
文獻(xiàn)標(biāo)識(shí)碼: A
文章編號(hào): 0258-7998(2011)12-0029-04
在軍事應(yīng)用領(lǐng)域,基于通用信號(hào)的處理平臺(tái),通常需要實(shí)現(xiàn)高速大容量的數(shù)據(jù)存儲(chǔ)。如何解決數(shù)據(jù)I/O和存儲(chǔ)帶寬瓶頸,以滿足雷達(dá)、聲納等系統(tǒng)對(duì)高速大容量數(shù)據(jù)存儲(chǔ)的要求,以及如何基于不同的架構(gòu)平臺(tái),開發(fā)通用、開放的存儲(chǔ)模塊,是需要解決的一個(gè)問題。
現(xiàn)階段聲納某型數(shù)據(jù)記錄儀采用CPCI架構(gòu),記錄儀中的數(shù)據(jù)采集板卡與信號(hào)處理機(jī)之間的通信接口采用并行的LVDS連接線,數(shù)據(jù)采集板卡通過PCI總線將接收到的數(shù)據(jù)提交至主控板進(jìn)行存儲(chǔ)。由于受并行連接線間串?dāng)_和PCI總線帶寬的雙重限制,記錄儀的性能、通用性和可擴(kuò)展性差,存儲(chǔ)速率也不理想,不能很好地滿足未來聲納系統(tǒng)對(duì)實(shí)時(shí)數(shù)據(jù)存儲(chǔ)的要求。因此,基于新架構(gòu)和高速串行總線的數(shù)據(jù)記錄儀的研究變得十分迫切。
基于上述問題,本文提出了一種基于COM Express架構(gòu)的新型數(shù)據(jù)記錄儀的設(shè)計(jì)與實(shí)現(xiàn)方法,并且對(duì)其硬件重要組成部件——光纖采集子卡進(jìn)行了詳細(xì)討論,最后給出了測(cè)試結(jié)果。
1 記錄儀系統(tǒng)結(jié)構(gòu)與關(guān)鍵技術(shù)
1.1 記錄儀系統(tǒng)結(jié)構(gòu)
本設(shè)計(jì)從架構(gòu)體系和總線結(jié)構(gòu)兩個(gè)方面進(jìn)行考慮,選擇了德國(guó)控創(chuàng)公司的ETXexpress-PC模塊作為處理器單元,在COM Express載板上設(shè)計(jì)了XMC-PCIE規(guī)格的夾層卡作為光纖數(shù)據(jù)采集模塊,同時(shí)使用4個(gè)500 GB的磁盤組成RAID0存儲(chǔ)陣列完成新型記錄儀的設(shè)計(jì)。記錄儀結(jié)構(gòu)框圖如圖1所示。

控創(chuàng)公司的ETXexpress-PC模塊使用Intel公司的45 nm工藝級(jí)酷睿2雙核處理器以及GS45和ICH9M芯片組,支持SATA 、USB、PCI Express、千兆以太網(wǎng)等高速接口,并且模塊都嚴(yán)格遵循COM Express規(guī)范,便于載板的升級(jí),減少了重復(fù)設(shè)計(jì)帶來的資源浪費(fèi)[1]。
為加速產(chǎn)品的開發(fā),記錄儀主要是在控創(chuàng)公司提供的一款COM Express評(píng)估板的基礎(chǔ)上進(jìn)行設(shè)計(jì)的。在有限的載板空間上,為了給光纖采集卡提供足夠的安裝空間,設(shè)計(jì)保留了原載板的VGA、PS/2、RS232、USB、LAN等必須的外圍接口,去掉了Express Card、Mini Express等記錄儀不需要卻占用大量空間的接口。載板上沒有給硬盤留出空間,是因?yàn)閷?shí)際應(yīng)用中為了方便硬盤的拆卸和更換,記錄儀的機(jī)箱設(shè)計(jì)了專門的硬盤倉(cāng)。SATA硬盤是通過定制的加固SATA連接線與載板連接,所以只需要在載板的合適位置安裝上定制的SATA卡座即可。
1.2 關(guān)鍵技術(shù)
