
??? 摘 要:通過(guò)實(shí)驗(yàn)對(duì)網(wǎng)頁(yè)結(jié)構(gòu)和特點(diǎn)進(jìn)行綜合分析,給出對(duì)網(wǎng)頁(yè)分塊的原則和方法,在分塊的基礎(chǔ)上根據(jù)網(wǎng)頁(yè)中噪音的出現(xiàn)規(guī)則提出了一種消除網(wǎng)頁(yè)噪音的方法,使搜索引擎對(duì)網(wǎng)頁(yè)的預(yù)處理階段有效消除網(wǎng)頁(yè)中的無(wú)關(guān)項(xiàng)和間接項(xiàng)的超連接,從而大大提高了搜索引擎的檢索質(zhì)量。
??? 關(guān)鍵詞:檢索質(zhì)量;分塊模型;搜索引擎
?
??? 隨著Internet的快速發(fā)展,大量的信息呈現(xiàn)在用戶(hù)面前,據(jù)統(tǒng)計(jì),國(guó)內(nèi)Web網(wǎng)頁(yè)數(shù)量達(dá)3億以上[1],上網(wǎng)用戶(hù)總?cè)藬?shù)達(dá)8 700萬(wàn),將獲取信息作為上網(wǎng)最主要目的網(wǎng)民所占比例最多,達(dá)到42.3%[2]。數(shù)據(jù)表明,Internet已成為人們獲取信息的重要資源,而Google、Yahoo、百度、新浪、天網(wǎng)等中英文搜索引擎是人們徜徉信息海洋、獲取信息的工具。然而,人們面對(duì)如此豐富的Web資源,使用搜索引擎發(fā)現(xiàn)自己真正需要的信息卻并非容易。一方面,各搜索引擎不斷改進(jìn)檢索技術(shù)來(lái)提高返回結(jié)果的精度,在一定程度上解決了人們獲取信息的問(wèn)題;另一方面,由于搜索引擎自身的問(wèn)題,返回的結(jié)果與用戶(hù)的要求仍有一定的距離,用戶(hù)對(duì)搜索引擎的滿(mǎn)意度不太高。主要表現(xiàn)為查詢(xún)結(jié)果中普遍存在大量的無(wú)關(guān)項(xiàng)和不含具體內(nèi)容的間接項(xiàng),造成搜索結(jié)果數(shù)量大、結(jié)果不精確、有用的結(jié)果淹沒(méi)在無(wú)用的結(jié)果之中的局面。用戶(hù)不得不花費(fèi)大量的時(shí)間在查詢(xún)結(jié)果中尋找相關(guān)項(xiàng),使得用搜索引擎來(lái)查找信息的目的難以達(dá)到。這種結(jié)果的原因之一是目前的搜索引擎沒(méi)有對(duì)網(wǎng)頁(yè)進(jìn)行處理或只做了簡(jiǎn)單的處理。
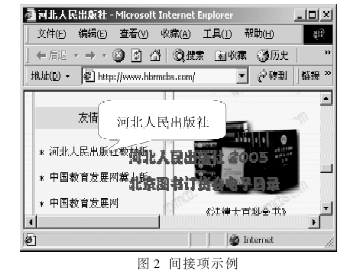
??? 目前的搜索引擎采用以關(guān)鍵字檢索為基礎(chǔ)的檢索技術(shù)[3-4],即搜索引擎按關(guān)鍵字對(duì)整個(gè)網(wǎng)頁(yè)進(jìn)行索引和檢索。在這種處理方法中,所有出現(xiàn)在網(wǎng)頁(yè)中的字詞都被用作索引項(xiàng),但實(shí)際的網(wǎng)頁(yè)中常常包含大量的與網(wǎng)頁(yè)主題無(wú)關(guān)的文字。例如,圖1和圖2是以“河北人民出版社”為關(guān)鍵字的檢索結(jié)果。圖1所示網(wǎng)頁(yè)的主要內(nèi)容是關(guān)于2004十大印象圖書(shū)介紹,其中包括上海人民出版社出版的《達(dá)芬奇密碼》,在網(wǎng)頁(yè)中注明的出處是新華網(wǎng)河北頻道。在這個(gè)網(wǎng)頁(yè)中包含了“河北”和“人民出版社”,搜索引擎誤把它當(dāng)做“河北人民出版社”的相關(guān)項(xiàng)。圖2所示網(wǎng)頁(yè)的主要內(nèi)容是一些圖書(shū)的介紹,在左邊的導(dǎo)航欄中出現(xiàn)了河北人民出版社的連接,真正提供具體信息的應(yīng)該是它指向的那個(gè)頁(yè)面,而那個(gè)頁(yè)面也應(yīng)該能被檢索到,因此,圖2所示網(wǎng)頁(yè)是多余的間接項(xiàng)。
?

