
??? 摘 要:文字類主觀題的自動(dòng)評分是實(shí)現(xiàn)遠(yuǎn)程教育中在線考試系統(tǒng)的一個(gè)關(guān)鍵技術(shù),由于其自動(dòng)評判具有相當(dāng)難度,使自動(dòng)評分系統(tǒng)中在對語句結(jié)構(gòu)、關(guān)鍵字匹配、詞性、詞義以及語義方面的判斷還存在很多問題。通過對已有的算法分析,提出了一種方法,采用淺層次句法結(jié)構(gòu)分析和深層次語義分析相結(jié)合的算法計(jì)算相似度,該方法可以提高主觀題自動(dòng)評分的效率和準(zhǔn)確度,具有一定的實(shí)用價(jià)值。
??? 關(guān)鍵詞:自動(dòng)評分;動(dòng)態(tài)規(guī)劃;語句相似度;語義相似度
?
??? 目前,在線考試系統(tǒng)正在逐漸代替?zhèn)鹘y(tǒng)的考試系統(tǒng),能否實(shí)現(xiàn)主觀題自動(dòng)評分是在線考試系統(tǒng)中一個(gè)重要環(huán)節(jié)。對于主觀題的考查,由于它的答題涉及到人工智能、模式識(shí)別以及自然語言理解等方面的理論知識(shí),評閱時(shí)就需要解決很多技術(shù)上的問題,因而成為阻礙在線考試系統(tǒng)發(fā)展的一個(gè)技術(shù)難點(diǎn)。
??? 當(dāng)前的主觀題自動(dòng)評分算法中,多數(shù)使用的是對學(xué)生答案和標(biāo)準(zhǔn)答案中關(guān)鍵字匹配來計(jì)算語句相似度,如基于向量空間模型TF-IDF方法、詞性詞序相結(jié)合的方法以及基于語義依存樹等[1-4]。已有的這些方法要么從句子的表層結(jié)構(gòu)信息進(jìn)行匹配而忽略了語句語義分析,要么就是從語義分析而影響了整體語句的相似性,這些都會(huì)影響到自動(dòng)評分計(jì)算的精確度。由于漢語語言的結(jié)構(gòu)和語義的復(fù)雜性,一種意思可以用多種形式和多種關(guān)鍵字表達(dá),單從一方面很難對語句的意思作出準(zhǔn)確的判斷,因此提出了一種新的主觀題自動(dòng)評分算法策略,主要思想是采用淺層次句法結(jié)構(gòu)分析和深層次語義分析相結(jié)合的算法計(jì)算相似度,將這兩種思想結(jié)合起來使用可以互補(bǔ)不足,提高了主觀題自動(dòng)評分的準(zhǔn)確度。
1 語句相似度計(jì)算算法
??? 在主觀題自動(dòng)批改系統(tǒng)中,語句相似度是用來評價(jià)學(xué)生答案和標(biāo)準(zhǔn)答案的接近程度。針對漢語的特殊性和機(jī)器翻譯領(lǐng)域內(nèi)一些對語句相似度的研究,采用動(dòng)態(tài)規(guī)劃法來計(jì)算語句相似度,主要思想是對語句進(jìn)行層次句法分析。首先用正向最大匹配(MM)和基于詞頻統(tǒng)計(jì)的方法對句子分詞,將分詞后得到的語句視為詞的向量,分別對各個(gè)關(guān)鍵詞進(jìn)行匹配。然后在此基礎(chǔ)上利用動(dòng)態(tài)規(guī)劃算法求出最優(yōu)路徑及語句相似度[5]。
1.1 相關(guān)定義