COM(Computer On Module)Express是國(guó)際工業(yè)電氣協(xié)會(huì)(PICMG)定義的計(jì)算機(jī)模塊標(biāo)準(zhǔn),由幾大嵌入式工業(yè)計(jì)算機(jī)廠商共同制定[2]。COM Express的處理器模塊集成了CPU和南北橋芯片,所有的I/O功能都通過AB和CD兩個(gè)440 PIN的雙排連接器實(shí)現(xiàn)。其中,AB連接器定義了PCI Express、SATA、SDVO、千兆以太網(wǎng)以及USB等高速接口,CD連接器定義了PCI、IDE等傳統(tǒng)的并行總線接口。用戶可以根據(jù)不同的應(yīng)用場(chǎng)合選擇不同CPU性能、功耗、I/O能力的處理器模塊,以及開發(fā)不同的功能模塊。功能模塊一般都設(shè)計(jì)成標(biāo)準(zhǔn)的接口,通過特定的連接器與載板相連。與傳統(tǒng)的CPCI架構(gòu)相比,COM Express具有接口豐富、使用靈活、開發(fā)周期短的優(yōu)勢(shì)。
數(shù)字光纖通信是一種遠(yuǎn)程數(shù)據(jù)傳輸技術(shù),具有高帶寬、低延遲、高可靠性、傳輸距離長(zhǎng)、抗干擾性強(qiáng)、技術(shù)成熟等優(yōu)點(diǎn)[3]。點(diǎn)到點(diǎn)的光纖通信速率可以達(dá)到2 Gb/s~4 GB/s,在遠(yuǎn)程數(shù)據(jù)采集、遠(yuǎn)程實(shí)時(shí)監(jiān)控的領(lǐng)域有著廣泛的應(yīng)用前景。本設(shè)計(jì)選用光纖來代替并行LVDS連接線作為記錄儀數(shù)據(jù)采集接口,很好地克服了高速串?dāng)_和通信距離的問題。
傳統(tǒng)的32 bit/33 MHz PCI總線的理論傳輸速率為133 MB/s,遠(yuǎn)遠(yuǎn)達(dá)不到要求,成為了制約記錄儀存儲(chǔ)性能的主要因素。PCI Express是第三代高性能I/O總線,在總線結(jié)構(gòu)上由并行總線變?yōu)榱舜锌偩€,采用點(diǎn)到點(diǎn)的互連,大大提高了系統(tǒng)的傳輸帶寬。并且其總線結(jié)構(gòu)從地址空間、配置機(jī)制以及軟件上均保持了與PCI總線的兼容[4]。使用PCIE總線代替PCI總線作為數(shù)據(jù)采集卡與主控板之間的數(shù)據(jù)通路,不僅可以大幅提高存儲(chǔ)的性能,還可以保持良好的向上兼容性。
磁盤陣列(RAID)是指將多臺(tái)硬盤通過RAID控制器(軟件或硬件控制器)組合成虛擬單臺(tái)大容量硬盤的使用,通過資源冗余來提供各種服務(wù)質(zhì)量。例如,將多個(gè)獨(dú)立的磁盤組織成一個(gè)邏輯盤,提供更大的存儲(chǔ)容量;通過數(shù)據(jù)分割、多通道并行來提高數(shù)據(jù)的I/O速率;通過保存冗余的數(shù)據(jù)、校驗(yàn)信息來提高存儲(chǔ)系統(tǒng)的可靠性等。使用多磁盤的RAID技術(shù)將大大提高存儲(chǔ)容量、存儲(chǔ)速率以及可靠性。
2 光纖采集卡的設(shè)計(jì)
2.1 光纖采集卡概述
光纖采集卡是記錄儀的核心部分。板卡是基于Xilinx公司的一款Virtex5系列FPGA芯片XC5VLX50T進(jìn)行開發(fā)的,遵循VITA42.3 XMC PCI Express規(guī)范所定義的尺寸形狀和機(jī)械結(jié)構(gòu),使用Samtec公司的標(biāo)準(zhǔn)XMC連接器ASP-105885與COM Express載板之間進(jìn)行互連通信。板卡主要由光纖接口模塊、DDR2高速緩存模塊、PCIE接口模塊、電源管理模塊、時(shí)鐘管理模塊和復(fù)位電路組成,其系統(tǒng)框圖如圖2所示。
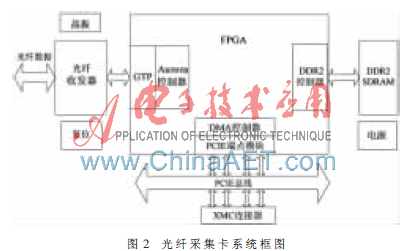
2.2 光纖接口設(shè)計(jì)