?
等。在實(shí)際應(yīng)用中,塊的劃分要合理。塊劃分得過(guò)多,會(huì)把相關(guān)的內(nèi)容劃分到不同的塊區(qū),這樣將導(dǎo)致網(wǎng)頁(yè)與查詢(xún)關(guān)鍵字的相關(guān)度降低;塊劃分得過(guò)少,會(huì)把不相關(guān)的內(nèi)容劃分到同一個(gè)塊區(qū),這樣將導(dǎo)致查準(zhǔn)率的降低。例如,一篇文章由標(biāo)題、作者、出處和多個(gè)段落組成,顯然這些文字應(yīng)劃分在同一個(gè)塊區(qū)。經(jīng)過(guò)對(duì)大量網(wǎng)頁(yè)的統(tǒng)計(jì)分析,不外乎兩種情況。一種是網(wǎng)頁(yè)中不包含
??? 如果搜索引擎在對(duì)網(wǎng)頁(yè)標(biāo)引時(shí),把整個(gè)網(wǎng)頁(yè)上不同主題、不同作用的文字混合在一起進(jìn)行處理,那么,在檢索過(guò)程中根本無(wú)法排除如圖1所示的無(wú)關(guān)項(xiàng)。使用站點(diǎn)聚類(lèi)技術(shù),把出現(xiàn)在同一個(gè)站點(diǎn)上的結(jié)果項(xiàng)進(jìn)行合并,雖然可以排除大部分如圖2所示的間接項(xiàng),但是耗費(fèi)了查詢(xún)時(shí)間。本文提出一種在標(biāo)引前對(duì)網(wǎng)頁(yè)進(jìn)行預(yù)處理的方法,能夠排除上述的無(wú)關(guān)項(xiàng)和間接項(xiàng)。
??? 目前的搜索引擎對(duì)網(wǎng)頁(yè)的預(yù)處理較簡(jiǎn)單,幾乎保留了HTML網(wǎng)頁(yè)上所有的文字,這樣固然可以保證查全率,但從目前的網(wǎng)絡(luò)資源巨大豐富的角度來(lái)看,提高查準(zhǔn)率對(duì)用戶(hù)更具有實(shí)際意義。在研究領(lǐng)域里,有人提出了基于HTML標(biāo)記結(jié)構(gòu)的規(guī)律對(duì)特定網(wǎng)站進(jìn)行信息抽取[5],但不滿(mǎn)足搜索引擎對(duì)多種多樣的網(wǎng)站進(jìn)行處理的要求;有人提出“語(yǔ)義塊”的概念對(duì)網(wǎng)頁(yè)內(nèi)容分層,但沒(méi)有具體的實(shí)現(xiàn)方案[6];對(duì)于超連接的研究主要集中在對(duì)它所指向的頁(yè)面在檢索中的作用[7],但很少有人研究超連接對(duì)網(wǎng)頁(yè)的負(fù)面影響。
1 HTML網(wǎng)頁(yè)的塊結(jié)構(gòu)模型和解析方法
1.1 HTML網(wǎng)頁(yè)的塊結(jié)構(gòu)模型
??? 通過(guò)對(duì)大量的網(wǎng)頁(yè)進(jìn)行分析,發(fā)現(xiàn)人們?cè)谠O(shè)計(jì)網(wǎng)頁(yè)時(shí)通常是把網(wǎng)頁(yè)設(shè)計(jì)成幾個(gè)區(qū)域,把不同主題、不同作用的文字安排在不同的區(qū)域。結(jié)合HTML標(biāo)記的特點(diǎn),認(rèn)為網(wǎng)頁(yè)是由塊組成的,塊中可以再嵌套塊。因此,HTML網(wǎng)頁(yè)的塊結(jié)構(gòu)模型是:{<塊起始標(biāo)記><塊內(nèi)容><塊結(jié)束標(biāo)記>[,<塊起始標(biāo)記><塊內(nèi)容><塊結(jié)束標(biāo)記>,…]}。其中,塊內(nèi)容中可以再包含塊。實(shí)際的網(wǎng)頁(yè)大多是由多層的塊嵌套構(gòu)成的。
