
摘 要: 為了從具有海量信息的Internet上自動(dòng)抽取Web頁(yè)面的信息,提出了一種基于樹(shù)比較的Web頁(yè)面主題信息抽取方法。通過(guò)目標(biāo)頁(yè)面與其相似頁(yè)面所構(gòu)建的樹(shù)之間的比較,簡(jiǎn)化了目標(biāo)頁(yè)面,并在此基礎(chǔ)上生成抽取規(guī)則,完成了頁(yè)面主題信息的抽取。對(duì)國(guó)內(nèi)主要的一些網(wǎng)站頁(yè)面進(jìn)行的抽取檢測(cè)表明,該方法可以準(zhǔn)確、有效地抽取Web頁(yè)面的主題信息。
關(guān)鍵詞: 信息抽取;相似頁(yè)面;樹(shù)比較;抽取規(guī)則
隨著Internet的飛速發(fā)展,Web已經(jīng)發(fā)展成為一個(gè)共享的數(shù)據(jù)空間,互聯(lián)網(wǎng)已成為人們獲取信息的重要渠道。而在Web數(shù)據(jù)呈幾何級(jí)數(shù)增長(zhǎng)的同時(shí),用戶查找、定位自己所需的信息變得越來(lái)越困難,如何快捷、有效地搜索信息成為亟待解決的問(wèn)題,Web信息抽取技術(shù)正是在這種背景下應(yīng)運(yùn)而生。Web信息抽取技術(shù)的核心是能夠從頁(yè)面所包含的無(wú)結(jié)構(gòu)或半結(jié)構(gòu)的信息中識(shí)別用戶感興趣的數(shù)據(jù),使其更為結(jié)構(gòu)化、語(yǔ)義更為清晰的格式。比如從新聞報(bào)道中抽取出新聞的時(shí)間、地點(diǎn)、主要內(nèi)容等;從介紹商品的網(wǎng)站上抽取出商品的價(jià)格、參數(shù)、評(píng)價(jià)等。通常,被抽取出來(lái)的信息以結(jié)構(gòu)化的形式描述,可以直接存入數(shù)據(jù)庫(kù)中,供用戶查詢以及進(jìn)一步分析利用。當(dāng)今,Internet已經(jīng)成為發(fā)布和傳播信息的最重要手段,網(wǎng)絡(luò)上的信息和活動(dòng)對(duì)人們的影響越來(lái)越明顯。一個(gè)良好的Web信息抽取系統(tǒng)可以高效地收集所需的網(wǎng)絡(luò)信息,并加以分析利用,如應(yīng)用于專業(yè)數(shù)據(jù)獲取、股票預(yù)測(cè)、用戶行為愛(ài)好分析等。目前,像Newsbot、Shopbot等一些針對(duì)特定領(lǐng)域的信息抽取/集成軟件已經(jīng)投入了商業(yè)應(yīng)用,幫助人們隨時(shí)獲得最新的新聞消息或收集同一商品的不同價(jià)格信息以決定合理的購(gòu)買方式。
Web的數(shù)據(jù)大部分都是以HTML形式出現(xiàn)的,這是一種半結(jié)構(gòu)化的數(shù)據(jù),缺乏對(duì)數(shù)據(jù)本身的描述,不含清晰的語(yǔ)義信息,模式也不太明確,這使得應(yīng)用程序無(wú)法直接解析并利用頁(yè)面上的信息;并且由于人們審美和商業(yè)的需求,充斥著大量與主題無(wú)關(guān)的修飾信息,如圖片、廣告、各種腳本語(yǔ)言等。如何排除干擾,有效地確定Web頁(yè)面中的主要數(shù)據(jù)區(qū)域并從中抽取出大家所關(guān)注的主題信息是本文的主要工作。
Web信息抽取技術(shù)發(fā)展至今,已經(jīng)有了很多比較成熟的方法,如基于文本統(tǒng)計(jì)的信息抽取技術(shù)[1]、基于HTML結(jié)構(gòu)的信息抽取技術(shù)[2]、基于隱馬爾科夫模型的信息抽取技術(shù)[3]等。這些方法各有利弊,但有一個(gè)需要共同面對(duì)的問(wèn)題是對(duì)于目標(biāo)頁(yè)面的不定期改版,原有的抽取規(guī)則可能會(huì)失效。本文提出的基于樹(shù)比較的Web主題信息抽取技術(shù)是一種基于HTML結(jié)構(gòu)的信息抽取方法。通過(guò)目標(biāo)頁(yè)面與其相似頁(yè)面的比較訓(xùn)練,簡(jiǎn)化目標(biāo)頁(yè)面并生成抽取規(guī)則,以此規(guī)則來(lái)完成目標(biāo)頁(yè)面主題信息的抽取。當(dāng)頁(yè)面改版,抽取規(guī)則失效時(shí),會(huì)自動(dòng)進(jìn)行重新學(xué)習(xí)而生成新的抽取規(guī)則。經(jīng)驗(yàn)證,本抽取系統(tǒng)具有良好的健壯性,能很好地解決這個(gè)問(wèn)題。