光纖模塊采用FINISAR公司的FTLF1321 SFP高速收發(fā)器。光纖采集的工作流程是:光纖收發(fā)器接收數(shù)據(jù)并進(jìn)行光電轉(zhuǎn)換,然后將串行的數(shù)據(jù)傳輸?shù)紽PGA的Rocket IO硬核進(jìn)行串并轉(zhuǎn)換,最后將并行的數(shù)據(jù)存儲(chǔ)到FPGA的內(nèi)部FIFO中。為了增加數(shù)據(jù)的可靠性、降低誤碼率,以及匹配收發(fā)雙發(fā)的速率,需要引入流控、數(shù)據(jù)管理和編解碼的機(jī)制,因此,設(shè)計(jì)使用了Xilinx公司免費(fèi)提供的Aurora協(xié)議對(duì)光纖通道進(jìn)行驅(qū)動(dòng)和管理。Aurora協(xié)議是一種簡(jiǎn)潔、輕量級(jí)、可裁剪的通信協(xié)議,使用非常靈活,占用系統(tǒng)資源少,并且可以擴(kuò)展多路光纖通道。
2.3 DDR2高速緩存設(shè)計(jì)
由于數(shù)據(jù)采集系統(tǒng)都是實(shí)時(shí)系統(tǒng),所采集的數(shù)據(jù)持續(xù)地送往記錄儀,而Windows操作系統(tǒng)的非實(shí)時(shí)性、內(nèi)核調(diào)度以及多線程操作的不可預(yù)知性,導(dǎo)致可能出現(xiàn)數(shù)據(jù)丟失。因此,為了保證記錄儀的可靠性并減輕處理器模塊的緩存壓力,應(yīng)在光纖采集卡上設(shè)計(jì)容量大、快速存取能力的緩存裝置。板卡選用了2片Micron公司的MT47H128M16B型號(hào)的DDR2 SDRAM進(jìn)行高速緩存。該芯片采用1.8 V核電壓,最高支持667 MHz時(shí)鐘頻率。本設(shè)計(jì)采用Xilinx公司的內(nèi)存管理生成器IP核MIG3.1來開發(fā)DDR2控制器,完成FPGA對(duì)DDR2的控制。DDR2控制器在管理數(shù)據(jù)高速緩存的同時(shí),還需要管理與PCIE總線控制模塊的DMA傳輸中斷請(qǐng)求。
2.4 PCIE總線控制邏輯設(shè)計(jì)
PCIE總線控制邏輯是光纖采集卡的難點(diǎn)。由于XC5VLX50T器件內(nèi)嵌了PCIE endpoint block(端點(diǎn)模塊),該IP核實(shí)現(xiàn)了PCIE總線的完整功能,因此可以選用FPGA的PCIE endpoint block硬核和Rocket IO硬核來實(shí)現(xiàn)PCIE協(xié)議的物理層、鏈路層和傳輸層的功能[5]。PCIE總線與處理器的交互可以通過PIO或DMA兩種方式進(jìn)行。PCIE硬核本身只包含了PIO的功能模塊,而PIO模式需要CPU的參與,因此會(huì)影響到CPU的運(yùn)行效率。為滿足數(shù)據(jù)實(shí)時(shí)高速的存儲(chǔ),自行設(shè)計(jì)了DMA控制器來完成DMA功能。PCIE協(xié)議規(guī)定,PCIE的事務(wù)可分為四種:存儲(chǔ)器事務(wù)、IO事務(wù)、配置事務(wù)和消息事務(wù)。事務(wù)的執(zhí)行或者完成由發(fā)送和接收事務(wù)包(TLP)具體實(shí)現(xiàn),也即PCIE端點(diǎn)與CPU之間通過TLP進(jìn)行通信。本設(shè)計(jì)中主要需要使用的TLP包括:存儲(chǔ)器讀TLP(MRd)、存儲(chǔ)器寫請(qǐng)求TLP(MWr)和帶數(shù)據(jù)的完成TLP(CplD)。因此PCIE總線控制邏輯的重點(diǎn)是PCIE事務(wù)包的構(gòu)建與解析、中斷的管理以及DMA傳輸?shù)目刂啤MA控制邏輯框圖如圖3所示。

圖3中主要模塊功能如下:
