
引言
信息時代的日新月異,催促著各種各樣的數(shù)據(jù)信息快馬加鞭,人們在要求信息傳輸?shù)迷絹碓娇斓耐瑫r,還要求信息要來得更加及時,于是高速實時的數(shù)據(jù)傳輸就成為了電子信息領(lǐng)域里一個永遠不會過時的主題。但是,可以清楚地看到,當今動輒成百上千兆的數(shù)據(jù)流一股腦的涌入,任何一個高速數(shù)據(jù)傳輸系統(tǒng)的穩(wěn)定性和安全性等方方面面的問題都面臨著極大的挑戰(zhàn),稍有考慮不周之處就會引起各種各樣的問題,因此如何能安全高效的對高速數(shù)據(jù)進行實時接收、存儲、處理和發(fā)送正是此次設(shè)計方案的目的。
2.設(shè)計方案的硬件選定
鑒于當前高速數(shù)據(jù)傳輸系統(tǒng)的設(shè)計方案大多是現(xiàn)場可編程門陣列(FPGA)加片外存儲介質(zhì)( SDRAM、SRAM、DDR等)的組合,于是本次設(shè)計方案同樣采用這種組合方式,具體為一片 FPGA、三片靜態(tài)存儲器( sram)和一片高速數(shù)據(jù)傳輸芯片。 FPGA具有管腳多、內(nèi)部邏輯資源豐富、足夠的可用 IP核等優(yōu)點,用作整個高速數(shù)據(jù)傳輸系統(tǒng)的控制模塊極為合適,此次方案中選用 Altera公司的高性價比 Cyclone[2]系列 FPGA;靜態(tài)存儲器具有昀大的優(yōu)點就是數(shù)據(jù)讀取速度快,且控制信號簡單易操作,昀適用于高速數(shù)據(jù)存儲介質(zhì),方案選用 ISSI公司的 IS61LV51216型號的靜態(tài)存儲器 [3],其處理速度和存儲容量滿足系統(tǒng)設(shè)計的需要;TI公司的 TLK1501[4]是此次設(shè)計選用的高速數(shù)據(jù)傳輸芯片,其傳輸能力十分強大,不僅能滿足當前設(shè)計的傳輸速度需要,還留有充分的帶寬余量,為以后的系統(tǒng)改進提供了條件。上述三種芯片是此次高速數(shù)據(jù)傳輸系統(tǒng)所要用到的主要組成部件,其具體連接方式等問題不作討論。
3.具體設(shè)計方案
實現(xiàn)整個數(shù)據(jù)流從接收、存儲、轉(zhuǎn)換直到發(fā)送的過程由圖一可以看出,在接收端經(jīng)由 DVI[1]解碼芯片傳輸?shù)慕獯a數(shù)據(jù)包含 24bit并行像素數(shù)據(jù)和三個同步信號——像素時鐘 Pclk、數(shù)據(jù)使能信號 DE以及場同步信號 Vsy,fpga內(nèi)部的寫緩沖區(qū)控制器則會根據(jù)以上三個數(shù)據(jù)同步信號生成寫緩沖區(qū)的寫入地址,控制 24bit的像素數(shù)據(jù)信號存入寫緩沖區(qū)中,并會在一段時間后向內(nèi)存控制器發(fā)送讀請求( wcache_rreq)以讀出寫緩沖區(qū)內(nèi)的已寫入數(shù)據(jù),寫緩沖區(qū)是由 fpga自帶的 M4K塊配置生成的雙端口 RAM結(jié)構(gòu)[2],采用乒乓操作,這樣整個內(nèi)存讀取和緩沖區(qū)寫入過程是各自獨立進行的,保證所寫入數(shù)據(jù)的完整性,內(nèi)存控制器在接收寫緩沖區(qū)控制器發(fā)送的讀請求后,按照相應(yīng)的寫緩沖區(qū)地址讀取數(shù)據(jù),并將其寫入片外靜態(tài)存儲器中,以上為像素數(shù)據(jù)的接收和存儲過程;在發(fā)送端,幀同步產(chǎn)生及高速數(shù)據(jù)傳輸控制器通過 