1 相關(guān)概念
1.1 DOM樹(shù)
DOM(Document Object Model)是由W3C制定的一種與平臺(tái)和語(yǔ)言無(wú)關(guān)的標(biāo)準(zhǔn)接口規(guī)范,它允許程序和腳本動(dòng)態(tài)訪問(wèn)、修改文檔的內(nèi)容、結(jié)構(gòu)和類型。它定義了一系列的對(duì)象和方法對(duì)DOM樹(shù)的節(jié)點(diǎn)進(jìn)行各種隨機(jī)操作。DOM樹(shù)中的節(jié)點(diǎn)可分為4種不同的對(duì)象:(1)Document對(duì)象。作為樹(shù)的最高節(jié)點(diǎn),Document對(duì)象是對(duì)整個(gè)文檔進(jìn)行操作的入口;(2)Element和Attr對(duì)象。這些節(jié)點(diǎn)對(duì)象都是文檔某一部分的映射,節(jié)點(diǎn)的定級(jí)層次恰好反映了文檔的結(jié)構(gòu);(3)Text對(duì)象。作為Element和Attr對(duì)象的子節(jié)點(diǎn),Text對(duì)象表達(dá)了元素或?qū)傩缘奈谋緝?nèi)容。Text節(jié)點(diǎn)不再包含任何子節(jié)點(diǎn);(4)集合索引。DOM提供了幾種集合索引方式,可以對(duì)節(jié)點(diǎn)按指定方式進(jìn)行遍歷,索引參數(shù)都是從0開(kāi)始記數(shù)的。DOM樹(shù)中的所有節(jié)點(diǎn)都是從Node對(duì)象繼承而來(lái),Node對(duì)象定義了一些最基本的屬性和方法,利用這些方法可以實(shí)現(xiàn)對(duì)樹(shù)的遍歷,同時(shí),根據(jù)屬性還可以得知節(jié)點(diǎn)的名稱、取值并判斷其類型。
1.2 XPath
XPath即為XML路徑語(yǔ)言(XML Path Language),它是一種用來(lái)確定XML文檔中某部分位置的語(yǔ)言。XPath基于XML的樹(shù)狀結(jié)構(gòu),提供在數(shù)據(jù)結(jié)構(gòu)樹(shù)中找尋節(jié)點(diǎn)的能力。最常見(jiàn)的XPath表達(dá)式是路徑表達(dá)式(XPath名稱的另一來(lái)源)。路徑表達(dá)式是從一個(gè)XML節(jié)點(diǎn)(當(dāng)前的上下文節(jié)點(diǎn))到另一個(gè)節(jié)點(diǎn)、或一組節(jié)點(diǎn)的書(shū)面步驟順序。這些步驟以“/”字符分開(kāi),每一步有三個(gè)成分:軸描述(用最直接的方式接近目標(biāo)節(jié)點(diǎn));節(jié)點(diǎn)測(cè)試(用于篩選節(jié)點(diǎn)位置和名稱);節(jié)點(diǎn)描述(用于篩選節(jié)點(diǎn)的屬性和子節(jié)點(diǎn)特征)。本文的抽取規(guī)則就是以XPath的形式給出,使用XPath定位所要抽取的信息在DOM樹(shù)中的節(jié)點(diǎn)。
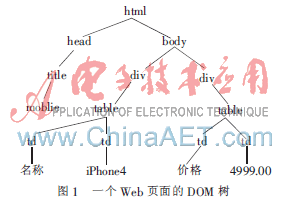
用Xpath來(lái)定義抽取規(guī)則,雖然簡(jiǎn)單明確,但從抽取系統(tǒng)的健壯性來(lái)考慮,卻存在著一定的隱患。假設(shè)要從圖1這樣一棵DOM樹(shù)上抽取商品iPhone4的價(jià)格,則可以定義XPath/html/body/div[2]/table/td[2]/text()為抽取規(guī)則。但是,當(dāng)目標(biāo)頁(yè)面的布局稍有改變時(shí),該抽取規(guī)則可能就不再適用,而需要重新訓(xùn)練學(xué)習(xí)[4]。比如,第一個(gè)div被刪除,第二個(gè)div的table下新加了一些節(jié)點(diǎn)等。本文提出的信息抽取算法在當(dāng)前的抽取規(guī)則失效后,會(huì)自動(dòng)獲取改版后的頁(yè)面重新進(jìn)行再學(xué)習(xí)、訓(xùn)練以生成新的抽取規(guī)則,確保了信息抽取系統(tǒng)的有效性。