(1)DMA狀態(tài)/控制寄存器模塊主要負(fù)責(zé)板卡狀態(tài)的管理、DMA傳輸?shù)墓芾硪约爸袛嘈盘?hào)的部分管理。在例化PCIE endpoint block硬核時(shí),向系統(tǒng)申請(qǐng)128 B的BAR0存儲(chǔ)器空間來存放這些寄存器,主要的寄存器如表1所示。板卡驅(qū)動(dòng)加載后,CPU會(huì)讀取StutasReg寄存器來察看板卡的狀態(tài),如果光纖鏈路或者PCIE鏈路出現(xiàn)故障,模塊負(fù)責(zé)給出相應(yīng)的故障指示信號(hào)。如果板卡狀態(tài)正常,CPU會(huì)向CtrlReg寄存器寫入DMA傳輸?shù)牡刂泛烷L(zhǎng)度信息,向IntReg寄存器寫入相應(yīng)中斷的使能標(biāo)志。

(2)數(shù)據(jù)發(fā)射機(jī)模塊負(fù)責(zé)從數(shù)據(jù)準(zhǔn)備模塊讀取數(shù)據(jù),構(gòu)建MRd、MWr、CplD事務(wù)包,并且發(fā)送到endpoint block。數(shù)據(jù)準(zhǔn)備模塊所組織的數(shù)據(jù)來自于發(fā)送 FIFO或者DMA 狀態(tài)/控制寄存器。
(3)數(shù)據(jù)接收模塊負(fù)責(zé)從endpoint block接收并解析MRd、MWr、CplD事務(wù)包,將接收到的數(shù)據(jù)存儲(chǔ)到接收 FIFO、DMA 狀態(tài)/控制寄存器,或者通知數(shù)據(jù)發(fā)射機(jī)模塊構(gòu)建相應(yīng)的CplD事務(wù)包。
(4)中斷管理模塊負(fù)責(zé)中斷信號(hào)的產(chǎn)生、清除、復(fù)位,主要管理了四種類型的中斷:DMA讀中斷請(qǐng)求、DMA讀完成中斷請(qǐng)求、DMA寫中斷請(qǐng)求和DMA寫完成中斷請(qǐng)求。其中,DMA中斷讀/寫請(qǐng)求由DDR2控制器給出,用于通知CPU光纖采集卡中空余的緩沖空間/緩存的數(shù)據(jù)量足以達(dá)到一次讀/寫DMA傳輸?shù)拈L(zhǎng)度;DMA讀/寫完成中斷由中斷管理模塊給出,用于通知CPU此次讀/寫DMA傳輸已經(jīng)完成。
一次寫DMA數(shù)據(jù)傳輸?shù)牧鞒倘缦拢?1)DDR2緩存模塊對(duì)光纖接收的數(shù)據(jù)進(jìn)行緩存,當(dāng)緩存的數(shù)據(jù)量達(dá)到設(shè)定的閾值以后向中斷管理模塊發(fā)出DMA寫中斷請(qǐng)求。中斷管理模塊將這個(gè)中斷傳遞到endpoint block,經(jīng)PCIE鏈路去中斷CPU,同時(shí)寫IntReg寄存器記錄本次中斷的類型。(2)CPU收到中斷后發(fā)起一個(gè)存儲(chǔ)器讀事務(wù),讀取IntReg寄存器的相應(yīng)位。經(jīng)過判斷是DMA寫中斷請(qǐng)求以后,向CtrlReg寄存器發(fā)起一個(gè)存儲(chǔ)器寫事務(wù)來啟動(dòng)DMA傳輸。同時(shí)CPU向IntReg寄存器發(fā)起存儲(chǔ)器寫事務(wù)來關(guān)閉DMA寫中斷,打開DMA完成寫中斷。(3)DMA啟動(dòng)以后,CPU就不用參與數(shù)據(jù)的傳輸了,剩下的傳輸工作交給DMA控制器完成。數(shù)據(jù)的寫DMA傳輸實(shí)質(zhì)上就是DMA控制邏輯不斷地向板卡驅(qū)動(dòng)的DMA緩沖區(qū)發(fā)存儲(chǔ)器寫TLP。每發(fā)送一個(gè)TLP,DMA的傳輸長(zhǎng)度值就會(huì)減去上次TLP數(shù)據(jù)的長(zhǎng)度,一直減到零為止。(4)當(dāng)DMA傳輸結(jié)束以后,中斷管理器會(huì)向CPU發(fā)送DMA寫完成中斷,同時(shí)再次寫IntReg寄存器記錄本次中斷的類型。(5)CPU收到并判斷這個(gè)中斷后,會(huì)通知應(yīng)用程序讀取收到的數(shù)據(jù)進(jìn)行存盤,同時(shí)打開DMA寫中斷,關(guān)閉DMA寫完成中斷,等待下一次的寫DMA傳輸。
3 系統(tǒng)調(diào)試與性能測(cè)試