??? 令P表示標(biāo)準(zhǔn)答案中的某一語句,Q表示學(xué)生答案中的某一語句。P和Q分別表示如下:P={P1,P2,…,Pm},Q={Q1,Q2,…,Qm},其中Pi表示P語句中的一個(gè)關(guān)鍵詞,Qj表示語句Q語句中的一個(gè)關(guān)鍵詞,且Pi=Pmi U Pgi, Qj=Qmj U Qgj,其中Pmi表示語句P中第i個(gè)詞的詞義集合,Pgi表示語句P中第i個(gè)詞的詞性集合;同理Qmj表示語句Q中第j個(gè)詞的詞義集合,Qgj表示語句Q中第j個(gè)詞的詞性集合。為了便于進(jìn)一步討論給出以下幾個(gè)定義:
??? 定義1:詞義、詞性相似度。詞義、詞性相似度可分別表示為:SMij=SM(Pmi,Qmj),SGij=SM(Pgi,Qgj)。
??? 定義2:關(guān)鍵詞相似度。關(guān)鍵詞相似度Wij=a×SMij+β×SGij其中a、β分別為詞義、詞性相似度的權(quán)值。
??? 定義3:詞向量的相似矩陣。用定義2計(jì)算出語句P和Q的所有關(guān)鍵詞的相似度Wij(i=1,2,…,m;j=1,2,j=i=1,2,…,n),形成一個(gè)m×n矩陣M,稱該矩陣為語句向量的相似矩陣。
??? 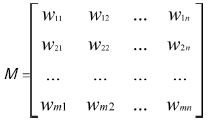
??? 定義4:拓展詞向量相似矩陣,對矩陣M進(jìn)行如下拓展,形成矩陣M',令M'0,0=0, M'i,0, M'0,j=0(i=1,2,…,m; j=1,2,…,n),則M'i,j=max{M'i-1,j-1+Wij, M'i,j-1+γ,M'i-1,j+γ},其中,γ表示詞位置不對應(yīng)時(shí)的懲罰系數(shù)。
1.2 語句相似度求解算法
??? (1)利用動(dòng)態(tài)規(guī)劃法先求出M'矩陣[6]。
??? (2)M'矩陣的初始化
??? 創(chuàng)建一個(gè)(m+1,n+1)矩陣,矩陣的行表示標(biāo)準(zhǔn)答案語句P的每個(gè)詞,矩陣的列表示學(xué)生答案語句Q的每個(gè)詞,利用定義4進(jìn)行初始化,將M'矩陣的M'i,0,M'0,j設(shè)置為0.其中i=0,1,2,…,m; j=0,1,2,…,n。
??? (3)利用定義1、2、3、4依次求解M'矩陣中的每個(gè)元素M'i,j。
??? (4)求解最優(yōu)相似矩陣
??? 先從點(diǎn)(m,n)開始,到(1,1)結(jié)束。在點(diǎn)(i,j)上選擇M'i-1,j-1+Wij,M'i,j-1+γ,M'i-1,j+γ最大者為最優(yōu)點(diǎn),所對應(yīng)的Mx, y作為路徑的前一個(gè)節(jié)點(diǎn)(x,y)。如果出現(xiàn)三者中兩部分值相同且最大時(shí),若該值在斜路徑上則選擇斜路徑上(i-1,j-1)作為路徑的前一個(gè)節(jié)點(diǎn);若不在斜路徑上,優(yōu)選水平方面(i-1,j)作為路徑的前一個(gè)節(jié)點(diǎn);依次遞推則選擇一條最優(yōu)路徑。這樣得到的路徑上就是一條最優(yōu)的路徑,路徑上最后一個(gè)點(diǎn)的值M'm,n表示了語句中所以詞的相似度之和。
??? 設(shè)L是標(biāo)準(zhǔn)答案語句的詞數(shù),則語句相似度為Sim=M’m,n/L。
2 語義相似度計(jì)算算法
??? Dekang Lin[7]認(rèn)為任何兩個(gè)事物的相似度取決于它們的共性(Commonality)和個(gè)性(Differentces),然后從信息理論的角度給出任意兩個(gè)事物相似度的通用公式:
??? 
