引言
由于現(xiàn)在的PCI、CPCI、VME等系統(tǒng)的持續(xù)傳輸速度很難超越400MB/s,因此要完成實(shí)時(shí)、長(zhǎng)時(shí)間的采集存儲(chǔ)功能,本設(shè)計(jì)選擇實(shí)現(xiàn)一種基于PCI-E的系統(tǒng),PCI-E是第三代接口通信協(xié)議(3GPIO)。傳統(tǒng)的PC主機(jī)北橋只有一個(gè)高速的PCI-E X16接口,本文使用帶G31北橋的芯片組的技嘉主板GA-G31M-ES2C為例來進(jìn)行討論,雖然G31-ICH7芯片組在南橋上可提供4個(gè)PCI-E ×1接口,但是由于其他I/O端口資源的占用,該主板在北橋上僅提供了一個(gè)PCI-E ×16的插槽,南橋也只提供一個(gè)PCI-E ×1插槽。因此如果只采用G31/ICH7芯片組的電腦建立一個(gè)PCI-E采集存儲(chǔ)系統(tǒng),它只能實(shí)現(xiàn)PCI-E 1.0 單通道的采集存儲(chǔ)系統(tǒng),帶寬就被限制在200MB/s內(nèi)。而這種格局主要是由于計(jì)算機(jī)北橋只提供一個(gè)PCI-E插槽,不能同時(shí)滿足高速采集和存儲(chǔ)的連接需要,因此擴(kuò)展主機(jī)北橋上的PCI-E接口,將整個(gè)采集存儲(chǔ)都建立在北橋上變得至關(guān)重要。
系統(tǒng)結(jié)構(gòu)分析
Intel(英特爾)公司最新的雙通道DDR3內(nèi)存以及下一代雙×16 PCI-E 2.0的計(jì)算機(jī)芯片組技術(shù)提供了一種更新的個(gè)人電腦的架構(gòu),這些技術(shù)被應(yīng)用到X38、X48和X58等計(jì)算機(jī)芯片組中。本文以X58為例,圖1為X58芯片組的系統(tǒng)架構(gòu)。

圖1 X58芯片組的系統(tǒng)架構(gòu)
X58芯片組搭配新南橋ICH10或ICH10R,可支持四條PCI-E ×16插槽(其中兩條符合PCI-E 2.0規(guī)范),根據(jù)通道數(shù)的要求可組成四種不同模式,當(dāng)然它只支持雙圖形處理器(GPU)協(xié)同運(yùn)行的技術(shù)CrossFire,仍不支持Scalable Link Interface(SLI)技術(shù)。SLI技術(shù)是主板能夠同時(shí)使用兩塊同型號(hào)PCI-E顯卡的一種技術(shù),同時(shí)芯片間通信通過類似AMD HyperTransport總線技術(shù)的QPI總線技術(shù)完成,借助PCI-E通道可帶來最高25.6GB/s的雙向帶寬,而現(xiàn)在的前端總線Front Side Bus(FSB)則被徹底棄用。我們可以直接運(yùn)用X58芯片組構(gòu)建一個(gè)高速實(shí)時(shí)的系統(tǒng),但由于現(xiàn)階段很少有能夠完全利用PCI-E ×16帶寬的采集卡,因此將資源進(jìn)行分割,利用多塊采集模塊組成一個(gè)采集系統(tǒng),通過PCI-E Switch擴(kuò)展接口的方法可以將X58芯片組擴(kuò)展成為一個(gè)更高速、兼容更多模塊的采集存儲(chǔ)系統(tǒng)。
DMI(Direct Media Interface)直接媒體接口是Intel公司開發(fā)用于連接主板南北橋的總線,取代了以前的Hub-Link總線。DMI采用點(diǎn)對(duì)點(diǎn)的連接方式,時(shí)鐘頻率為100MHz,由于它基于PCI-E總線,因此具有PCI-E總線的優(yōu)勢(shì)。DMI實(shí)現(xiàn)了上行與下行各1GB/s的數(shù)據(jù)傳輸率,總帶寬達(dá)到2GB/s,但DMI還要與其他I/O設(shè)備進(jìn)行通信,因此如果選擇南橋的PCI-E端口進(jìn)行傳輸,傳輸速度將受到很大的限制,理想情況下至多只能實(shí)現(xiàn)1GB/s的傳輸存儲(chǔ)速度。