面臨著泄漏的風(fēng)險。對個人、企業(yè)甚至國家的危害是不容小覷的,個人信息的泄露容易造成詐騙的發(fā)生;企業(yè)和國家信息的泄露容易造成國家機密的暴露,直接危害國家安全。
自由保護型的數(shù)據(jù)庫隱私保護處理的隱私信息是對外公開的,所有人都可以使用,主要保護隱私信息和個人的對應(yīng)關(guān)系[1]。即攻擊者可以輕松獲取數(shù)據(jù)庫中的記錄,攻擊的目標(biāo)是某條隱私信息和某個體的一對一關(guān)系。典型的攻擊方法是鏈接攻擊(Linking Attack)[2]。
1 K-匿名技術(shù)
較好地解決鏈接攻擊的方法是參考文獻[2]中Samarati和Sweeney引入的K-匿名機制。它要求公布后的數(shù)據(jù)中存在一定數(shù)量的不可區(qū)分的個體,從而使攻擊者無法判斷出敏感屬性的具體個數(shù),以此達到保護個人隱私的目的。為了使數(shù)據(jù)表滿足K匿名性質(zhì),需要對原始表在準(zhǔn)標(biāo)識符上進行加工,如采用抑制或者泛化技術(shù)。
K-匿名技術(shù)通過生成若干等價組,使等價組內(nèi)QI屬性和隱私屬性不再是一一對應(yīng)的關(guān)系,從而保證了個人隱私信息不被泄露。等價組的概念為:在準(zhǔn)標(biāo)識符上的投影完全相同的、記錄組成的記錄集合,即等價組內(nèi)所有的記錄在準(zhǔn)標(biāo)識符上的屬性值完全相同,但是其他屬性可以不同。
定義1 K-匿名。給定數(shù)據(jù)表A(B1,B2,……Bn),QI是與A相關(guān)聯(lián)的準(zhǔn)標(biāo)識符,當(dāng)且僅當(dāng)在A[QI]中出現(xiàn)的每個值序列至少在A[QI]中出現(xiàn)K次,則A滿足K-匿名。A[QI]表示A表中的元組在QI上的投影[3]。
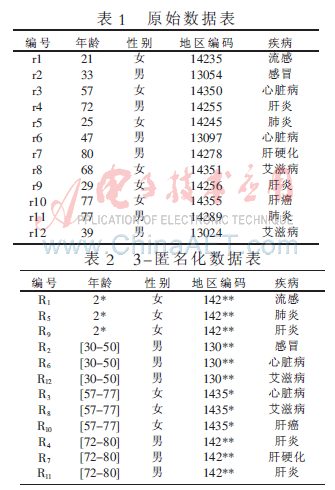
表1為原始數(shù)據(jù)表,其中年齡、性別、地區(qū)編碼為準(zhǔn)標(biāo)識符,疾病為敏感屬性,沒有任何可以唯一標(biāo)識個體身份的屬性存在,如身份證號碼、姓名等。經(jīng)過3-匿名化處理后如表2所示,每一條記錄都有另外兩條記錄在準(zhǔn)標(biāo)識符上與其相同。即使攻擊者知道某條記錄在表2中,也無法確定哪條記錄與其對應(yīng),但這樣并不能完全防止隱私泄露。因此參考文獻[3]提出了1-多樣性概念,即把等價組內(nèi)出現(xiàn)頻率最高的敏感屬性限制在1/1以內(nèi)。p-sensitive K-匿名模型[4]是在K-匿名模型的基礎(chǔ)上要求每個等價組內(nèi)至少要有p個不同的敏感屬性值,在一定程度上抵御了屬性泄漏問題,但是當(dāng)K值很大的時候就表現(xiàn)得不是很好。(a,k)-匿名模型[5]限制了等價組內(nèi)敏感屬性出現(xiàn)的頻率不高于a,在一定程度上防止了一致性攻擊,但是它對所有敏感屬性采用相同的約束,無法達到實用的目的。參考文獻[6]提出了一種不基于概括和隱匿的新方法——Anatomy,通過將原始關(guān)系的準(zhǔn)標(biāo)志符屬性和敏感屬性以兩個不同的關(guān)系發(fā)布,利用它們之間的有損連接保護隱私數(shù)據(jù)的安全。這些模型都沒有考慮敏感屬性敏感度問題,而且無法抵御背景知識攻擊。
2 (s,d)-個性化K-匿名隱私保護模型
K-匿名的主要缺陷:(1)K-匿名沒有考慮到匿名后可信屬性由于缺乏多樣性而導(dǎo)致的隱私泄露問題(同質(zhì)性攻擊);(2)默認(rèn)所有屬性都有相同的重要性;(3)不能抵御背景知識攻擊。
本文介紹的(s,d)-個性化K-匿名隱私保護模型就是為了解決這些問題而提出來的。在介紹(s,d)-個性化K-匿名隱私保護模型前需要給出的定義:s-相似等價組、臨界敏感度、高危敏感度、d-非關(guān)聯(lián)約束。
定義2 s-相似等價組。是指在敏感屬性值上相似的至少s個記錄組成的等價組,在這里相似的定義根據(jù)具體的應(yīng)用會有所不同。例如:如果敏感信息是疾病,則可以將病變器官作為相似劃分標(biāo)準(zhǔn),如胃部疾病,肝部疾病等。
