
卷積碼因?yàn)槠渚幋a器簡單、編碼增益高以及具有很強(qiáng)的糾正隨機(jī)錯(cuò)誤的能力,,在通信系統(tǒng)中得到了廣泛的應(yīng)用,。基于最大似然準(zhǔn)則的維特比算法(VA)是在加性高斯白噪聲(AWGN)信道下性能最佳的卷積碼譯碼算法,,也是常用的一種算法。
一般來說,,實(shí)現(xiàn)軟判決維特比譯碼可以有三種方案供選擇:專用集成電路(ASIC)芯片,、可編程邏輯陣列(FPGA)芯片以及數(shù)字信號處理器(DSP)芯片。參考文獻(xiàn)[3]對這三種方案的優(yōu)劣做了詳細(xì)的比較,。使用DSP芯片實(shí)現(xiàn)譯碼是最為靈活的一種方案,,但速度也是最慢的,因?yàn)檎麄€(gè)譯碼過程都是由軟件來實(shí)現(xiàn)的,。
在近年來興起的軟件無線電技術(shù)中,,要求采用可編程能力強(qiáng)的的器件(DSP、CPU等)代替專用的數(shù)字電路,。對信道編解碼而言,,這樣做的優(yōu)點(diǎn)在于只需要在程序上加以少量改動,就可以適應(yīng)不同的編碼速率以及各種通信系統(tǒng)所要求的不同的編解碼方法,。然而速度的瓶頸限制了DSP譯碼在實(shí)時(shí)系統(tǒng)中的應(yīng)用,,因此提高DSP的譯碼速度對于軟件無線電有著重要的意義。本文的目的就是通過對譯碼程序結(jié)構(gòu)優(yōu)化,,來提高DSP芯片執(zhí)行VA算法的速度,。

1 維特比譯碼器
首先,需要定義兩個(gè)將在本文中用到的術(shù)語:
輸入幀--每次輸入譯碼器的比特,;
輸出幀--對應(yīng)一個(gè)輸入幀,,譯碼器輸出的比特。
圖1所示是卷積碼譯碼器(VA算法)的一種典型結(jié)構(gòu),。
以(2,,1,7)卷積碼為例(輸入幀含2比特,,輸出幀為1比特),,來說明譯碼器的三個(gè)主要部分。
1.1支路度量計(jì)算單元(BMG)
計(jì)算當(dāng)前輸入幀對應(yīng)的128條支路的路徑度量值,,并將其存人支路度量存儲單元(BMM),。
1.2加比選單元(ACS)
將支路度量值與相連的前面的路徑度量值相加得到延伸后的新路徑的度量值,;比較連接在同一個(gè)狀態(tài)上的兩條新路徑的度量值;選擇其中度量值較小的那條路徑(幸存路徑),,并將它的度量值存儲到新路徑度量存儲器(SM)中,,幸存路徑值(對應(yīng)編碼狀態(tài)的輸入比特)存儲到路徑存儲器(PM)中。
1.3幸存路徑計(jì)算單元
找到64條幸存路徑中度量值最小的一個(gè)(最大似然路徑),,通過回溯操作(Traceback)在PM中找出該路徑對應(yīng)的所有輸入比特,,依次輸出即為譯碼結(jié)果。

每輸出一幀,,都對應(yīng)著一次支路單元計(jì)算和64次ACS操作,。ACS操作在總的運(yùn)算時(shí)間里占了很大的比例。程序優(yōu)化的主要工作就是設(shè)法減少每個(gè)ACS操作所需要的時(shí)鐘周期數(shù),。
2 TMS320C6000 DSP芯片的特點(diǎn)
TMS320C6000系列DSP是基于TMS320C6000平臺的32位浮點(diǎn)DSP處理器,。它包含兩個(gè)子系列:用于定點(diǎn)計(jì)算的TMS320C62x系列和用于浮點(diǎn)計(jì)算的TMS320C67x系列TMS320C6000系列CPU結(jié)構(gòu)如圖2所示。時(shí)鐘頻率最高可達(dá)到250MHz,。該系列DSP包含兩個(gè)通用的寄存器組A和B,,每組有16個(gè)32位的寄存器。芯片內(nèi)含8個(gè)運(yùn)算功能單元:兩個(gè)乘法器(.M1和.M2),;六個(gè)算術(shù)邏輯單元(.L1.L2.S1.S2.D1.D2),。所有單元都能獨(dú)立并行操作。以TM320C6701為例,,它的工作頻率最高為167MHz,,最快速度可達(dá)8×167=1336MIPS。
實(shí)際上,,要實(shí)現(xiàn)這個(gè)速度存在很多瓶頸,,主要有下面幾種限制:
(1)功能模塊的限制 8個(gè)功能模塊能夠執(zhí)行的指令不盡相同。在實(shí)際程序中,,由于程序流程的限制,,指令的位置不能隨便調(diào)換,因此不可能在每一個(gè)時(shí)鐘周期都讓8個(gè)模塊同時(shí)工作,。程序優(yōu)化的主要手段就是要提高指令的并行程度,,即平均每一周期內(nèi)同時(shí)執(zhí)行的指令數(shù)。