fpga自帶的鎖相環(huán)產(chǎn)生數(shù)據(jù)時鐘 Dclk、幀同步 Fsy等信號,使讀緩沖區(qū)控制器產(chǎn)生對讀緩沖區(qū)的讀取地址,讀緩沖區(qū)控制器在產(chǎn)生讀地址的同時,還會在一段時間間隔后向內(nèi)存控制器發(fā)送寫請求( rcache_wreq)以向被讀過的讀緩沖區(qū)部分寫入新數(shù)據(jù),同樣讀緩沖區(qū)也是雙端口 RAM結(jié)構(gòu),采用乒乓操作,保證被發(fā)送數(shù)據(jù)的連續(xù)完整,被讀出的 24bit數(shù)據(jù)經(jīng)過一個 24bit/16bit數(shù)據(jù)轉(zhuǎn)換器轉(zhuǎn)換為 16bit并行數(shù)據(jù)之后才能輸出給高速數(shù)據(jù)傳輸芯片,而內(nèi)存控制器在接收讀緩沖區(qū)控制器的寫請求后在片外靜態(tài)存儲器中讀出相應(yīng)地址的數(shù)據(jù)寫入讀緩沖區(qū)中,這樣整個數(shù)據(jù)的接收、存儲、轉(zhuǎn)換到發(fā)送的過程得以實現(xiàn)。
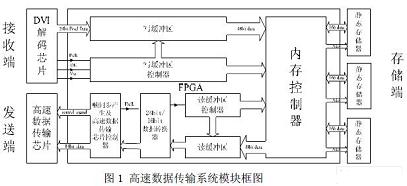
3.1 寫緩沖區(qū)控制器的設(shè)計
由 DVI[1]解碼芯片輸入給 fpga的像素時鐘信號 Pclk、數(shù)據(jù)使能信號 DE以及場同步信號 Vsy表示 24bit并行像素數(shù)據(jù)的同步信息。例如: 1024×512顯示分辨率的圖像,則在每兩個場同步信號 Vsy脈沖之間有 512個“DE=1”的數(shù)據(jù)有效信號,而在每個“ DE="1"”的數(shù)據(jù)有效信號中有 1024個 Pclk像素時鐘信號,如此可將輸送的像素數(shù)據(jù)同步。
寫緩沖區(qū)控制器直接接收輸入的 DVI數(shù)據(jù)同步信號,在每個 Vsy脈沖來時將寫緩沖區(qū)寫入地址清零,然后在“DE=1”時寫緩沖區(qū)控制器內(nèi)的地址計數(shù)器計數(shù)有效,在每個 Pclk上升沿進行計數(shù)加 1操作,這樣在每個 DE有效時會產(chǎn)生一行的像素數(shù)據(jù)地址,再到下一個DE有效時地址計數(shù)器又會重新計數(shù),如此循環(huán),而寫緩沖區(qū)會按照對應(yīng)的地址將輸入的 24bit并行像素數(shù)據(jù)同步寫入緩沖區(qū)內(nèi)。寫緩沖區(qū)控制器會在地址計數(shù)器計數(shù)到半行數(shù)據(jù)地址的時候,向內(nèi)存控制器發(fā)送寫緩沖區(qū)讀請求信號( wcache_rreq)和相應(yīng)緩沖區(qū)地址,要求內(nèi)存控制器對已寫入的半行像素數(shù)據(jù)以 48bit并行數(shù)據(jù)格式進行讀取,由于內(nèi)存控制器的等效操作時鐘遠遠高于寫緩沖區(qū)的寫入時鐘,因此內(nèi)存控制器會迅速的將已寫入的半行數(shù)據(jù)讀出并停止讀數(shù),等待下一個 wcache_rreq的到來,如此便形成了對寫緩沖區(qū)的乒乓操作,保證了輸入像素數(shù)據(jù)的正確和連續(xù)接收,避免產(chǎn)生像素數(shù)據(jù)漏接和不同步的現(xiàn)象。讀緩沖區(qū)控制器的設(shè)計思路同上,不再贅述。
3.2 內(nèi)存控制器的設(shè)計 [5] [6]
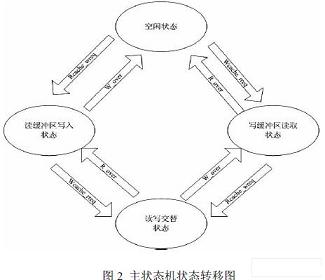
