
摘 要: 提出了利用2個麥克風基于FPGA的聲源定位的方法,。具體通過基于相位變換改進的互相關(guān)方法成功在低信噪比(10 dB)的噪聲環(huán)境下完成聲源定位,。利用同樣的算法和硬件結(jié)構(gòu),可以在1片F(xiàn)PGA芯片上實現(xiàn)5組并行的時域處理的系統(tǒng),,而且每個麥克風的功耗只有77 mW~108 mW,。
關(guān)鍵詞: 聲源定位;時延估計,;FPGA
實時聲源定位在許多方面得到了應(yīng)用,,例如聲音的識別和電話會議,可以利用陣列麥克風來實現(xiàn)對多個聲源信號的獲取和并行處理[1-3],。由于處理多路語音信號需要多個處理器,,使得其實現(xiàn)費用昂貴,即便是使用DSP,,系統(tǒng)也會帶來很大的功耗,,因而限制了其在許多實際中的應(yīng)用。例如Brown大學發(fā)展的大規(guī)模麥克陣列系統(tǒng)利用多個DSP處理器和緩沖器來實現(xiàn)聲源的定位,,每個麥克的功耗達到了400 mW,。這大大超過了一些便攜式設(shè)備(PDA和手機)的功耗,因此最好的解決辦法是設(shè)計專用芯片,。
本文將闡述聲源定位系統(tǒng)在FPGA中的實現(xiàn),,為專用芯片提供一個可行性參考,具有很好的商業(yè)應(yīng)用價值,。以前采用DSP[4]或是DSP+FPGA[5]實現(xiàn)多路聲源信號的定位,,而本設(shè)計的整個定位系統(tǒng)除了前端的模擬部分外其余部分均在FPGA中實現(xiàn)。采取有效的算法后,,整個硬件實現(xiàn)的功耗可以控制在77 mW~108 mW之間,。
1 聲源定位的算法
現(xiàn)有許多算法[1-4]實現(xiàn)聲源定位,包括基于信號子空間的方法(例如MUSIC算法)和空間似然方法[2,,4]等,,最為常用的方法是估計信號的對應(yīng)的麥克對到達延時(TDOA)[3]估計方法。該方法的每一組麥克對將聲源定位在3維空間的一個雙曲面上,,這樣通過多個麥克對確定的雙曲面的交點能有效地實現(xiàn)聲源的定位,。TDOA估計方法已進行了很多研究[3,6],,最為普通的是廣義互相關(guān)GCC(Generalized Cross Correlation)方法[6],。與其他的方法相比,基于GCC的方法計算量小、計算效率高,。
假設(shè)2個麥克各自接收的信號分別為m1(t)和m2(t)(包括噪聲,、回響和聲音的延時信號)。常用的估計延時的方法是互相關(guān)方法:



PHAT權(quán)系數(shù)對應(yīng)的是相位變換,,在回響環(huán)境中效果明顯[1,,3,6],。UCC權(quán)系數(shù)為1,,對應(yīng)的是單純的互相關(guān)而沒有經(jīng)過濾波處理。
離散信號的GCC表示為:

如果采用方波作為補償函數(shù),,(4)式可以寫成:
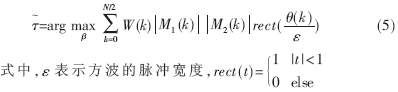
與(4)式相比,,(5)式用來估計TDOA的好處在于計算量的減少,而且在低的信噪比下具有更好的性能,,所以本文采用的是(5)式在FPGA中的實現(xiàn),。
2 FPGA的實現(xiàn)
設(shè)計中只考慮最簡單的一對麥克風的TDOA的估計,每個麥克風接收的信號經(jīng)過放大,、帶通濾波后以20 kHz的頻率進行采樣,,每個采樣的數(shù)據(jù)寬度為24位。取量化后的高8位送往FPGA(Xilinx Virtex II 2000)中進行運算,。盡管只討論了1對麥克風的情況,,多個麥克風對也能在同一個FPGA中實現(xiàn)(本文將會在后面具體介紹)。