(2)交叉路徑(Cross Path)的限制 每一個(gè)功能模塊都只能對其所屬的寄存器組中的寄存器進(jìn)行直接操作,。例如.L1只能將結(jié)果直接寫入寄存器組A,。如果要對另一個(gè)寄存器組執(zhí)行讀或?qū)懖僮鳎枰玫?quot;交叉路徑",,而整個(gè)CPU中只有兩條交叉路徑,。也就是說,一個(gè)周期內(nèi)至多能同時(shí)容納兩個(gè)相反方向的交叉讀寫,。
(3)多周期指令的限制 LD命令的功能是將數(shù)據(jù)從存儲器讀到寄存器中,,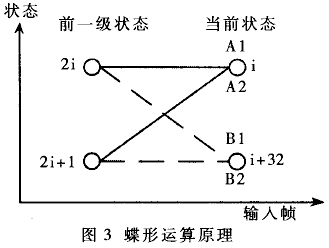 由.D模塊執(zhí)行,。但執(zhí)行LD命令后必須等待4個(gè)周期才能得到需要的數(shù)據(jù)。類似這樣的需要多個(gè)周期才能完成的命令(例如跳轉(zhuǎn)指令B)都成為提高指令并行處理程度的障礙,。
由.D模塊執(zhí)行,。但執(zhí)行LD命令后必須等待4個(gè)周期才能得到需要的數(shù)據(jù)。類似這樣的需要多個(gè)周期才能完成的命令(例如跳轉(zhuǎn)指令B)都成為提高指令并行處理程度的障礙,。
(4)對長數(shù)據(jù)操作的限制 C6000指令集只能以8比特,、16比特、32比特或者40比特為單位對數(shù)據(jù)進(jìn)行操作,。
3 VA在DSP上的優(yōu)化實(shí)現(xiàn)
ACS操作是整個(gè)VA算法中運(yùn)算量最大的部分,。在通常的程序設(shè)計(jì)中,使用一種對稱的蝶形運(yùn)算實(shí)現(xiàn)ACS操作,,每次可以完成兩個(gè)ACS操作,。因此優(yōu)化的核心任務(wù)就是減少每個(gè)蝶形運(yùn)算所消耗的運(yùn)算周期數(shù)。
蝶形運(yùn)算的原理請參見圖3,。對前一級的兩個(gè)相鄰狀態(tài)2i和2i+1,,一共有四條支路。計(jì)算出四條支路與接收信號的歐氏距離,,與兩個(gè)前一級狀態(tài)2i和2i+1中存儲的以前路徑的度量值相加得到四條路徑A1、A2,、B1,、B2的度量值。然后在對應(yīng)的兩個(gè)當(dāng)前狀態(tài)i和i+32下兩兩比較,,每個(gè)當(dāng)前狀態(tài)都留下度量值較小的一條路徑(幸存路徑),,同時(shí)將當(dāng)前狀態(tài)的度量值以及與幸存路徑對應(yīng)的輸入比特存人相應(yīng)的位置,準(zhǔn)備下一級計(jì)算,。
每個(gè)蝶形運(yùn)算包括:三次加載數(shù)據(jù)操作(load),,因?yàn)榭梢宰C明一個(gè)蝶形中的四條支路的度量具有相同的絕對值,所以每次只需要加載一個(gè)由BMU預(yù)先計(jì)算的結(jié)果,;四次加法操作,;兩次比較操作;比較之后的四次存儲操作,。其中,,四次加法操作可以在一個(gè)周期內(nèi)同時(shí)完成;狀態(tài)i和i+32的幸存路徑則是獨(dú)立計(jì)算和存儲的,。
針對前面提到的提高并行處理程度的幾個(gè)障礙,,可以用以下的方法分別加以解決:
(1)解決功能模塊的限制 可以用不同的命令相互替代。例如賦值操作MV只能用.L,、.S和.D功能模塊完成,,如果這些模塊都被其它的并行指令占用,可以用乘1的方法實(shí)現(xiàn)賦值,,而乘法指令MPY是用.M單元實(shí)現(xiàn)的,。類似地,,也可以用加零或減零的指令代替MV指令。
(2)解決交叉路徑的限制 需要依靠寄存器的分配和倒換,,讓同一指令涉及到的寄存器盡量處在同一個(gè)寄存器組中,,減少需要用到交叉路徑的機(jī)會。 (3)解決多周期指令的限制 加載數(shù)據(jù)的結(jié)果需要在4個(gè)周期以后才能得到,。為了有效地利用等待的這段時(shí)間,,在程序設(shè)計(jì)中把加載數(shù)據(jù)的指令放在前面的蝶形運(yùn)算中執(zhí)行,當(dāng)進(jìn)入本次蝶形運(yùn)算時(shí),,就能立即使用加載的新數(shù)據(jù),。同樣,本次蝶形運(yùn)算也要執(zhí)行為下一個(gè)蝶形運(yùn)算加載數(shù)據(jù)的指令,。B指令(跳轉(zhuǎn)指令)的問題可以用類似的方法來處理,。
