
摘 要: 提出一種在雙目視覺的條件下,利用光流金字塔跟蹤算法跟蹤關節(jié)點,以解決傳統光流不能進行大幅度運動跟蹤的問題,并利用極線約束進行三維重建獲得深度信息,結合對消失關節(jié)點的位置預測求出相應的三維坐標,再利用層次化的描述方法將三維坐標轉化為三維模型中各個關節(jié)點的旋轉角度,實現對人體運動的模型描述。實驗結果表明,該算法能有效地對人體的運動進行描述。
關鍵詞: 人體三維模型;光流金字塔;極線約束;層次化描述
人體的運動包含了相當豐富的信息,如從人體運動當中可以看出其動作、姿態(tài);根據目前的運動可以推測它在未來某個時刻的位置、速度;可以看出它的表情、神態(tài);可以了解一個人的個性等。正因為如此,對人體運動的研究有著相當廣闊的應用空間,如視頻監(jiān)控、運動分析檢測、虛擬現實、動畫制作等。而其中關于人體關節(jié)點的運動跟蹤檢測以及人體運動姿勢的三維重建更是其研究的熱門話題。人體姿勢的三維重建可以按照視點的個數分為基于單視點的三維重建[1]和基于多視點的三維重建。基于單視點三維重建的優(yōu)點在于它使用方便,可以在大多數的場合中使用,限制的條件較少,只需要一個攝像機或其他輸入設備。缺點是由于只有一個視點,得不到相應的深度信息,所以當有自遮擋的情況時會產生匹配的模糊性問題。而基于多視點的三維重建可以部分解決這個問題。與單視點相比,多視點易于進行三維重建,但多視點的跟蹤同樣存在特征對應及自遮擋等難點,而且多視點的自動對應也是目前比較有難度的一個課題。其中對于基于多視點的人體姿勢三維重建,大體上可以分為利用機器學習的方法和目標跟蹤的方法兩種。通過機器學習的方法,可以利用大量的先驗知識來獲得更加準確的有關三維人體姿勢的估計。然而,該方法需要大量的樣本數據,使用起來十分不方便而且費時,在一定程度上限制了它的應用。目標跟蹤的方法主要由兩個步驟組成:首先是在每一幀中為每一個特征點定位,并且在每一幀中跟蹤相應的特征點;然后是通過獲得特征點來對人體姿勢進行三維重建。本文提出一種在兩個攝像機的條件下,利用金字塔光流的方法對關節(jié)點進行跟蹤檢測,并利用極線約束進行三維重建,對運動過程中被遮擋的關節(jié)點進行預測處理,最后將求出的關節(jié)點三維坐標轉化成模型中的旋轉角,通過層次化的描述,用人體模型來顯示相應的動作姿態(tài)。
1 算法主要思想
1.1 三維人體模型
將人體看成是由關節(jié)點及其連接線段所組成的剛體的集合。如下肢是由膝關節(jié)連接的大腿和小腿兩個剛體。以一條線段來表示一個剛體,將人體的運動簡化為人體框架的運動,這樣就得到一個三維人體框架模型[2],如圖1、圖2所示。該人體模型共包含16個人體關節(jié)點,其中所有關節(jié)點之間的線段在任何時刻都不會發(fā)生形變,而且各個線段之間的長短比例關系可以事先根據個體情況進行適當調整[3]。

1.2 光流金字塔跟蹤算法
傳統的Lucas-Kanade的光流算法[4]主要基于以下三個假設:(1)亮度恒定,即圖像場景中目標的像素在幀間運動時外觀上保持不變。對于灰度圖像,需要假設像素被逐幀跟蹤時其亮度不發(fā)生變化。(2)時間連續(xù)或運動是“小運動”,即圖像的運動隨時間的變化比較緩慢。在實際應用中指的是時間變化相對圖像中目標運動的比例要足夠小,這樣目標在幀間的運動就比較小。(3)空間一致,即一個場景中同一表面上鄰近的點具有相似的運動,它們在圖像平面的投影也在鄰近區(qū)域。但是由于受人體運動和圖像噪聲的影響,前后幀中對應的特征點的亮點完全相等幾乎是不可能的,一方面是人體的運動往往幅度較大,光線難以保證均勻。另一方面由于運動會產生不可避免的遮擋,亮度甚至還會發(fā)生突變,因此傳統的方法在人體跟蹤中受到一定的局限。
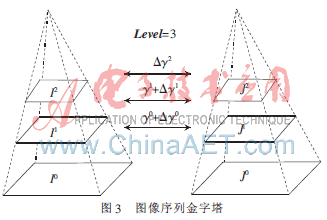
本文將對傳統的光流方法進行改進,使用一種基于圖像金字塔的角點梯度光流計算方法對圖像序列中的角點進行亞像素級跟蹤[5]。該方法的基本思想是:首先構造如圖3所示的圖像序列的金字塔,金字塔中較高的層是下層圖像向下降采樣后的圖像,原始圖像的層數為零。當圖像分解到一定的層后,相鄰幀的圖像間運動幅度就變得足夠小,就會滿足光流的幾個約束條件,此時便可進行光流計算。由高層向低層進行計算,當某一級的光流增量計算出來后,將加到其初始值上,作為其下一層的光流計算初值。這一過程持續(xù)進行直到估計出原始圖像的光流。