??? 其中分子是描述A、B共性所需要的信息量的大小;分母是完整地描述出A、B所需要的信息量大小。劉群[8]認(rèn)為兩個(gè)詞語的相似度是它們在不同的上下文中可以互相替換且不改變文本的句法語義結(jié)構(gòu)的可能性大小。在本文中計(jì)算語義相似度是利用《知網(wǎng)》中詞語相似度的定義[9],可以把詞語語義相似度的計(jì)算歸結(jié)為“概念”相似度的計(jì)算;“概念”的相似度由描述它的“義原”的相似度得到。詞語存在著一詞多義的現(xiàn)象,知網(wǎng)中的一詞多義表現(xiàn)為單個(gè)詞語有多個(gè)概念,每個(gè)概念由一項(xiàng)定義來描述。比如:“打”在“打架”,“打太極”,“打獵”中的意義各不相同,知網(wǎng)中對應(yīng)的概念描述分別是:
??? DEF = fight| 爭斗
??? DEF = exercise| 鍛煉,sport| 體育
??? DEF = catch| 捉住, # animal| 獸
??? 詞語語義相似度的計(jì)算,嚴(yán)格來講應(yīng)該是計(jì)算概念之間的語義相似度。本文中采用劉群的思路,認(rèn)為兩個(gè)詞語的語義相似度是其所有概念之間相似度的最大值。
??? Sim(c1,c2)=maxSim(C1i,C2j)(i=1,2,…,m;j=1,2,…,n)
??? 其中, C1i是詞C1的m項(xiàng)概念,C2j是C2的n項(xiàng)概念。這樣就把兩個(gè)詞語之間的相似度問題歸結(jié)到了兩個(gè)概念之間的相似度問題。本文利用語句相似度中分詞方法將詞語標(biāo)注為概念,然后再對概念計(jì)算相似度。
2.1 義原相似度的計(jì)算
??? 由于所有的概念都最終歸結(jié)于用義原來表示, 詞語整體相似度由部分相似度合成的,所以義原的相似度計(jì)算是概念相似度計(jì)算的基礎(chǔ)。所有的義原根據(jù)上下位關(guān)系構(gòu)成了一個(gè)樹狀的義原層次體系,這里采用劉群的公式計(jì)算語義相似度的方法。
??? 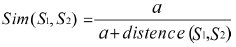
??? 其中,S1、S2表示兩個(gè)義原, distance(S1, S2)表示它們的路徑長度,a是一個(gè)可調(diào)節(jié)的參數(shù)。在知網(wǎng)的知識(shí)描述語言中,在一些義原出現(xiàn)的位置都可能出現(xiàn)一個(gè)具體詞(概念),并用圓括號(hào)( )括起來。所以本文在計(jì)算相似度時(shí)還要考慮到具體詞和具體詞、具體詞和義原之間的相似度計(jì)算。理想的做法應(yīng)該是先把具體詞還原成知網(wǎng)的語義表達(dá)式,然后再計(jì)算相似度。這樣做將導(dǎo)入函數(shù)的遞歸調(diào)用,有可能導(dǎo)致死循環(huán),反而使算法變得很復(fù)雜。由于具體詞在知網(wǎng)的語義表達(dá)式中只占很小的比例,因此可以作如下處理:具體詞與義原的相似度定義為一個(gè)比較小的常數(shù)γ。具體詞和具體詞的相似度按兩個(gè)詞相同則為1否則為0。
2.2 概念相似度的計(jì)算
??? 由義原相似度可以計(jì)算概念相似度,詞語整體相似要建立在部分相似的基礎(chǔ)上。把一個(gè)復(fù)雜的整體分解成部分,通過計(jì)算部分之間的相似度得到整體的相似度。假設(shè)兩個(gè)整體A和B都可以分解成以下部分:A分解成A1, A2,…, An, B分解成B1, B2,…,Bm ,那么這些部分之間的對應(yīng)關(guān)系就有m ×n 種。但并不是這些部分之間的相似度都對整體的相似度發(fā)生影響,所以應(yīng)該選擇那些發(fā)生影響的部分之間的相似度,選擇出來后再進(jìn)一步得到整體的相似度。在比較兩個(gè)整體的相似性時(shí),首先要做的工作是對這兩個(gè)整體的各個(gè)部分之間建立起一一對應(yīng)的關(guān)系,然后在這些對應(yīng)的部分之間進(jìn)行比較。如果某一部分的對應(yīng)物為空則將任何義原(或具體詞)與空值的相似度定義為一個(gè)比較小的常數(shù)δ;其他整體的相似度通過部分的相似度加權(quán)平均得到[10]。對于實(shí)詞概念的語義表達(dá)式,可以將其分成四個(gè)部分:
??? 第一獨(dú)立義原描述式:將兩個(gè)概念的這一部分的相似度記為Sim1(S1,S2);
??? 其他獨(dú)立義原描述式:語義表達(dá)式中除第一獨(dú)立義原以外的所有其他獨(dú)立義原(或具體詞),將兩個(gè)概念的這一部分的相似度記為Sim2(S1,S2);
??? 關(guān)系義原描述式:語義表達(dá)式中所有的關(guān)系義原描述式,將兩個(gè)概念的這一部分的相似度記為Sim3(S1,S2);
??? 符號(hào)義原描述式:語義表達(dá)式中所有的符號(hào)義原描述式,將兩個(gè)概念的這一部分的相似度記為Sim4(S1,S2)。
??? 于是兩個(gè)概念語義表達(dá)式的整體相似度記為:
??? 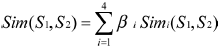
??? 其中,βi(1≤i≤4)是可調(diào)節(jié)的參數(shù),且有β1+β2+β3+β4=1,β1≥β2≥β3≥β4 。后者反映了Sim1到Sim4對于總體相似度所起到的作用依次遞減。由于第一獨(dú)立義原描述式反映了一個(gè)概念最主要的特征,所以應(yīng)該將其權(quán)值定義得相對比較大,一般應(yīng)在0.5 以上。
3 實(shí)驗(yàn)測試與分析
??? 以《操作系統(tǒng)》課程為實(shí)驗(yàn)素材,選取2006級(jí)計(jì)算機(jī)專業(yè)學(xué)生的90份考卷中4道簡答題為例。每道試題的分?jǐn)?shù)是10分,分別通過計(jì)算機(jī)自動(dòng)評分和人工閱卷,所得到的評分結(jié)果進(jìn)行分析,得到如下表所示:
?