因此,本系統(tǒng)在計(jì)算機(jī)中DMI以上的結(jié)構(gòu)中完成數(shù)據(jù)的傳輸和存儲(chǔ)。我們可以將連接在芯片G31 GMCH的PCI-E ×16端口通過一個(gè)PCI-E Switch進(jìn)行擴(kuò)展,擴(kuò)展后的結(jié)構(gòu)相當(dāng)于主機(jī)北橋提供了多個(gè)高速的PCI-E接口,形成一個(gè)類似于圖1中的X58架構(gòu),從而使整個(gè)傳輸存儲(chǔ)過程不受DMI雙向2GB/s速度的影響。
利用北橋PCI-E擴(kuò)展技術(shù),將所有的采集卡和存儲(chǔ)卡都連接到主機(jī)的北橋端,可使整個(gè)數(shù)據(jù)傳輸不受主機(jī)DMI等的速度瓶頸限制,如果只是使用PCI-E ×4對(duì)系統(tǒng)進(jìn)行擴(kuò)展,理想的有效數(shù)據(jù)傳輸速度也可達(dá)800MB/s,而且由于PCI-E協(xié)議是雙向同時(shí)傳輸?shù)模虼藢⒉杉ê痛鎯?chǔ)卡同時(shí)連接到一個(gè)端口并不會(huì)影響其傳輸和存儲(chǔ)的效率。
系統(tǒng)設(shè)計(jì)
PCI-E Switch
PCI-E Switch為整個(gè)系統(tǒng)提供擴(kuò)展端口,系統(tǒng)中所有的PCI-E接口都是通過PCI-E Switch芯片擴(kuò)展出來的,類似的可以看成將多個(gè)PCI-E插槽直接連接到主機(jī)的北橋上。圖2為含PCI-E的拓?fù)浣Y(jié)構(gòu)圖,通過Switch可以將一個(gè)上游設(shè)備口擴(kuò)展多個(gè)下游端口,此外PCI-E Switch還可以級(jí)聯(lián)。通過一個(gè)多通道的PCI-E Switch可擴(kuò)展構(gòu)建一個(gè)多采集卡多存儲(chǔ)設(shè)備的實(shí)時(shí)高速采集存儲(chǔ)系統(tǒng)。

圖2 含PCI-E Switch的拓?fù)浣Y(jié)構(gòu)圖
本方案采用的是PLX公司的一塊PCI-E Switch芯片PEX8616,它是一款可以設(shè)置4個(gè)接口并擁有16個(gè)通道的PCI-E Switch芯片,并可設(shè)置每個(gè)接口的通道數(shù)。其支持透明橋(TB)、非透明橋(NTB)兩種方式,即可以支持兩個(gè)及以上的多主機(jī)系統(tǒng)和多智能I/O端口的模塊。PEX8616每個(gè)通道含有兩個(gè)虛擬端口,且支持熱插拔。由于主要目的是將北橋上的PCI-E ×16插槽擴(kuò)展成為多個(gè)PCI-E接口。因此,本系統(tǒng)中將其分為四個(gè)PCI-E ×4的接口。端口號(hào)為0、1、5和6,將與主機(jī)連接的端口0設(shè)置為上游端口,其余三個(gè)端口則為下游端口,連接采集卡和RAID存儲(chǔ)卡。
PCI-E數(shù)據(jù)傳輸方式包含地址路由和ID路由等方式,PCI-E設(shè)備在系統(tǒng)中都有一個(gè)ID,根據(jù)所處的PCI總線號(hào)、設(shè)備號(hào)和功能號(hào)來確定。一個(gè)PCI-E Switch可以看成多個(gè)P2P橋的集合,并且在上游設(shè)備和下游設(shè)備之前還虛擬了一條總線。
系統(tǒng)與橋