1.3 DSE算法
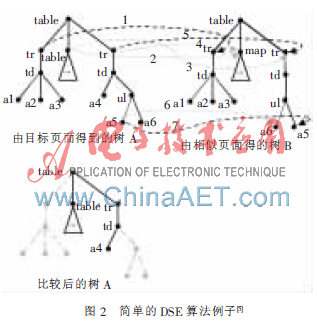
對(duì)于Web主題信息抽取來(lái)說(shuō),很重要的一步就是簡(jiǎn)化待抽取的Web頁(yè)面,確定主題信息所在的數(shù)據(jù)區(qū)域,刪減與主題無(wú)關(guān)的干擾信息。DSE[5](Data-rich Section Extraction)算法能很有效地完成這個(gè)工作。DSE的提出是基于這樣一個(gè)事實(shí):在同一個(gè)網(wǎng)站下,往往有大量使用同一設(shè)計(jì)模板的Web頁(yè)面,這些頁(yè)面具有相同或相似的HTML結(jié)構(gòu)。同時(shí),廣告、導(dǎo)航信息等與主題無(wú)關(guān)的內(nèi)容在這些頁(yè)面的相同位置不斷重復(fù)出現(xiàn)。這時(shí),通過(guò)對(duì)由這些頁(yè)面構(gòu)建的DOM樹(shù)進(jìn)行兩兩比較,就可以盡可能地排除這些干擾信息,縮小下一步處理的數(shù)據(jù)集合,提高信息抽取的效率和精度。DSE算法的基本過(guò)程如下:
(1)深度優(yōu)先遍歷兩棵待比較的樹(shù)A、B。其中樹(shù)A、B是由兩個(gè)相似的Web頁(yè)面構(gòu)建所得。
(2)在遍歷的同時(shí),不斷比較兩棵樹(shù)上相同位置的兩個(gè)節(jié)點(diǎn),對(duì)于相同的兩個(gè)內(nèi)部節(jié)點(diǎn),則繼續(xù)比較它們的子節(jié)點(diǎn)。對(duì)于葉子節(jié)點(diǎn),如果比較結(jié)果相同,則把它們從該樹(shù)上刪除;如果不同,則繼續(xù)比較下一個(gè)葉子節(jié)點(diǎn)。只有當(dāng)一個(gè)節(jié)點(diǎn)的所有子節(jié)點(diǎn)都被刪除后,才會(huì)刪除該節(jié)點(diǎn)。
(3)當(dāng)遍歷整棵樹(shù)后,樹(shù)A、B中重復(fù)出現(xiàn)的與主題無(wú)關(guān)節(jié)點(diǎn)均已被刪除。
圖2顯示了一個(gè)簡(jiǎn)單的DSE算法的DOM樹(shù)比較過(guò)程。可以看到,樹(shù)A經(jīng)一次DSE算法比較后,一部分與主題信息無(wú)關(guān)的重復(fù)內(nèi)容已被刪除,頁(yè)面A對(duì)應(yīng)的DOM樹(shù)已得到了很大程度的簡(jiǎn)化。
2 抽取算法及實(shí)現(xiàn)
2.1 抽取算法
本文進(jìn)行的信息抽取算法具體步驟如下:
(1)構(gòu)建目標(biāo)頁(yè)面的DOM樹(shù)。由網(wǎng)上獲得的目標(biāo)頁(yè)面的HTML源文件并構(gòu)建其對(duì)應(yīng)的DOM樹(shù)。
(2)獲取目標(biāo)頁(yè)面的幾個(gè)相似頁(yè)面。可利用正則表達(dá)式匹配等方法判斷是否屬于目標(biāo)頁(yè)面的相似頁(yè)面。
(3)用DSE算法對(duì)目標(biāo)頁(yè)面與其相似頁(yè)面進(jìn)行比較匹配,簡(jiǎn)化待抽取的目標(biāo)頁(yè)面,具體的比較次數(shù)需要看頁(yè)面的復(fù)雜程度,一般為1~3次。只有盡可能地簡(jiǎn)化目標(biāo)頁(yè)面的DOM樹(shù),縮小下一步處理的數(shù)據(jù)集合,才能有效提高抽取算法的速度和效率。
(4)在簡(jiǎn)化后的DOM樹(shù)上進(jìn)行遍歷,尋找信息量最大的節(jié)點(diǎn),并生成從根到該節(jié)點(diǎn)的XPath。
(5)由XPath生成抽取規(guī)則和模板,并儲(chǔ)存相關(guān)模板信息,用于今后該類頁(yè)面的信息抽取。
(6)用生成的規(guī)則完成信息抽取,并把數(shù)據(jù)保存到數(shù)據(jù)庫(kù)中。
2.2 系統(tǒng)的實(shí)現(xiàn)
如圖3所示,根據(jù)設(shè)計(jì)目標(biāo),將系統(tǒng)分為以下模塊:
