
摘 要: 針對K-means算法中的初始聚類中心是隨機(jī)選擇這一缺點(diǎn)進(jìn)行改進(jìn),利用提出的新算法選出初始聚類中心,并進(jìn)行聚類。這種算法比隨機(jī)選擇初始聚類中心的算法性能有所提高,具有更高的準(zhǔn)確性。
關(guān)鍵詞: 歐氏距離;K-means;優(yōu)化初始中心
數(shù)據(jù)挖掘技術(shù)研究不斷深入與發(fā)展,作為數(shù)據(jù)挖掘技術(shù)中的聚類分析,也越來越被人們關(guān)注與研究。聚類分析是數(shù)據(jù)挖掘中一個非常活躍的研究領(lǐng)域,并且具有廣泛的應(yīng)用。聚類就是將數(shù)據(jù)集劃分成若干簇或者類的一個過程[1]。經(jīng)過聚類之后,使得同一簇中的數(shù)據(jù)對象相似度最大,而不同簇之間的相似度最小。
聚類是一種無監(jiān)督的學(xué)習(xí)算法,即把數(shù)據(jù)對象聚成不同的類簇,從而使不同類之間的數(shù)據(jù)相似度低,而同一個類中的相似度高,并且將要劃分的類是之前不知道的,其形成由數(shù)據(jù)驅(qū)動。聚類算法[1]分成基于劃分的、密度的、分層的、網(wǎng)格的、模型的。其中基于劃分的聚類算法中的K-均值算法(K-means算法)是最常用的一種聚類算法,同時也是應(yīng)用最廣泛的一種算法。K-means聚類算法主要針對處理大數(shù)據(jù)集時[2],處理快速簡單,并且算法具有高效性和可伸縮性。但是K-means算法也有一定的局限性[3],如K值必須事先給定,只能處理數(shù)值型數(shù)據(jù),初始聚類的中心是隨機(jī)選擇的,而其聚類結(jié)果的好壞直接取決于初始聚類中心的選擇。并且由于初始聚類中心隨機(jī)選擇,容易造成算法陷入局部最優(yōu)解。因此初始聚類中心的選擇十分重要。
本文針對隨機(jī)選擇初始聚類中心的缺點(diǎn),提出了一種新的改進(jìn)的K-means聚類算法。該算法產(chǎn)生的初始聚類中心不是隨機(jī)的,能夠很好地體現(xiàn)數(shù)據(jù)的分布情況,使得初始中心盡可能地趨向于比較密集的范圍內(nèi),從而進(jìn)行更好的聚類,最終消除了傳統(tǒng)K-means算法中由于初始聚類中心選擇是隨機(jī)的而產(chǎn)生的缺點(diǎn)。最后實(shí)驗(yàn)證明了這種算法的有效性與可行性。
1 傳統(tǒng)K-means算法
1.1 傳統(tǒng)K-means算法的思想
傳統(tǒng)的K-means算法的工作流程[1,4]:首先從n個數(shù)據(jù)對象任意選擇k個對象作為初始聚類中心;而對于所剩下其他對象,則根據(jù)它們與這些聚類中心的相似度(距離),分別將它們分配給與其最相似的(聚類中心所代表的)聚類;然后再計算每個所獲新聚類的聚類中心(該聚類中所有對象的均值)。不斷重復(fù)這一過程直到標(biāo)準(zhǔn)測度函數(shù)開始收斂為止。一般都采用均方差作為標(biāo)準(zhǔn)測度函數(shù)。其準(zhǔn)則函數(shù)定義如下: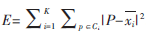 。其中,E為數(shù)據(jù)集中的對象與該對象所在簇中心的平方誤差的綜合,E越大說明對象與聚類中心的距離越大,簇內(nèi)的相似性越低,反之則說明相似性越高;p是簇內(nèi)的一個對象,Ci表示第i個簇,xi是簇Ci的中心,k是簇的個數(shù)。
。其中,E為數(shù)據(jù)集中的對象與該對象所在簇中心的平方誤差的綜合,E越大說明對象與聚類中心的距離越大,簇內(nèi)的相似性越低,反之則說明相似性越高;p是簇內(nèi)的一個對象,Ci表示第i個簇,xi是簇Ci的中心,k是簇的個數(shù)。