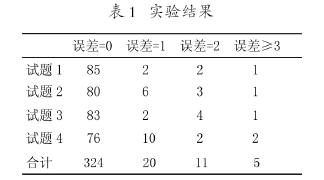
??? 其中誤差為自動(dòng)評分與人工評分所得分?jǐn)?shù)之差。由于系統(tǒng)中分詞詞典中缺少某些專用詞匯或由于語句繁瑣較長,可能導(dǎo)致得分的偏差。但是對于主觀題來說,在人工評閱時(shí),也受到教師情緒等諸多因素的影響,因此認(rèn)為只要誤差小于1分的就認(rèn)為得到了正確的評分。
??? 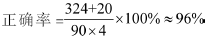
??? 本文綜合運(yùn)用了語句層次結(jié)構(gòu)、句法、詞性、語義等特征來計(jì)算相似度,不僅考慮詞語的局部相似,還從語句的整體出發(fā),考查了語句語義整體相似性,大大提高了相似度計(jì)算性能,降低了計(jì)算的時(shí)間復(fù)雜度,同時(shí)也提高了主觀題自動(dòng)評分的準(zhǔn)確性,具有一定的實(shí)用價(jià)值。
參考文獻(xiàn)
[1]?孟愛國,勝賢.一種網(wǎng)絡(luò)考試系統(tǒng)中主觀題自動(dòng)評分的算法設(shè)計(jì)與實(shí)現(xiàn)[J]. 計(jì)算機(jī)與數(shù)字工程,2005,33(7):147-150
[2]?李彬,劉挺,秦兵.基于語義依存的漢語句子相似度計(jì)算[J]. 計(jì)算機(jī)應(yīng)用研究, 2003,20(12): 15-17.
[3]?李素建.基于語義計(jì)算的語句相關(guān)度研究[J]. 計(jì)算機(jī)工程與應(yīng)用, 2002,38(7):75-76.
[4]?李明琴,李涓子,王作英,等. 語義分析和結(jié)構(gòu)化語言模型[J]. 軟件學(xué)報(bào), 2005,16(9): 1523-1533.
[5]?高思丹,袁春風(fēng). 語句相似度計(jì)算在主觀題自動(dòng)批改技術(shù)中的初步應(yīng)用[J].計(jì)算機(jī)工程與應(yīng)用, 2004,40 (14): 132 -135.
[6]?Levitin A . The Design and Analysis of Algorithm [M]. Beijing: Electronics Industry Press, 2003.
[7] LIN De Kang. An Information2Theoretic Definition of Similarity Semantic distance in Word Net [A] .In: Proceedings of the Fifteenth International Conference on Machine Learning [C].1998.
[8] 劉群,李素建.基于《知網(wǎng)》的詞匯語義相似度計(jì)[C]//第三屆漢語詞匯語義學(xué)研討會(huì),臺(tái)北,2002,5.
[9]?董振東,董強(qiáng).“知網(wǎng)”網(wǎng)站[DB/OL].http://www.keenage.com.
[10]?朱征宇,苑昆峰,陳杏環(huán).一種基于最大權(quán)匹配計(jì)算的信息檢索方法[J]. 計(jì)算機(jī)工程與應(yīng)用, 2007,43(33):176-179.