1.2 分塊原則及算法
??? HTML塊標(biāo)記有
、
、
、
、
標(biāo)記,只有一篇文章,顯然,這類(lèi)網(wǎng)頁(yè)只有一個(gè)塊區(qū);另一種是網(wǎng)頁(yè)中包含多個(gè)
標(biāo)記,而一篇文章的標(biāo)題、作者、出處和多個(gè)段落一般安排在某一個(gè)表格的一個(gè)或多個(gè)單元格中。因此,將網(wǎng)頁(yè)中的表格(
標(biāo)記)做為塊區(qū)比較合理。
??? 分塊原則如下:
??? (1)如果網(wǎng)頁(yè)中包含水平線標(biāo)記
,首先按水平線分塊;
??? (2)在上述分塊的基礎(chǔ)上,如果包含
標(biāo)記,按
分塊;
??? (3)如果在
中包含水平線標(biāo)記
,再按水平線分塊。
??? 分塊算法如下:
??? 查找水平線標(biāo)記,插入塊標(biāo)記;
??? While(文件沒(méi)有結(jié)束)
??? {查找塊起始標(biāo)記和結(jié)束標(biāo)記,位置存入tableLoc() ;
??? 同時(shí),在tableSym中簡(jiǎn)記為b和e; }
??? 將tableLoc中的位置數(shù)據(jù)排序,同時(shí)調(diào)整tableSym中的b、e標(biāo)記;
??? While(tableSym中的標(biāo)記數(shù)不等于0)
??? { 查找“be”;
??? 提取塊;
??? tableSym中的標(biāo)記數(shù)減2;}
1.3 消除噪聲的規(guī)則
??? 人們?cè)谥谱骶W(wǎng)頁(yè)時(shí),總是準(zhǔn)備了一定的素材,這些素材是網(wǎng)頁(yè)設(shè)計(jì)者希望通過(guò)網(wǎng)頁(yè)傳達(dá)給訪問(wèn)者的信息。但同時(shí)也會(huì)在網(wǎng)頁(yè)中增加一些連接到其他網(wǎng)頁(yè)的超連接,而這些超連接文字的作用僅僅起著向?qū)ё饔茫c頁(yè)面主題無(wú)關(guān),它們的加入會(huì)影響到頁(yè)面的原貌,把這樣的超連接文字定義為網(wǎng)頁(yè)的“噪聲”,把網(wǎng)頁(yè)中原本要表達(dá)的內(nèi)容定義為網(wǎng)頁(yè)的“主題內(nèi)容”。
??? 通過(guò)對(duì)大量網(wǎng)頁(yè)的統(tǒng)計(jì)分析,噪聲主要來(lái)源于超連接文字,但并非所有的超連接文字都是噪聲,因此要準(zhǔn)確地消除網(wǎng)頁(yè)中的噪聲也并非容易。
??? 網(wǎng)頁(yè)中的超連接文字可分為3類(lèi):
??? (1)超連接文字在網(wǎng)頁(yè)中僅僅起著向?qū)ё饔茫淠康氖翘峁┮粋€(gè)訪問(wèn)目錄。超連接文字在它所指向的網(wǎng)頁(yè)中還會(huì)出現(xiàn),這些頁(yè)面能夠被搜索引擎搜索到。因此,這類(lèi)超連接文字是本網(wǎng)頁(yè)的噪聲。一般說(shuō)來(lái),這類(lèi)超連接文字的前后還是超連接文字,所以噪聲通常聚集成塊。
??? 需要說(shuō)明的是索引網(wǎng)頁(yè)中的超連接文字雖然是網(wǎng)頁(yè)的主題,但是超連接文字在它所指向的網(wǎng)頁(yè)中還會(huì)出現(xiàn),這些頁(yè)面通常能夠被搜索引擎搜索到,所以,本網(wǎng)頁(yè)不必出現(xiàn)在搜索結(jié)果中。