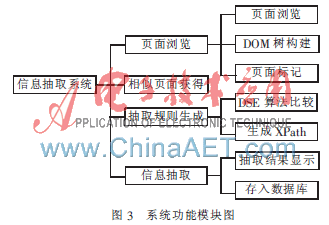
(1)頁(yè)面瀏覽模塊:實(shí)現(xiàn)用戶對(duì)Web頁(yè)面的瀏覽和標(biāo)記功能。用戶可以在內(nèi)置的瀏覽器中訪問(wèn)該頁(yè)面,也可以在頁(yè)面中進(jìn)行標(biāo)記。同時(shí),在界面上方構(gòu)建生成的DOM樹(shù)中,也可以對(duì)各節(jié)點(diǎn)進(jìn)行選擇查看和標(biāo)記。
(2)相似頁(yè)面獲得模塊:獲得與目標(biāo)頁(yè)面模板相同、結(jié)構(gòu)一致的頁(yè)面,用于后續(xù)的抽取規(guī)則訓(xùn)練算法。
(3)抽取規(guī)則生成模塊:用DSE算法進(jìn)行相似頁(yè)面的比較訓(xùn)練,尋找待抽取信息所在的節(jié)點(diǎn),生成XPath,形成抽取規(guī)則。
(4)信息抽取模塊:由抽取規(guī)則進(jìn)行抽取,顯示結(jié)果,并存入數(shù)據(jù)庫(kù)。
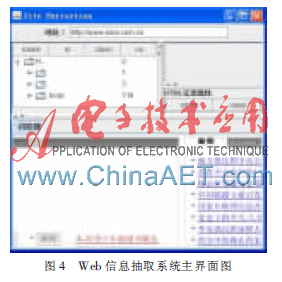
本信息抽取系統(tǒng)具體實(shí)現(xiàn)使用Java編程,以Java Swing制作界面。運(yùn)行程序后,可以輸入任意網(wǎng)址打開(kāi)頁(yè)面,并生成該頁(yè)面的DOM樹(shù)于界面左上方。比如,輸入http://www.sina.com.cn后,信息系統(tǒng)抽取主界面如圖4所示。
2.3 實(shí)驗(yàn)結(jié)果及分析
為了驗(yàn)證本算法的有效性,運(yùn)用本系統(tǒng)對(duì)新浪、搜狐等網(wǎng)站的近千個(gè)新聞頁(yè)面進(jìn)行了試抽取,并人工檢驗(yàn)了抽取的有效性。實(shí)驗(yàn)結(jié)果表明,大約98.2%的頁(yè)面都能正確抽取頁(yè)面的主題信息,只有極少數(shù)的頁(yè)面抽取失敗或無(wú)法抽取。可見(jiàn),本抽取算法具有一定的推廣應(yīng)用價(jià)值。
本文提出了一種基于樹(shù)比較的Web頁(yè)面主題信息抽取算法,該算法能快速、準(zhǔn)確、有效地抽取目標(biāo)頁(yè)面的主題信息。如何將該算法更好地應(yīng)用于信息檢索、數(shù)據(jù)挖掘的各方面是今后的主要工作。如應(yīng)用于搜索引擎的搜索算法中,提高搜索引擎的檢索速度和精度;或?qū)σ勋@得的頁(yè)面信息進(jìn)行進(jìn)一步的數(shù)據(jù)挖掘,以發(fā)現(xiàn)其中有用的信息和知識(shí)。
參考文獻(xiàn)
[1] 孫承杰,關(guān)毅.基于統(tǒng)計(jì)的網(wǎng)頁(yè)正文信息抽取方法的研究[J].中文信息學(xué)報(bào),2004,18(5):17-22.
[2] 張彥超,劉云,李勇,等.基于自動(dòng)生成模板的Web信息抽取技術(shù)[J].北京交通大學(xué)學(xué)報(bào),2009,33(5):40-45.
[3] 祝偉華,盧熠,劉斌斌.基于HMM的Web信息抽取算法的研究與應(yīng)用[J].計(jì)算機(jī)科學(xué),2010,37(2):203-206.
[4] DALVI N, BOHANNON P, SHA F. An approach based on a probabilistic tree-Edit model[A]. Proceedings of the 35th SIGMOD International Conference on Management of Data(SIGMOD’09)[C]. New York:ACM Press,2009:335-348.
[5] Wang Jiying, FRED H. LOCHOVSKY.Data-rich section extraction from HTML pages[A]. Proc 3rd International Conference on Web Information System Engineering (WISE’02)[C].Singapore:IEEE Computer Society Press,2002:1-10.