(4)解決對長數(shù)據(jù)操作的限制 在(2,1,,7)卷積碼的VA譯碼器中,,幸存路徑存儲在PM里。每一個(gè)輸入幀對應(yīng)64個(gè)可能的狀態(tài),,會產(chǎn)生64比特的幸存路徑比較結(jié)果,。但TMS320C6701不能直接對64比特長的數(shù)據(jù)進(jìn)行讀寫操作,所以把PM分成兩個(gè)相同的32位數(shù)組PMO和PMl,。前者用來存儲狀態(tài)0-31對應(yīng)的幸存路徑,;后者存儲狀態(tài)32-64對應(yīng)的幸存路徑。PM0[i]和PM1[i]合在一起表示第i級網(wǎng)格的所有64條幸存路徑,。當(dāng)編碼約束長度更大時(shí),,也可以用同樣的辦法來分開存儲。例如(2,,1,,9)卷.積碼的PM就可以分成8個(gè)32位的數(shù)組來存儲256個(gè)狀態(tài)的信息?;厮莶僮鞯臅r(shí)候,,先確定路徑經(jīng)過哪一個(gè)狀態(tài),就可以從相應(yīng)的某一個(gè)數(shù)組中讀出路徑值,,只需要一次LD(加載)操作,。
圖4給出了優(yōu)化后的蝶形運(yùn)算流程圖。每次循環(huán)需要4個(gè)時(shí)鐘周期,,分別為圖中的E0-E3,,對應(yīng)著一次蝶形運(yùn)算。除了一些關(guān)鍵的加比選運(yùn)算之外,,還需要一些輔助運(yùn)算來實(shí)現(xiàn)循環(huán)以及寄存器的相互拷貝,,平均下來每個(gè)時(shí)鐘周期可并行執(zhí)行6條指令,。
4 優(yōu)化的效果和推廣
譯碼器輸出一幀所需要的時(shí)鐘周期數(shù)為
TBMC+n·TButter+Ttb
其中,TBMC,、TButter和Ttb分別表示支路度量計(jì)算,、蝶形運(yùn)算以及回溯操作所需要的周期數(shù),n表示每一輸出幀對應(yīng)的蝶形運(yùn)算的次數(shù),。
對于(2,,1,7)卷積碼譯碼器,,輸出一個(gè)幀需要32次蝶形運(yùn)算,,因此n=32。在回溯幸存路徑的時(shí)候,,有兩種方案輸出譯碼結(jié)果:一種是輸入一幀碼序列,,就輸出一幀譯碼結(jié)果;另一種是輸入N幀碼序列,,然后輸出N幀譯碼結(jié)果,。后一種方法輸出每一幀所需要的周期數(shù)可以減小為Ttb/N,但同時(shí)延時(shí)也增大為(N-1) TButter/TCPS,,其中TCPS是DSP每秒運(yùn)行的時(shí)鐘周期數(shù),,等于DSP的工作頻率。
如果使用TI公司定義的線性匯編語言用圖1所示的結(jié)構(gòu)來實(shí)現(xiàn)(2,,1,,7)譯碼,,經(jīng)過CCS2軟件編譯并自動進(jìn)行-o1級優(yōu)化以后,,每譯出一個(gè)比特,大約需要1000個(gè)時(shí)鐘周期(TButter =22,,n=32),,時(shí)鐘為167MHz時(shí)譯碼速度不超過160kbps。

在經(jīng)過本文所述方法優(yōu)化以后的程序中,,仍然是(2,,1,7)卷積碼,,TBMC =20,,TButter =4,n=32,;Ttb=700,,選擇N=16,因此譯出一個(gè)比特的平均時(shí)間是128+20+(700/16)=192個(gè)時(shí)鐘周期,。以TMS320C6701為例,,它工作在167MHz,,該程序的譯碼速率能達(dá)到大約870kbps,而延時(shí)僅為18μS,。顯然,,本文中的優(yōu)化程序性能遠(yuǎn)遠(yuǎn)高于自動優(yōu)化的效果。
對于不同編碼約束長度的卷積碼,,例如WCDMA中用到的(2,,1,9)碼,,蝶形運(yùn)算單元的流程與(2,,1,7)碼是完全相同的,。不同的地方在于每一級的狀態(tài)數(shù)增加到了256個(gè),。因此只需要對程序中的存儲和回溯路徑的指令做一些改動就可以使用。
對于不同的DSP系統(tǒng),,因?yàn)樵谥噶罴?、總線、寄存器等諸多方面存在差異,,針對C6000系列的優(yōu)化的匯編程序不能直接應(yīng)用,。但譯碼程序優(yōu)化中遇到的問題也是大致相同的,優(yōu)化的重點(diǎn)任務(wù)都是設(shè)法減少ACS的運(yùn)算量,,因此本文提出的程序流程的基本思想以及一些解決問題的技巧都可以繼續(xù)加以運(yùn)用,。