??? (2)超連接文字在網(wǎng)頁(yè)中具有向?qū)Ш完愂龅碾p重功能,超連接文字引向另一個(gè)網(wǎng)頁(yè)或本網(wǎng)頁(yè)的其他位置的同時(shí),本身也是網(wǎng)頁(yè)主題內(nèi)容的一部分,這樣的超連接文字也是網(wǎng)頁(yè)的主題內(nèi)容,而不是噪聲。一般說(shuō)來(lái),這類(lèi)超連接文字的前后的文字不是超連接。
??? (3)超連接文字所指向的目標(biāo)文件中不會(huì)出現(xiàn)此超連接文字,目標(biāo)文件是搜索引擎不能直接搜索到的文件。例如,超連接文字指向的目標(biāo)是MP3格式文件、exe格式文件或圖片格式文件等,這些超連接文字不能視為網(wǎng)頁(yè)的噪聲。
??? 從網(wǎng)頁(yè)的結(jié)構(gòu)上看,(1)類(lèi)超連接文字聚集成塊,超連接文字與塊區(qū)內(nèi)所有文字的比值R接近于1;(2)類(lèi)超連接文字處在主題內(nèi)容塊區(qū),超連接文字與塊區(qū)內(nèi)所有文字的比值R遠(yuǎn)小于1。通過(guò)實(shí)驗(yàn)確定兩個(gè)閾值R1和R2。若R>R1,則確定為噪聲;若R
??? (1)在塊區(qū)中掃描超連接,如果超連接指向的目標(biāo)是網(wǎng)頁(yè),則將此超連接文字標(biāo)記為準(zhǔn)噪聲;如果超連接指向的目標(biāo)不是網(wǎng)頁(yè),則在網(wǎng)頁(yè)中保留此超連接文字。
??? (2)統(tǒng)計(jì)塊區(qū)內(nèi)超連接文字?jǐn)?shù)量及文字的總數(shù)量并計(jì)算其比值R,若R>R1,保留準(zhǔn)噪聲標(biāo)記;若R
2 實(shí)驗(yàn)及結(jié)果分析
??? 本文開(kāi)發(fā)了一個(gè)HTML網(wǎng)頁(yè)解析器實(shí)現(xiàn)了上述算法。實(shí)驗(yàn)中使用的網(wǎng)頁(yè)都是根據(jù)著名搜索引擎的搜索結(jié)果下載的真實(shí)網(wǎng)頁(yè)。實(shí)驗(yàn)中參數(shù)的取值分別是:R1=0.9;R2=0.3;S=3。由于文章篇幅的限制,在此略去實(shí)驗(yàn)結(jié)果的圖片。
??? 實(shí)驗(yàn)一是網(wǎng)頁(yè)的分塊實(shí)驗(yàn),實(shí)驗(yàn)中對(duì)數(shù)十個(gè)網(wǎng)頁(yè)進(jìn)行了分塊,正確率達(dá)100%;實(shí)驗(yàn)二使用100個(gè)網(wǎng)頁(yè)進(jìn)行了消除(1)類(lèi)超連接文字噪聲的實(shí)驗(yàn),其中98個(gè)網(wǎng)頁(yè)的無(wú)關(guān)項(xiàng)超連接和間接項(xiàng)超連接都被消除;實(shí)驗(yàn)三和實(shí)驗(yàn)四是保留(2)類(lèi)超連接文字和(3)類(lèi)超連接文字的實(shí)驗(yàn),正確率達(dá)100%。