透明橋系統(tǒng)是指整個(gè)系統(tǒng)中只含一個(gè)主機(jī)設(shè)備,其余所有設(shè)備都是以端點(diǎn)設(shè)備的形式出現(xiàn)。所有下游設(shè)備不能自發(fā)進(jìn)行數(shù)據(jù)傳輸,只有在上位機(jī)引導(dǎo)下進(jìn)行數(shù)據(jù)傳輸。采集卡可以通過DMA等方式將數(shù)據(jù)傳輸?shù)缴衔粰C(jī)的內(nèi)存中的某個(gè)區(qū)域,然后再將內(nèi)存中的數(shù)據(jù)存儲(chǔ)到磁盤陣列中。由于存儲(chǔ)和讀取同一塊內(nèi)存,因此在軟件上可以多開辟幾塊內(nèi)存,利用多線程規(guī)避系統(tǒng)順序執(zhí)行所帶來的延遲,提高傳輸和存儲(chǔ)的速度。
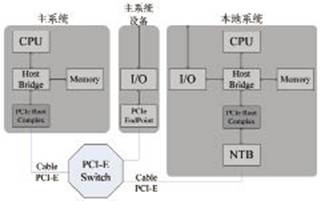
圖3 基于PCI-E Switch的非透明橋系統(tǒng)
PEX8616提供非透明橋,非透明端口保持處理器的電氣及邏輯隔離,可以防止主機(jī)列舉端口后面的設(shè)備,從而隔離其后的處理器及內(nèi)存空間。非透明端口允許打開窗口以交換數(shù)據(jù),通過地址轉(zhuǎn)換,數(shù)據(jù)從端口的一側(cè)中傳輸另外一側(cè)。每個(gè)處理器把非透明端口的另一端當(dāng)作一個(gè)下游設(shè)備,并把它映射到自己的地址空間。利用非透明端口的地址翻譯能力,處理器之間可以通過PCI-E總線進(jìn)行通信。因此系統(tǒng)構(gòu)建可以考慮引入非透明橋,在上位機(jī)存在的情況下,讓采集卡或者存儲(chǔ)卡也作為一個(gè)主機(jī)端,數(shù)據(jù)在采集存儲(chǔ)過程中可以直接繞開PC主機(jī)進(jìn)行,當(dāng)數(shù)據(jù)進(jìn)行反演時(shí),上位機(jī)再作為上游,對(duì)磁盤陣列進(jìn)行操作和控制。
圖3為一種非透明橋的系統(tǒng),其中包含兩個(gè)Host Bridge和PCI-E Root Complex,其中本地設(shè)備系統(tǒng)中的Root Complex連接到PCI-E Switch的一個(gè)NT端口上,從而在主系統(tǒng)的PCI結(jié)構(gòu)中把它作為一個(gè)下游設(shè)備。PCI-E Switch連接兩個(gè)獨(dú)立的處理器域,本地設(shè)備的資源和地址對(duì)主系統(tǒng)是不可見的。允許本地處理器獨(dú)立地配置和控制其子系統(tǒng)。主系統(tǒng)和本地系統(tǒng)的時(shí)鐘完全獨(dú)立。主系統(tǒng)和本地系統(tǒng)的地址完全獨(dú)立,在主系統(tǒng)和本地系統(tǒng)之間可以進(jìn)行地址翻譯。增加了隔離主系統(tǒng)、本地系統(tǒng)總線之間地址域的功能。
在構(gòu)建采集存儲(chǔ)系統(tǒng)的過程中可以將采集模塊或者存儲(chǔ)模塊以構(gòu)建本地系統(tǒng)的方式實(shí)現(xiàn),從而可以在采集數(shù)據(jù)后直接對(duì)數(shù)據(jù)進(jìn)行預(yù)處理然后再送到PCI-E總線進(jìn)行存儲(chǔ)或者可以在存儲(chǔ)之后直接在本地系統(tǒng)進(jìn)行回放或者提供網(wǎng)口訪問存儲(chǔ)數(shù)據(jù)等功能。
采集存儲(chǔ)系統(tǒng)的實(shí)現(xiàn)
系統(tǒng)結(jié)構(gòu)
系統(tǒng)由PC主機(jī)、PCI-E Switch背板、采集卡和RAID存儲(chǔ)卡組成。在完成背板設(shè)計(jì)后,先利用一塊PEX8311接口芯片的采集卡,Rocket RAID 2680磁盤陣列卡,實(shí)現(xiàn)一種高速采集存儲(chǔ)的系統(tǒng)。然而因?yàn)槠胀ǖ腜C機(jī)箱的空間有限,如果將PCI-E Switch背板與上位機(jī)的接口直接以PCI-E金手指的形式,則當(dāng)背板接入主機(jī)后,很難創(chuàng)造一個(gè)空間可以容納其他板卡插到背板上。并且由于磁盤陣列是由多個(gè)Western Digest WD3200AAJS的硬盤構(gòu)成,發(fā)熱量也成為一個(gè)很顯著的問題。