輸入的采樣信號分別存儲在2個Buffer里(Buffer的大小為256~1 024個采樣點),,然后將輸出信號經(jīng)過漢寧窗濾波,,將數(shù)據(jù)轉(zhuǎn)化為16位的浮點數(shù)存儲在FFT的Buffer中,F(xiàn)FT模塊將各自的Buffer中的數(shù)據(jù)進行FFT運算,,如圖1所示,。
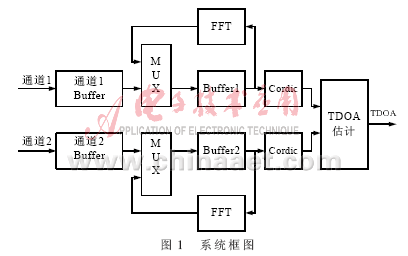
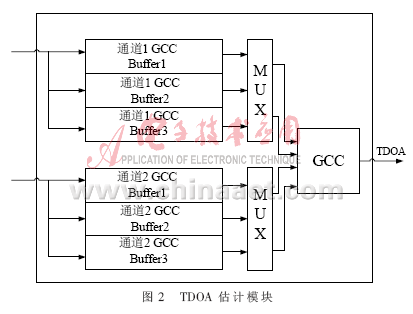
在FPGA的實現(xiàn)過程中采用CORDIC算法,它將傅里葉變換的復(fù)數(shù)表達形式轉(zhuǎn)換成幅度和相位表達形式,,在能夠減少計算量的同時不增加硬件的資源,。2路信號的幅度和相位計算出來后利用(5)式得到TDOA的估計,如圖2所示,。估計的過程涉及到根據(jù)(5)式搜索最大的τ,,搜索的范圍從-30 Ts~30 Ts(步進為采樣周期Ts),,ε=0.5,。為了實現(xiàn)TDOA的實時估計,硬件部分主要由3部分組成:輸入信號采集部分,、FFT的計算及幅相轉(zhuǎn)換部分,、TDOA的估計部分。2個Buffer已經(jīng)能夠滿足GCC前端數(shù)據(jù)緩存的要求,但考慮到CORDIC算法的誤差,,設(shè)計中多用了1個Buffer儲存數(shù)據(jù)的復(fù)數(shù)形式,,為系統(tǒng)的誤差分析提供數(shù)據(jù),確保定位精度,。
3 實驗結(jié)果
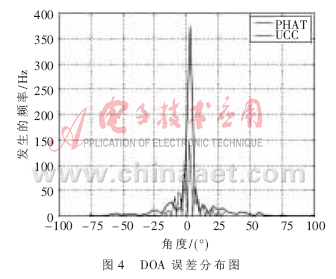
在實驗中Buffer的大小為1 024位,,對應(yīng)的時間緩存時間為50 ms。麥克風對按前面介紹的方法安置,。第一個實驗是對固定聲源的定位,,講話人在房間內(nèi)固定的地方說話,如圖3所示,。
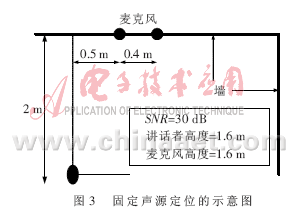
要注意保持麥克風對與講話者嘴的高度一致,。將麥克風得到的數(shù)據(jù)經(jīng)過放大、濾波,、采樣和FPGA處理,。系統(tǒng)噪聲由麥克風、放大器或濾波器等器件引入,,信噪比為30 dB,。利用麥克風獲取的50 ms的信號幀,分別用GCC和PHAT的權(quán)值來估計講話者的TDOA,。將每幀的到達時間時延τ轉(zhuǎn)換成波達方向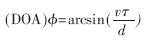 ,,其中,v表示聲音的傳播速度(取345 m/s),,d表示2個麥克風之間的距離(d=0.4 m),。
,,其中,v表示聲音的傳播速度(取345 m/s),,d表示2個麥克風之間的距離(d=0.4 m),。
通過DOA的估計和實際的DOA來計算DOA的誤差,實際的DOA可以通過講話者在環(huán)境的實際位置得到,。DOA誤差如圖4所示,。利用PHAT權(quán)值的TDOA定位精度要比UCC的好,因此試驗中利用的是PHAT權(quán)值,。為了得到基于FPGA的聲源定位系統(tǒng)在運動的聲源和不同背景噪聲下的性能,,本文利用PHAT權(quán)系數(shù)分別進行實驗。如圖5所示,,講話者從一個地方移動到另外一個地方,,整個移動持續(xù)1 min,講話者始終面對著麥克風對,。
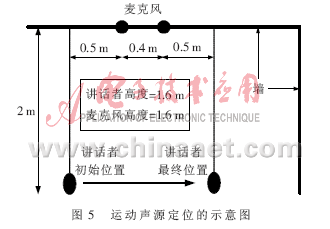