定義3 臨界敏感度。由專家確定或者根據(jù)具體應(yīng)用領(lǐng)域靈活確定的、能夠較好體現(xiàn)對敏感屬性保護程度的一個數(shù)值度量,其值在0~1之間。
定義4 高危敏感度。高危敏感度是指敏感屬性值的敏感度大于、等于臨界敏感度,其值在0~1之間。
定義5 d-非關(guān)聯(lián)約束。對于s-相似等價組E,在E中高危敏感度屬性值出現(xiàn)的頻率f不高于d,即|f|/|E|<d(0≤d≤1),其中d是用戶確定的參數(shù)。但其必須滿足d不能等于1且不能過大,即不能太接近1。
定義6 (s,d)-個性化K-匿名隱私保護模型。如果一等價組由位于不同相似組的s-相似等價組組成,每個s-相似等價組都滿足d-非關(guān)聯(lián)約束,并且每個等價組至少由K條記錄組成,如果數(shù)據(jù)表T中的每個等價組都滿足以上條件,那么就稱數(shù)據(jù)表T滿足(s,d)-個性化K-匿名隱私保護模型。
(s,d)-個性化K-匿名隱私保護模型就是利用一個等價組中如果包含了多組s-相似等價組,并且每個s-相似等價組都滿足d-非關(guān)聯(lián)約束,就可以更加有效地抵御同質(zhì)性攻擊及屬性泄漏。另外如果每組相異值包含了多組相似值,可更加有效地抵御背景知識攻擊,從而大大降低隱私信息泄漏的風(fēng)險。本文闡述的(s,d)-個性化K-匿名隱私保護模型如表3所示。

根據(jù)病變器官這一相似性進行2-相似分組,可以看出該等價組滿足2-相似條件,從K=4的匿名表可以看出,由于敏感屬性疾病這一列都是高危敏感度屬性值,敏感度高達0.9,即使其滿足匿名條件,但是該等價組的隱私信息也已經(jīng)暴露出來了,攻擊者很容易得出該等價組對應(yīng)的個體患有很嚴(yán)重的疾病,也就造成了屬性泄漏。雖然從某種程度上來說還沒有造成身份泄露,但這也是人們所不希望的。
根據(jù)(s,d)-個性化K-匿名隱私保護模型的規(guī)定,調(diào)整如表4、表5所示。
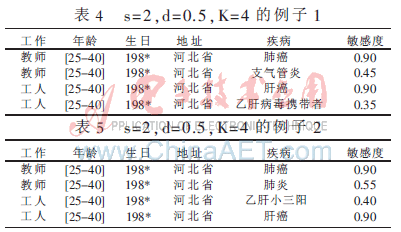
表4、表5中的每個等價組都滿足s=2,d=0.5(即sensitivity>0.70的敏感屬性值出現(xiàn)在每個2-相似等價組中的頻率≤0.5),K=4條件,但是可以較好地防止屬性泄漏問題。從敏感屬性敏感度的分布來看,經(jīng)過調(diào)整記錄得到的這兩個表其實就是減少了每個2-相似分組中高危屬性值的出現(xiàn)頻率。表4中將癌癥的出現(xiàn)頻率控制在了50%以內(nèi),表5中也將癌癥的出現(xiàn)頻率控制在了50%以內(nèi)。本文提出的(s,d)-個性化K-匿名隱私保護模型,在K-匿名模型基礎(chǔ)上做出了改進,有效地解決了由高危屬性值出現(xiàn)頻率過高而導(dǎo)致的屬性泄漏問題,同時能很好地抵御同質(zhì)性攻擊和背景知識攻擊。
3 (s,d)-個性化K-匿名隱私保護模型算法
輸入:數(shù)據(jù)表T,對敏感屬性的敏感度進行標(biāo)記s={S1,S2……Sn},敏感屬性按相似性分組g=(g1,g2,…,gn),準(zhǔn)標(biāo)識符各個屬性的權(quán)重W=(w1,w2,…,wn),參數(shù)為s,d,K。
輸出:滿足(s,d)-個性化K-匿名隱私保護模型的數(shù)據(jù)表Ta’。
處理過程:
(1)生成s-相似等價組,并且這些等價組滿足d-非關(guān)聯(lián)約束。
(2)對生成的s-相似等價組尋找使泛化信息損失最少的、K/s個不位于相同相似組內(nèi)的s-相似等價組:
Ta’={}
For(對于Ga中的每一個分組Ga’)
Gt={},在Ga’中取一條記錄
If(|Gt|!=K/s)
在Gt中找一分塊Gt’,使得Gt’中的記錄t’和t的敏感屬性值不屬于同一個敏感屬性組,并且dist(QI[t],QI[t’])最小 ,Gt=Gt∪Gt’, Ga= Ga/Gt。
End if Ta’= Ta’∪Gt
End for
(3)對生成的滿足(s,d)-個性化K-匿名隱私保護模型條件的各等價組進行泛化處理,即對Ta’中的每個分塊進行泛化處理。
4 實驗