傳統(tǒng)的K-means算法具體描述如下[5]:
輸入:k,data[n];
輸出:K個簇的集合。
(1)任意選擇k個對象作為初始中心點(diǎn),例如c[0]=data[0],…c[k-1]=data[k-1]。
(2)根據(jù)簇中對象的均值,將每個對象指派給最相似的簇。
(3)更新簇均值,即計算每個簇中對象的均值。
(4)重復(fù)步驟(2)、(3),直到不再發(fā)生變化。
1.2 傳統(tǒng)K-means算法的局限性
傳統(tǒng)的K-means算法中對于K個中心點(diǎn)的選取是隨機(jī)的 [ 3],而初始點(diǎn)選取的不同會導(dǎo)致不同的聚類結(jié)果。為了減少這種隨機(jī)選取初始聚類中心而導(dǎo)致的聚類結(jié)果的不穩(wěn)定性,本文提出了一種關(guān)于初始聚類中心選取的方法,用來改變這種不穩(wěn)定性。

即所有樣本點(diǎn)的兩兩之間的距離之和除以樣本點(diǎn)n的組合數(shù)。
2.2 改進(jìn)算法流程
本算法的改進(jìn)建立在沒有離群點(diǎn)的數(shù)據(jù)集上,針對沒有離群點(diǎn)的數(shù)據(jù)進(jìn)行分析。
輸入:樣本點(diǎn),初值k。
輸出:k個簇的聚類結(jié)果,使平方誤差準(zhǔn)則最小。
步驟:
(1)求出兩兩樣本點(diǎn)之間的距離存入矩陣D中。
(2)初始化集合A以及中心點(diǎn)集合Center,最小距離的樣本點(diǎn)放入集合A中,并求出其中心最為第一個初始的聚類中心z1。
(3)求出次小距離的樣本點(diǎn)的中心,然后求出此中心與z1之間的距離,與Meandist進(jìn)行判斷。如果小于Meandist,則將此樣本點(diǎn)加入A中,再求第三距離小的樣本點(diǎn),重復(fù)步驟(3);如果大于Meandist,則求出此中心存入Center。
(4)Until集合Center中的個數(shù)等于k,初始聚類中心全部找到。
(5)用找到的初始聚類中心進(jìn)行K-means聚類。
算法舉例:
如圖1所示,假設(shè)有20個點(diǎn)數(shù)據(jù)集,并且已經(jīng)將孤立點(diǎn)排除,需要將其聚成k=3類。首先計算兩兩之間的距離,利用定義2求出Meandist,并找出最小的距離(如圖中的x1、x2);然后求出其中心,用紅色表示;找出距離次小的距離(如圖中的x3、x4),計算出x3、x4的中心,并加一步判斷。如果這個中心與前面求出的一個聚類中心之間的距離小于Meandist,那么就排除這個聚類中心,接著執(zhí)行找第三小的距離,并求其中心,直到找到K個初始聚類中心為止;反之,則求下一個初始聚類中心,直到找到k個初始聚類中心為止。

3 實(shí)驗(yàn)分析
為了便于分析與計算,本文采用的是二維數(shù)據(jù),并且數(shù)據(jù)類型是實(shí)型的,實(shí)驗(yàn)環(huán)境為MATLAB。為了進(jìn)行對比,分別采用了傳統(tǒng)的K-means算法與本文改進(jìn)的K-means算法進(jìn)行比較。
本文實(shí)驗(yàn)采用了兩組實(shí)驗(yàn)進(jìn)行驗(yàn)證,一組是隨機(jī)數(shù)據(jù),一組是標(biāo)準(zhǔn)數(shù)據(jù)庫集。
(1)采用隨機(jī)數(shù)據(jù)
本文用隨機(jī)產(chǎn)生的80個樣本分別采用傳統(tǒng)的K-means算法進(jìn)行聚類與本文的改進(jìn)算法進(jìn)行聚類,比較其聚類結(jié)果圖。
傳統(tǒng)算法采用隨機(jī)選取初始聚類中心有(0.950 1, 0.794 8)、(0.231 1,0.956 8)、(0.606 8,0.522 6),其聚類結(jié)果如圖2所示。