分別在信噪比為30 dB,、20 dB、10 dB,、0 dB的條件下對2個不同的講話者做試驗,,當信噪比為30 dB時,噪聲只由傳感器和信號處理系統(tǒng)自身引入;當信噪比為20 dB,、10 dB,、0 dB時,則通過提供一個高斯噪聲源來提供,,通過調(diào)整噪聲的強度可以實現(xiàn)信噪比的變化,。信噪比為30 dB的DOA誤差如圖6(a)所示,在不同的信噪比條件下,,0°的位置具有共同的峰值,,但是隨著信噪比的降低(20 dB和10 dB分別對應(yīng)圖6(b)和圖6(c)),誤差越來越大,,當降到0 dB時起不到定位的作用,,如圖6(d)所示。
實時聲源定位系統(tǒng)在Xilinx公司的xc3s1000 FPGA中實現(xiàn),,按文中提出的算法和實現(xiàn)方法可以實現(xiàn)10 dB信噪比以上的聲源定位,,整個系統(tǒng)具有很好的魯棒性。通常的處理多對麥克風對的信號算法常常利用DSP,,然而功耗的需求以及外圍設(shè)備的復(fù)雜使得DSP在許多場合受到限制,。利用本文介紹的算法,在FPGA Virtex II Pro-70中并行處理6個TDOA估計模塊,,時鐘選取為10 MHz,,功耗可以控制在0.776 W~1.074 W之間,試驗消耗的邏輯門為1 192 793,。通過流水線處理,,如果系統(tǒng)的時鐘為100 MHz,在1塊FPGA中能并行處理50個TDOA估計模塊,,不過功耗要增大到7.76~10.74 W之間,。由于Virtex II Pro-70有足夠的存儲空間,因此輸入Buffer部分無需額外的邏輯門,。與其他的方法相比,,如大型麥克陣列每個麥克的功耗為400 mW[5],本文的方法的平均功耗要小得多(每個麥克77~108 mW),,為減少VLSI電路的功耗提供了一個切實可行的途徑,。
參考文獻
[1] AARABI P,MAHDAVI A.The relation between speech segment selectivity and time delay estimation accuracy. In Proceedings of ICASSP,,May 2002.
[2] AARABI P,,ZAKY S. Robust sound localization using mult-source audiovisual information fusion. Information Fusion, 2001,,3(2):209-223.
[3] BRANDSTEIN M S,, SILVERMAN H. A robust method for speech signal time-delay estimation in reverberant rooms.IN Proceedings of ICASSP,May 1997.
[4] PONCA M,, SCHAUER C. FPGA implementation of a spike-based sound localization system. In 5th International Conference on Artificial Neural Networks and genetic Algorithms,, 2001.
[5] SILVERMAN H F,PATTERSON W R,,F(xiàn)LANAGAN J L.The huge microphone array.Brown University Technical Report,,May 1996.
[6] KNAPP C H, CARTER G.The generalized correlation method for estimation of time delay.IEEE Tarnsactions on ASSP,,1976,,24(4):320-327.