實驗所使用的數(shù)據(jù)集來自UCI機器學(xué)習(xí)數(shù)據(jù)庫[7]中的adult數(shù)據(jù)庫,該數(shù)據(jù)庫在研究K-匿名應(yīng)用最多,已經(jīng)成為該領(lǐng)域事實上的標(biāo)準(zhǔn)測試集。數(shù)據(jù)庫大小為5.5 MB,本文選取其中的30 704條記錄及15個屬性,其中準(zhǔn)標(biāo)識符數(shù)量選擇6個,將職業(yè)(WORKCLASS)作為敏感屬性。敏感屬性泄漏分析如表6所示。

實驗軟硬件環(huán)境:
硬件環(huán)境:Intel Pentium(R) Dual-Core CPU,2GB RAM。
操作系統(tǒng):Microsoft Windows XP。
編程環(huán)境:Eclipse+Mysql Server 5.1。
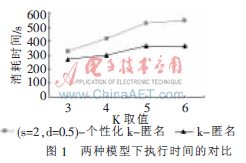
執(zhí)行時間分析如圖1所示。
本文針對K-匿名沒有考慮到匿名后可信屬性由于缺乏多樣性而導(dǎo)致的隱私泄露、默認(rèn)所有屬性都有相同的重要性、不能抵御背景知識攻擊等問題,提出了一種新的(s,d)-個性化K-匿名隱私保護模型。該模型通過s-相似分組,并且限制每個s-相似等價組內(nèi)的高危敏感屬性值出現(xiàn)的頻率小于d,然后組合不同相似分組內(nèi)的s-相似分組使其滿足K-匿名條件。實驗證明該模型能很好地彌補K-匿名的不足,有效地防止了隱私泄露。
參考文獻
[1] 劉喻,呂大鵬,馮建華,等.數(shù)據(jù)發(fā)布中的匿名化技術(shù)研究綜述[J].計算機應(yīng)用,2007,27(10):2361-2364.
[2] SWEENEY L. K-anonymity:a model for protecting privacy[J].International Journal on Uncertainty,F(xiàn)uzzi-ness and Knowledge-based Systems,2002,10(5):557-570.
[3] MACHANAVAJJHALA A, GEHRKE J, KIFER D, et al. L-diversity: Privacy beyond K-anonymity[C]// Proc of the 22 nd International Conference on Data Engineering New York: ACM Press, 2006.
[4] TRAIAN T M, BNDU V. Privacy protection: p-sensitive k-anonymity property[C]//.Proc of the 22 nd International Conference on Data Engineering New York: ACM Press,2006.
[5] WONG R C, Li Jinyong, FU A W, et al. (a,k)-anonymity: an enhanced k-anonymity model for privacy preserving[C]//. Proc of the 12 th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining New York: ACM Press, 2006.
[6] Xiao Xiaokui, Tao Yufei. Anatomy: simple and effective privacy preservation[C]//Proc of the 32 nd International Conference on Very Large Data Bases[SI]:VLDB Endowment, 2006:139-150.
[7] HETTICH C B S, MERZ C. UCI repository of machine learning databases[EB/OL]. (1996-05-01) [2008-04-20].http://archiveics uci edu/ml/datasets/Adult.