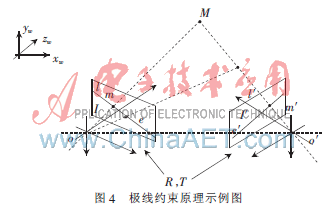
1.4 層次化描述
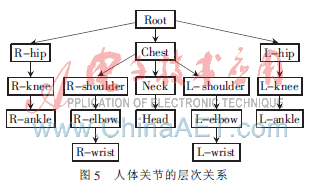
對于運動描述,本文使用一種層次化的運動描述方法[8],把人體模型看成是類似樹的結構,如圖5所示。樹的根節(jié)點是Root點,其他子節(jié)點對應人體模型中的各個關節(jié)點。整個人體的運動可以看成是由平移和旋轉組成的,Root點的旋轉決定人體模型所對應的方向,人體的平移即為Root點的位移量,其他各節(jié)點的旋轉是在以父節(jié)點為坐標原點的相對坐標系下的旋轉。各個關節(jié)點的位置可以根據各個關節(jié)點間的線段長度和旋轉向量求出,而關節(jié)點間的線段長度可作為先驗知識獲得。圖中的節(jié)點R_ankle,其位置與旋轉平移向量的對應關系為:

在已經知道每個關節(jié)點的運動除了包括繞父節(jié)點旋轉外,還包括隨父節(jié)點繞祖父節(jié)點旋轉和平移。因此,三維數據向旋轉平移數據轉化的關鍵是在各個非葉子節(jié)點處建立以該非葉子節(jié)點為原點的參考坐標系。以人體上臂為例來說明旋轉數據的計算方法。由于三維數據中沒有考慮扭矩的作用,可假設繞軸的運動分量為0;假設旋轉方向為先繞z軸旋轉β,再繞y軸旋轉θ。然后,將三維數據(x,y,z)變換到上臂參考坐標系下,其坐標為(m1,m2,m3),則參考坐標系下的三維數據(m1,m2,m3)與參考坐標系下的上臂初始位置(-l,0,0)之間的關系可以描述為[10]:

以此類推,可以計算出人體各個關節(jié)點的旋轉分量,其實現效果如圖6所示。

2 實驗結果
根據本文提出的算法,使用VC++開發(fā)一個人體運動跟蹤描述系統,可運行在Windows平臺上。實驗中的視頻是使用兩個具有平行光軸的攝像機拍攝而成。圖7是拍攝的一段圖像序列的跟蹤結果以及恢復出的三維骨架序列。

本文提出一種雙目視覺下的三維人體運動描述算法。該算法魯棒性較高,因為除利用貼在人體關節(jié)處的用于構建三維標記點的白色標記點之外,沒有利用圖像上的其他特征。實驗結果表明,該算法能有效地對人體運動進行描述,并且當有比較大幅度的運動及遮擋的情況時,依然可以較好地跟蹤和預測關節(jié)點位置,并進行重建顯示。未來的工作是要加入更多的人體約束和運動學約束以消除動作的多義性,進一步提高描述的準確性和魯棒性。
參考文獻
[1] Zou Beiji, Chen Shu, Cao Shi, et al. Automatic reconstruction of 3D human motion pose from uncalibrated monocular video sequences based on markerless human motion tracking[J]. Pattern Recognition, 2009,42:2.
[2] 劉小明,莊越挺,潘云鶴.基于模型的人體運動跟蹤[J].計算機研究與發(fā)展,1999,36:10.
[3] SHEN B C, SHIH H C, HUANG C L. Real-time human motion capturing system[C]. Proceedings of IEEE Interna-
tional Conference on Image Processing, 2005:11-14.
[4] 張永亮,盧煥章,高劼,等.一種改進的Lucas-Kanade光流估計方法[J].海軍航空工程學院學報,2009,24(4):444-445.
[5] 陳樂,呂文閣,丁少華.角點檢測技術研究進展[J].自動化技術與應用,2005,24(5):1-4.
[6] 張娟,潘建壽,吳亞鵬,等.基于雙目視覺的運動目標跟蹤與測量[J].計算機工程與應用,2009,45(25):191-193.
[7] 蔡濤,李德華,朱洲,等.基于彩色圖像序列的特征檢測和跟蹤[J].計算機工程,2005,31(8):12-13.
[8] Chen Yisheng, LEE J, PARENT R, et al. Markerless monocular motion capture using image features and physical constraints[C]. Proceedings of Computer Graphics International. Washington DC: IEEE Computer Society, 2005:36-43.
[9] KIM S M, PARK C B, LEE S W. Tracking 3D human body using particle filter in moving monocular camera[C].Proceedings of the 18th International Conference on Pattern Recognition. 2006:805-808.
[10] SILAGHI M, PLAENKERS R, BOULIC R, et al. Local and global skeleton fitting techniques for optical motion capture[C]. Proceedings of International Workshop on Modelling and Motion Capture Techniques for Virtual Environments. London: Spirnger-Verlag,1998:26-40.