為驗(yàn)證系統(tǒng)設(shè)計(jì)的DMA傳輸符合Xilinx的PCI Express endpoint block IP核所規(guī)定的時(shí)序以及SATA存儲(chǔ)的性能,搭建了一個(gè)記錄儀存儲(chǔ)測(cè)試平臺(tái)。該平臺(tái)由信號(hào)處理機(jī)通過光纖向記錄儀發(fā)送以32 bit字長(zhǎng)遞增的數(shù)據(jù)進(jìn)行存儲(chǔ)。FPGA的硬件邏輯在Xilinx集成開發(fā)環(huán)境ISE11.2下進(jìn)行,因此可以使用在線邏輯分析儀ChipScope捕捉到如圖4所示的DMA傳輸時(shí)序圖。

從圖4可以看出,在trn_sof_n和trn_eof_n的兩個(gè)低電平之間就是PCIE總線傳輸?shù)?個(gè)TLP,完全符合endpoint block IP核的時(shí)序要求,驗(yàn)證了DMA的邏輯設(shè)計(jì)。
在完成了數(shù)據(jù)從采集卡DMA傳輸?shù)津?qū)動(dòng)程序緩沖區(qū)的操作后,由應(yīng)用程序完成從驅(qū)動(dòng)中提取數(shù)據(jù)并且進(jìn)行寫磁盤的操作。最后通過Matlab程序?qū)Υ姹P數(shù)據(jù)的讀取校驗(yàn),驗(yàn)證了記錄儀所記錄數(shù)據(jù)的正確性。表2給出了在不同單次DMA長(zhǎng)度和單次存盤長(zhǎng)度下的平均存盤速率的影響。

從表2可以看出,該記錄儀的存儲(chǔ)速率受單次存盤數(shù)據(jù)長(zhǎng)度的影響較大,受單次DMA長(zhǎng)度影響相對(duì)較小。其原因是:(1)PCIE的數(shù)據(jù)傳輸速率遠(yuǎn)大于數(shù)據(jù)的存盤速率;(2)非實(shí)時(shí)操作系統(tǒng)軟件開銷較大,對(duì)相同大小的數(shù)據(jù)量進(jìn)行操作的次數(shù)越多,所花費(fèi)的時(shí)間就越長(zhǎng)。因此,使用時(shí)應(yīng)該盡量增大單次存盤的數(shù)據(jù)長(zhǎng)度,以提高記錄儀的存儲(chǔ)性能。
本文實(shí)現(xiàn)了一種基于COM Express架構(gòu)的新型記錄儀的設(shè)計(jì),該設(shè)計(jì)主要完成了光纖數(shù)據(jù)的高速采集、與處理器模塊之間的DMA傳輸以及對(duì)數(shù)據(jù)的高速存儲(chǔ)。實(shí)際應(yīng)用表明,該記錄儀與傳統(tǒng)的記錄儀相比較,在穩(wěn)定性和存儲(chǔ)速率方面都得到了極大的提升,可以很好地勝任未來聲納數(shù)據(jù)的采集存儲(chǔ)的需要。而且由于COM Express是一種開放的架構(gòu),提供了許多主流的高速接口,可以靈活地?cái)U(kuò)展其他的功能模塊,給嵌入式設(shè)計(jì)也提供了一種新的思路。
參考文獻(xiàn)
[1] Kontron Corporation.ETXexpress-PC user′s guide.http:// www.kontron.com,2009.
[2] PEBLY B.COM Express:the next generation computer on module standard.Principal system engineer[M].Radisys Corporation,2005.
[3] 代孝森,張晉寧,沈輝.基于PCI Express總線的光纖檢測(cè)系統(tǒng)[J].現(xiàn)代雷達(dá),2011(1).
[4] 馬萍,唐衛(wèi)華,李緒志.基于PCI Express總線高速采集卡的設(shè)計(jì)與實(shí)現(xiàn)[J].微計(jì)算機(jī)信息,2008(9).
[5] 劉凱,徐欣.基于Vertex5的PCI-Express的總線接口設(shè)計(jì)[J].現(xiàn)代電子技術(shù),2008(5).