內(nèi)存控制器里包含主狀態(tài)機和內(nèi)存控制模塊,如圖二所示,主狀態(tài)機負責對兩個緩沖區(qū)和片外靜態(tài)存儲器的讀寫狀態(tài)控制,共有四個狀態(tài)——空閑狀態(tài)、寫緩沖區(qū)讀取狀態(tài)、讀緩沖區(qū)寫入狀態(tài)和讀寫交替狀態(tài),用于控制狀態(tài)機狀態(tài)轉(zhuǎn)移的信號包括:寫緩沖區(qū)讀請求信號(wcache_rreq)、寫緩沖區(qū)讀取完成信號( r_over)、讀緩沖區(qū)寫請求信號( rcache_wreq)以及讀緩沖區(qū)寫入完成信號 (w_req)。狀態(tài)機在沒有任何操作請求下處于空閑狀態(tài),而當其接收到“wcache_rreq”信號時,狀態(tài)就會隨之變?yōu)閷懢彌_區(qū)讀取狀態(tài)并進行相應(yīng)操作,而當讀取操作完成后會有“ r_over”信號傳入狀態(tài)機,狀態(tài)機又會轉(zhuǎn)入空閑狀態(tài)等待下一信號進入,而當狀態(tài)機處于寫緩沖區(qū)讀取狀態(tài)時接收到了“ rcache_wreq”信號,則狀態(tài)機轉(zhuǎn)入讀寫交替狀態(tài),此時會對寫緩沖區(qū)和讀緩沖區(qū)進行交替操作,一旦有一個緩沖區(qū)操作完成時會輸入相應(yīng)的操作完成信號,此時狀態(tài)機即轉(zhuǎn)入對另一緩沖區(qū)的單獨操作直至操作完成再次進入空閑狀態(tài)。整個狀態(tài)轉(zhuǎn)移過程保證了對讀寫緩沖區(qū)操作請求的及時響應(yīng),杜絕了由于狀態(tài)沖突導致的漏操作現(xiàn)象。
系統(tǒng)選用的片外靜態(tài)存儲器的地址總線為 19 位,數(shù)據(jù)總線為16 位,經(jīng)公式(1)計算 可知采用三片內(nèi)存的總?cè)萘空每梢源鎯蓤?024×512 顯示分辨率的圖像,這樣可以對存 儲器進行乒乓操作,在存儲器內(nèi)寫入一場數(shù)據(jù),讀取另一場數(shù)據(jù),兩者交替獨立進行。
![]()
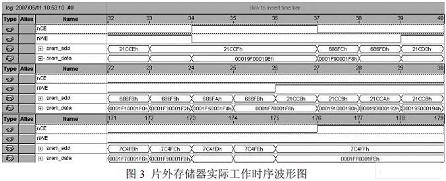
內(nèi)存控制模塊負責對片外存儲器進行控制,其控制信號是兩個低電平有效信號[3]:nWE 和nCS。nCS 為片選信號,當為高電平時存儲器處于非工作狀態(tài),此時不能對存儲器進行任 何操作,低電平時為正常工作狀態(tài),可以進行讀寫操作;nWE 為存儲器寫入信號,當置為 低電平時可以對存儲器執(zhí)行寫入操作,置為高電平時則可以對存儲器執(zhí)行讀取操作。內(nèi)存控 制模塊按照主狀態(tài)機的當前狀態(tài)來設(shè)定兩個控制信號的高低電平對片外存儲器進行控制。圖 三為在QuartusII 硬件開發(fā)平臺上通過邏輯分析儀實際采樣出來的片外靜態(tài)存儲器工作時序 波形圖[6],以中圖為例,存儲器由寫入狀態(tài)轉(zhuǎn)為讀取狀態(tài),存儲器的地址總線信號和數(shù)據(jù)總 線信號的變化就可看出存儲器狀態(tài)的變化,在寫入狀態(tài)時地址總線按時鐘周期發(fā)生變化,同 時會有48bit 并行數(shù)據(jù)寫入相應(yīng)內(nèi)存地址中,而在存儲器進入讀取狀態(tài)后,地址總線則變?yōu)?讀取地址,存儲器則會在延遲地址總線一個時鐘周期后將48bit 數(shù)據(jù)經(jīng)由數(shù)據(jù)總線讀出。
3.3 24bit/16bit數(shù)據(jù)轉(zhuǎn)換器的設(shè)計 [5] [6]