因此本方案考慮通過引入Cable PCI-E來改善系統(tǒng)。Cable PCI-E是基于PCI-E用于服務(wù)器、臺(tái)式機(jī)和筆記本的下一代外圍總線,它具有以下的優(yōu)點(diǎn):
• 成本較低,由于PCI-E廣泛用于各種主機(jī);
• 高帶寬,Gen1 ×4 Cable的帶寬即達(dá)到1GB/s;
• 低延遲,300ns~700ns;
• 兼容性強(qiáng),系統(tǒng)軟件上完全兼容PCI模式;
• Cable PCI-E至少由15種標(biāo)準(zhǔn)形成;
• 唯一可以同時(shí)應(yīng)用于Chip-to-Chip、board-to-board和box-to-box的標(biāo)準(zhǔn)。
PCI-SIG標(biāo)準(zhǔn)組織將Cable PCI-E定義為一種基于PCI-E的基本規(guī)范的擴(kuò)展,通過線纜化將PCI-E協(xié)議擴(kuò)展到box-to-box應(yīng)用和實(shí)現(xiàn)長(zhǎng)距離的傳輸是產(chǎn)生Cable PCI-E標(biāo)準(zhǔn)的目的。Cable PCI-E提供一種簡(jiǎn)單而且具有高性能的總線,方便擴(kuò)展PC以及測(cè)試I/O等設(shè)備。本方案就是利用Cable PCI-E方便擴(kuò)展設(shè)備的特點(diǎn),將整個(gè)采集存儲(chǔ)系統(tǒng)完全分離到PC機(jī)箱外,最終可以獨(dú)立構(gòu)建成一個(gè)機(jī)箱形成一種box-to-box的模式,使得整個(gè)系統(tǒng)的可擴(kuò)展性很強(qiáng),PCI-E ×4及其以下的COST采集板卡和存儲(chǔ)卡均可以很好的應(yīng)用于本系統(tǒng)中。獨(dú)立的機(jī)箱也為磁盤陣列中的硬盤提供足夠的空間,系統(tǒng)的散熱也能得到很好的保障。
系統(tǒng)的結(jié)構(gòu)圖如圖4所示,整個(gè)系統(tǒng)圍繞PCI-E Switch構(gòu)建而成,通過兩個(gè)Cable PCI-E將系統(tǒng)的各個(gè)模塊獨(dú)立開來。由于采集卡采用的為PEX8311,故采集卡與PCI-E Switch連接的通道數(shù)為1,在后續(xù)的研究中可以升級(jí)采集的采集和接口速度從而實(shí)現(xiàn)整個(gè)系統(tǒng)的升級(jí)。磁盤陣列卡是一款消費(fèi)類產(chǎn)品,Rocket RAID 2680不能提供HOST功能,因此本案構(gòu)建的是一個(gè)透明橋系統(tǒng)。
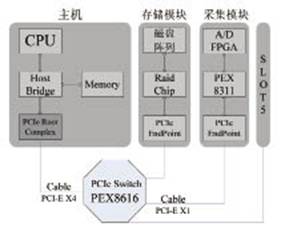
圖4 PCI-E Switch采集存儲(chǔ)系統(tǒng)結(jié)構(gòu)圖
數(shù)據(jù)的采集、傳輸和存儲(chǔ)
數(shù)據(jù)采集
采集板AD采用TI ADS6145芯片,采樣位數(shù)為14bit,最高采樣頻率為125Mbps。AD采集后的數(shù)據(jù)接入到Xilinx公司Spartan-3ADSP系列的FPGA芯片XC3SD3400A。因?yàn)镻EX8311接口芯片可支持8位、16位、32位數(shù)據(jù)的傳輸,為了提高數(shù)據(jù)傳輸?shù)男剩瑫r(shí)也為了使得數(shù)據(jù)采集速率獲得相對(duì)提升。本設(shè)計(jì)中PEX8311中采用32位數(shù)據(jù)傳輸。所以在本方案FPGA數(shù)據(jù)流邏輯控制中,不僅要完成數(shù)據(jù)的緩存以及數(shù)據(jù)傳輸邏輯的控制,還要進(jìn)行數(shù)據(jù)位的變換擴(kuò)展,由14位數(shù)據(jù)擴(kuò)展為32位數(shù)據(jù)。