??? 實(shí)驗(yàn)二的正確率與R1、R2、S的值有關(guān)。對(duì)于參數(shù)S而言,如果值過(guò)小,就會(huì)把一些有用的超連接文字消除,例如文章的標(biāo)題、作者、出處都有超連接時(shí),這些文字是網(wǎng)頁(yè)的重要內(nèi)容,不應(yīng)消除;如果S的值過(guò)大,會(huì)將一些噪聲保留。通過(guò)對(duì)大量網(wǎng)頁(yè)的統(tǒng)計(jì)分析,認(rèn)為S取值為3較合適,這樣即使在網(wǎng)頁(yè)中保留一些噪聲,由于數(shù)量較小,對(duì)網(wǎng)頁(yè)的影響也不大,同時(shí)對(duì)網(wǎng)頁(yè)有用的超連接文字也不會(huì)被誤認(rèn)為是噪聲而消除。
??? 本文介紹的網(wǎng)頁(yè)解析方法在搜索引擎和數(shù)據(jù)挖掘方面具有重要的意義和應(yīng)用前景。通過(guò)消除網(wǎng)頁(yè)的噪聲,使網(wǎng)頁(yè)的主題更加突出。在搜索引擎的返回結(jié)果中排除了無(wú)關(guān)項(xiàng)和間接項(xiàng),提高了搜索引擎的查準(zhǔn)率;在網(wǎng)絡(luò)使用行為挖掘領(lǐng)域,分析用戶(hù)感興趣的網(wǎng)頁(yè)方面,由于排除了噪聲的干擾,使得分析結(jié)果更準(zhǔn)確。
參考文獻(xiàn)
[1]?中國(guó)互聯(lián)網(wǎng)信息中心. 2003年中國(guó)互聯(lián)網(wǎng)絡(luò)信息資源數(shù)量調(diào)查報(bào)告,信息資源開(kāi)發(fā)利用調(diào)查報(bào)告[DB/OL].http://www.cnnic.net.cn/download/ manual/report20030330.doc: 60.
[2]?中國(guó)互聯(lián)網(wǎng)信息中心. 第十四次中國(guó)互聯(lián)網(wǎng)絡(luò)發(fā)展?fàn)顩r調(diào)查統(tǒng)計(jì)報(bào)告(2004年7月)[DB/OL].http://www.cnnic.net.cn/download/2004/2004072002.pdf
[3]?杜阿寧,方濱興,胡銘曾,等. 中文交互式網(wǎng)絡(luò)搜索引擎及其自學(xué)習(xí)能力[J].計(jì)算機(jī)工程與應(yīng)用,2003(10):148-150.
[4]?陳俊杰,薛云,宋翰濤,等. 基于Agent的元搜索引擎的研究與設(shè)計(jì)[J].計(jì)算機(jī)工程與應(yīng)用,2003(10): 33-36.
[5]?KUSH M N, WELD DS,DOOREMBOS. Wrapper Induction for Information Extraction,proceedings of the Fifteenth International Joint Conference on Artificial Intelligence, 1997: 729-735.
[6]?CARCHIOLO V, LONGHEU A, MALGERIM. Malgeri,M.,Structuring the Web,Database and Expert Systems Applications,2000.Proceedings.llth International Workshop on,1123-1127,2000.
[7]?N.Cras well, D. Hawking,S. e. Robertson,Effective Site Finding Using Link Anchor Information,SIGIR 2001,2001.
相關(guān)內(nèi)容