片外高速數(shù)據(jù)傳輸芯片為 16位輸入數(shù)據(jù)總線 [4],而由 FPGA內(nèi)部讀緩沖區(qū)讀出的是 24位并行數(shù)據(jù),因此需要將 24bit數(shù)據(jù)轉(zhuǎn)換成 16bit數(shù)據(jù)再輸出。考慮到傳送 12個 16bit數(shù)據(jù)可以等效為 8個 24bit數(shù)據(jù),故將數(shù)據(jù)輸出時鐘 Dclk用一個 0~11的計數(shù)器進行計數(shù),然后取其中的 8個連續(xù)時鐘讀取 24bit數(shù)據(jù),這樣就解決了 16bit數(shù)據(jù)和 24bit數(shù)據(jù)在傳輸上時鐘不匹配的問題。讀取的 24bit數(shù)據(jù)隨后被分成兩個 12bit數(shù)據(jù)依次裝入 16個 12bit移位寄存器中,再由 Dclk一位一位打出并拼裝成 16bit數(shù)據(jù),發(fā)送給幀同步產(chǎn)生及高速傳輸芯片控制器進行碼頭加載,將自己編寫的 16bit數(shù)據(jù)頭校驗碼以及其他一組信息碼插入數(shù)據(jù)流中輸出給高速數(shù)據(jù)傳輸芯片,完成整個數(shù)據(jù)轉(zhuǎn)換和發(fā)送過程。
4.實際測試結(jié)果
用 TLK1501[4]高速數(shù)據(jù)傳輸芯片集成的數(shù)據(jù)接收端口接收其發(fā)送端傳輸?shù)母咚俅袛?shù)據(jù)流,在芯片內(nèi)部自解碼之后再恢復(fù)成 16bit數(shù)據(jù)傳給 fpga,通過比對發(fā)送數(shù)據(jù)和接收數(shù)據(jù)的一致性就可以對邏輯設(shè)計、時序等方面進行驗證,以保證設(shè)計正確。在實際測試時,用一組設(shè)計好的 24bitDVI數(shù)據(jù)取代實際傳輸?shù)南袼匦盘枺渌叫盘杽t仍為實際 DVI同步信號,這樣做的目的就是可以對發(fā)送數(shù)據(jù)進行控制,方便與接收數(shù)據(jù)進行比對,設(shè)計的發(fā)送數(shù)據(jù)為一串依次加“1”的規(guī)律 24bit數(shù),因此如果接收回的數(shù)據(jù)信號仍為依次加 “1”的 24bit數(shù),則說明邏輯設(shè)計和時序方面沒有問題,設(shè)計方案可以用于實際操作中。
圖四上為發(fā)送數(shù)據(jù)波形圖,圖四下為接收數(shù)據(jù)波形圖。由圖中對比可以看出,接收數(shù)據(jù)同發(fā)送數(shù)據(jù)均為依次加“1”的 24bit數(shù)據(jù),實際測試結(jié)果證實整個高速實時數(shù)據(jù)傳輸系統(tǒng)設(shè)計滿足設(shè)計要求,可以用于實際操作中。

5.結(jié)語
本系統(tǒng)在實際測試中,發(fā)送端數(shù)據(jù)時鐘為 40MHz,由于高速數(shù)據(jù)傳輸芯片——TLK1501[4]可以傳輸 20倍頻的串行數(shù)據(jù)流,因此實際在信道中傳輸?shù)臄?shù)據(jù)速度可以達到 800MHz,如此高的傳輸速度可以滿足一般情況下的工程要求,而且本系統(tǒng)由于所選片外存儲器的容量和操作速度上限制,沒能將 TLK1501高速傳輸?shù)奶攸c充分發(fā)揮出來,相信在系統(tǒng)改進之后,傳輸速度達到 1G甚至更高的實時數(shù)據(jù)應(yīng)該可以實現(xiàn)!