數(shù)據(jù)傳輸和存儲(chǔ)
數(shù)據(jù)傳輸是指的從PEX8311到主機(jī)內(nèi)存的過程。本方案選擇DMA方式進(jìn)行,由于PEX8311內(nèi)建兩個(gè)DMA通道。本方案使用其中的一個(gè),DMA通道0。在安裝PLX提供的SDK以及驅(qū)動(dòng)后,可以通過其提供的API開發(fā)包中的函數(shù)對(duì)PEX8311和PEX8616進(jìn)行控制和訪問。一般的DMA傳輸過程是無需CPU的參與的,但是含Burst的DMA操作還是要通過CPU的參與的,與單獨(dú)的一次讀寫操作相比,Burst只需要提供一個(gè)起始地址就行了,以后的地址依次加1,而非Burst操作每次都要給出地址,以及需要中間的一些應(yīng)答、等待狀態(tài)等等。如果是對(duì)地址連續(xù)的讀取,Burst效率高得多,但如果地址是跳躍的,則無法采用Burst操作。PEX8311的DMA傳輸支持Single Burst 、Burst-4LW和Infinite Burst三種突發(fā)方式,表1為三種突發(fā)方式在不同單次傳輸字節(jié)數(shù)的情況下的傳輸速度對(duì)比。
表1 DMA傳輸在三種突發(fā)方式下的速度對(duì)比(MB/s)
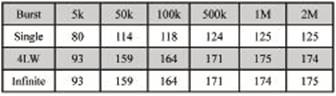
由表1數(shù)據(jù)可觀察出,采用后兩種突發(fā)方式進(jìn)行DMA傳輸時(shí),速度較普通DMA傳輸方式有明顯的提高,因此本方案采用Infinite Burst突發(fā)方式進(jìn)行DMA傳輸,使用連續(xù)的地址,以提高DMA傳輸?shù)乃俣取?br />
PLX公司SDK中提供的函數(shù)可對(duì)PEX8311和PEX8616進(jìn)行一系列控制和操作,DMA通道的參數(shù)設(shè)置在打開DMA通道的時(shí)候一并完成,通過設(shè)置函數(shù)PlxPci_DeviceOpen()中的PLX_DMA_PROP結(jié)構(gòu)體可以設(shè)置DMA傳輸?shù)耐话l(fā)方式、本地總線帶寬和傳輸方向等參數(shù)。在系統(tǒng)初始化過程中設(shè)置以上參數(shù)。當(dāng)整個(gè)采集存儲(chǔ)過程完成時(shí),則需要進(jìn)行對(duì)整個(gè)工程的關(guān)閉工作,同樣是通過SDK中的函數(shù)PlxPci_DeviceClose()來關(guān)閉DMA通道。然后釋放開辟的所有內(nèi)存塊空間,并將指針賦NULL值。系統(tǒng)連續(xù)存儲(chǔ)的整個(gè)過程從開始到結(jié)束,雖然進(jìn)行了很多個(gè)DMA傳輸?shù)牟僮鳎侵贿M(jìn)行了一次DMA通道的打開和關(guān)閉,從而盡可能低的減小由于這部分時(shí)間帶來的速度影響。軟件流程如圖5所示。
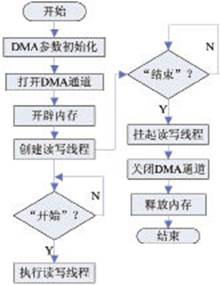
圖5 采集存儲(chǔ)系統(tǒng)軟件流程圖
根據(jù)圖5可以觀察到系統(tǒng)引入了多線程技術(shù),多線程技術(shù)的實(shí)現(xiàn)是通過分別創(chuàng)建兩個(gè)函數(shù),一個(gè)控制DMA控制器進(jìn)行連續(xù)的數(shù)據(jù)傳輸,另一個(gè)用于將內(nèi)存中的數(shù)據(jù)快速的存儲(chǔ)到磁盤陣列中,然后創(chuàng)建成為兩個(gè)線程。當(dāng)準(zhǔn)備開始進(jìn)行數(shù)據(jù)傳輸?shù)臅r(shí)候,首先是設(shè)置DMA傳輸?shù)膮?shù)并打開DMA通道。