采用改進(jìn)算法的初始聚類中心有(0.339 9、0.028 4),(0.200 7,0.591 4)、(0.724 8,0.381 9),其聚類結(jié)果如圖3所示。
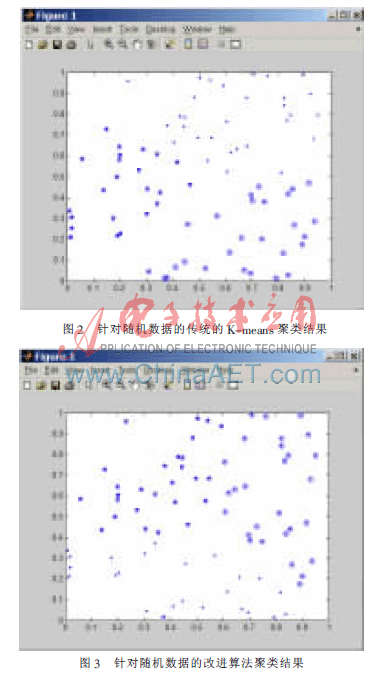
(2)采用標(biāo)準(zhǔn)數(shù)據(jù)集:Iris數(shù)據(jù)集
本文采用了Iris數(shù)據(jù)集,它是UCI數(shù)據(jù)庫中的一個標(biāo)準(zhǔn)數(shù)據(jù)集。Iris數(shù)據(jù)集包含有4個屬性,150個數(shù)據(jù)對象,可分為三類。選用Iris數(shù)據(jù)集前二維的數(shù)據(jù)進(jìn)行聚類。分別用傳統(tǒng)算法和改進(jìn)算法進(jìn)行聚類,其中分別用實(shí)心點(diǎn)、圈實(shí)心點(diǎn)以及五角星表示這三類。
傳統(tǒng)算法采用隨機(jī)選取初始聚類中心有(0.950 1, 0.582 8),(0.231 1,0.423 5)、(0.606 8,0.515 5),其聚類結(jié)果如圖4所示。
采用改進(jìn)算法的初始聚類中心有(0.009 9,0.015 0)、(0.294 2,0.639 2)、(0.651 2,0.190 5),其聚類結(jié)果如圖5所示。
對比這兩幅圖的聚類結(jié)果可以看出,采用改進(jìn)算法產(chǎn)生聚類結(jié)果比較穩(wěn)定準(zhǔn)確。
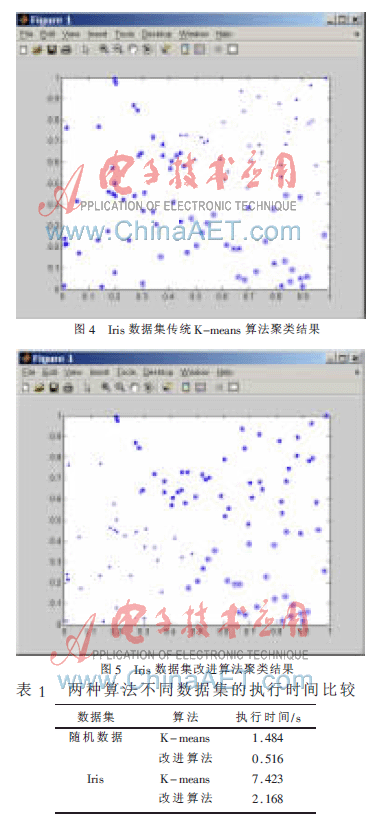
運(yùn)用K-means算法和本文改進(jìn)算法針對隨機(jī)數(shù)據(jù)和Iris數(shù)據(jù)分別實(shí)驗(yàn)得出的時間如表1所示。
K-means算法是應(yīng)用最為廣泛的一種基于劃分的算法,但是由于其初始中心的選擇是隨機(jī)的,從而影響了聚類結(jié)果,使得聚類結(jié)果不穩(wěn)定。本文主要是針對傳統(tǒng)K-means算法的這一缺點(diǎn),提出了一種新的改進(jìn)算法,即基于平均距離的思想,進(jìn)行初始聚類中心的選擇。實(shí)驗(yàn)證明,該算法是切實(shí)可行的,與傳統(tǒng)的K-means算法比較,有較好的聚類結(jié)果以及較短的運(yùn)行時間。但本文算法是基于先將噪聲點(diǎn)排除掉之后應(yīng)用此改進(jìn)算法進(jìn)行聚類、且是在點(diǎn)的分布比較均勻的前提下應(yīng)用,才有良好的效果。如果對于具有噪聲點(diǎn)的數(shù)據(jù)集有一定的局限性、而且是比較密集的點(diǎn)的情況下,這將在以后的學(xué)習(xí)研究中進(jìn)行探討。
參考文獻(xiàn)
[1] HAN J, KAMBER M. 數(shù)據(jù)挖掘概念與技術(shù)[M].范明,盂小峰,等譯.北京:機(jī)械工業(yè)出版社,2006.
[2] 孟海東,張玉英,宋飛燕.一種基于加權(quán)歐氏距離聚類方法的研究[J].計算機(jī)應(yīng)用,2006,26(22):152-153.
[3] 包穎.基于劃分的聚類算法研究與應(yīng)用[D].大連:大連理工大學(xué),2008:18-20.
[4] 李業(yè)麗,秦臻.一種改進(jìn)的K-means算法[J].北京印刷學(xué)院學(xué)報,2007,15(2):63-65.
[5] 張玉芳,毛嘉莉,熊忠陽.一種改進(jìn)的K-means算法[J].計算機(jī)應(yīng)用,2003,23(8):31-33.
[6] 袁方,周志勇,宋鑫.初始聚類中心優(yōu)化的k-means算法[J].計算機(jī)工程,2007,33(3):65-66.