在此過程中還需要申請(qǐng)多塊內(nèi)存空間進(jìn)行緩存數(shù)據(jù),由于使用多線程技術(shù),因此一塊內(nèi)存空間不能同時(shí)供兩個(gè)函數(shù)同時(shí)讀寫,因此創(chuàng)建多個(gè)內(nèi)存塊,然后將兩個(gè)線程同時(shí)打開,對(duì)開辟的多個(gè)內(nèi)存塊依次進(jìn)行讀寫操作,但是由于整個(gè)過程只包含一個(gè)極短的時(shí)間延遲,因此完全可以將整個(gè)讀寫內(nèi)存的過程近似的看成一個(gè)同時(shí)進(jìn)行讀寫操作,因此達(dá)到提高存儲(chǔ)的速度的目的。
傳輸速度分析
RAID 0又稱為Stripe或Striping,它代表了所有RAID級(jí)別中最高的存儲(chǔ)性能。RAID 0提高存儲(chǔ)性能的原理是把連續(xù)的數(shù)據(jù)分散到多個(gè)磁盤上存取,這樣,系統(tǒng)有數(shù)據(jù)請(qǐng)求就可以被多個(gè)磁盤并行的執(zhí)行,每個(gè)磁盤執(zhí)行屬于它自己的那部分?jǐn)?shù)據(jù)請(qǐng)求。這種數(shù)據(jù)上的并行操作可以充分利用總線的帶寬,顯著提高磁盤整體存取性能。
表2 RAID0方式下讀寫陣列速度比較(MB/s)
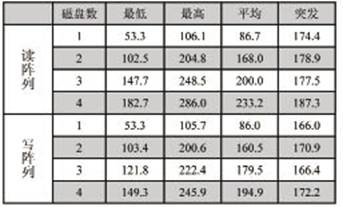
該系統(tǒng)在實(shí)際的采集存儲(chǔ)過程中,連續(xù)存儲(chǔ)的速度在135MB/s,因此用兩塊或者三塊磁盤組成的RAID 0陣列就能完全滿足設(shè)計(jì)要求。因?yàn)榇鎯?chǔ)的速度仍明顯高于采集卡DMA傳輸?shù)乃俣龋铱梢酝ㄟ^擴(kuò)展RAID卡上的硬盤數(shù)進(jìn)一步增加磁盤陣列存儲(chǔ)速度。表2的實(shí)驗(yàn)數(shù)據(jù)使用四個(gè)Western Digest WD3200AAJS硬盤,因?yàn)槭褂猛瑯哟笮』蛘咭?guī)格的硬盤能夠更好的使用所用的磁盤空間。由表中的數(shù)據(jù)可以看出,隨著磁盤數(shù)目的增加,其存儲(chǔ)的各項(xiàng)指標(biāo)均有明顯的提高,該磁盤陣列卡Rocket RAID 2680最多可提供8塊SATA硬盤,隨著采集卡采集傳輸?shù)乃俣鹊奶嵘梢杂酶嗟拇疟P組建磁盤陣列,來匹配前端采集卡的帶寬,所以整個(gè)系統(tǒng)只需更換一個(gè)更高速的PCI-E采集卡就可以實(shí)現(xiàn)更高存儲(chǔ)速度的高速采集存儲(chǔ)系統(tǒng)。

圖6 高速采集存儲(chǔ)系統(tǒng)照片
結(jié)論
設(shè)計(jì)一個(gè)基于PC主機(jī)北橋的長(zhǎng)時(shí)間不間斷高速采集和存儲(chǔ)的系統(tǒng)。利用PC北橋PCI-E擴(kuò)展技術(shù),將采集卡和存儲(chǔ)都連接到計(jì)算機(jī)北橋,此法可以用于后續(xù)通道進(jìn)一步擴(kuò)大的應(yīng)用中。本文最后介紹了利用PC主機(jī)、PCI-E接口芯片PEX8311、Switch芯片PEX8616和RAID磁盤陣列卡,構(gòu)建一個(gè)PCI-E架構(gòu)的實(shí)時(shí)海量存儲(chǔ)系統(tǒng)的案例。數(shù)據(jù)通過PC機(jī)的北橋芯片,實(shí)現(xiàn)采集卡到磁盤陣列存儲(chǔ)卡的數(shù)據(jù)高速傳輸。雖然在采集卡采用PCI-E X1的情況下并不能完全體現(xiàn)將整個(gè)系統(tǒng)都集中在主機(jī)北橋的優(yōu)勢(shì),但是它將會(huì)在更進(jìn)一步的設(shè)計(jì)和研究中體現(xiàn)出來。
