
近年來,使用GPU(通用圖形處理器)進(jìn)行科學(xué)計(jì)算已變得十分普遍。GPU最初設(shè)計(jì)用于圖像密集型視頻游戲產(chǎn)業(yè)中的圖形渲染繪制,但近年來GPU不斷發(fā)展,現(xiàn)可用于更廣泛的用途。研究人員可對其進(jìn)行程序設(shè)計(jì)以執(zhí)行計(jì)算,用于數(shù)據(jù)分析、數(shù)據(jù)可視化,以及金融和生物建模等應(yīng)用。
MATLAB的GPU支持為活躍于許多學(xué)科的大量研究人員(不一定是CUDA編程專家)提供了一種加速科學(xué)計(jì)算的新方法。考慮到MATLAB主要是用于科學(xué)計(jì)算和工程計(jì)算,因此MATLAB最新提供的GPU支持是一種邏輯開發(fā),以便讓非編程專家同樣能夠使用此技術(shù)。
有了MATLAB的這些新功能之后,用戶便可以利用GPU來實(shí)現(xiàn)其應(yīng)用程序的顯著提速,而無需進(jìn)行低級的C語言程序設(shè)計(jì)。這一最新技術(shù)發(fā)展提供了現(xiàn)有方法以外的其他方法來加速特定硬件上的MATLAB算法執(zhí)行。
使用MATLAB進(jìn)行GPU程序設(shè)計(jì)
MATLAB中的CUDA支持為GPU加速后的MATLAB操作提供了基礎(chǔ),并實(shí)現(xiàn)了現(xiàn)有CUDA內(nèi)核與MATLAB應(yīng)用程序的集成。用戶現(xiàn)在可以使用不同的程序設(shè)計(jì)技術(shù)來實(shí)現(xiàn)易用性與執(zhí)行優(yōu)化兩者的適當(dāng)平衡(參考文獻(xiàn)1)。
MATLAB支持啟用了CUDA的NVIDIA GPU(具有1.3或更高版本計(jì)算功能),例如Tesla 10系列和基于Fermi架構(gòu)的尖端Tesla 20系列。GPU 1.3版提供的雙浮點(diǎn)精度全面支持是保證大多數(shù)科學(xué)計(jì)算不因速度權(quán)衡而損失精度(loss Svb)的先決條件,并且可以將代碼更改的需要減到最低。
在MATLAB中實(shí)現(xiàn)GPU計(jì)算的三種方法加速了整個(gè)應(yīng)用程序的進(jìn)度,并實(shí)現(xiàn)了所需的建模復(fù)雜度與執(zhí)行控制間的權(quán)衡方案。
在GPU上執(zhí)行重載的MATLAB函數(shù)
最簡單的編程模式包括對GPU(GPU數(shù)組)上已加載數(shù)據(jù)的MATLAB函數(shù)直接調(diào)用。用戶可以決定何時(shí)在MATLAB工作區(qū)和GPU之間移動(dòng)數(shù)據(jù)或創(chuàng)建存儲(chǔ)在GPU內(nèi)存中的數(shù)據(jù),以盡可能減少主機(jī)與設(shè)備間數(shù)據(jù)傳輸?shù)拈_銷。在第一個(gè)版本中,已重載了超過100個(gè)MATLAB函數(shù)(包括FFT和矩陣除法),以在GPU數(shù)組中無縫執(zhí)行。用戶可在同一函數(shù)調(diào)用中將在GPU上加載的數(shù)據(jù)和MATLAB工作區(qū)中的數(shù)據(jù)混合,以實(shí)現(xiàn)最優(yōu)的靈活性與易用性。
這種方法提供了一個(gè)簡單的接口,讓用戶可以在GPU上直接執(zhí)行標(biāo)準(zhǔn)函數(shù),從而獲得性能提升,而無需花費(fèi)任何時(shí)間開發(fā)專門的代碼。

MATLAB代碼示例1,在GPU上執(zhí)行矩陣除法
當(dāng)處理存儲(chǔ)在GPU內(nèi)存中的數(shù)據(jù)時(shí),會(huì)重載 \ 操作符以便在GPU上運(yùn)行。在這種情況下,用戶不得對函數(shù)進(jìn)行任何更改,只能指定何時(shí)從GPU內(nèi)存移動(dòng)和檢索數(shù)據(jù),這兩種操作分別通過gpuArray和gather命令來完成。
在MATLAB中定義GPU內(nèi)核
作為第二種編程模式,用戶可以定義MATLAB函數(shù),執(zhí)行要對GPU上的向量化數(shù)據(jù)執(zhí)行的標(biāo)量算術(shù)運(yùn)算。使用這種方法,用戶可以擴(kuò)展和自定義在GPU上執(zhí)行的函數(shù)集,以構(gòu)建復(fù)雜應(yīng)用程序并實(shí)現(xiàn)性能加速,因?yàn)樾枰M(jìn)行的內(nèi)核調(diào)用和數(shù)據(jù)傳輸比以前少。
這種編程模式允許用算術(shù)方法定義要在GPU上執(zhí)行的復(fù)雜內(nèi)核,只需使用MATLAB語言即可。使用這種方法,可在GPU上執(zhí)行復(fù)雜的算術(shù)運(yùn)算,充分利用數(shù)據(jù)并行化并最小化與內(nèi)核調(diào)用和數(shù)據(jù)傳輸有關(guān)的開銷。
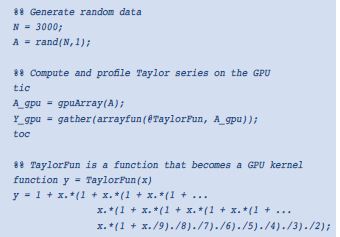
MATLAB代碼示例2,將MATLAB函數(shù)定義為GPU內(nèi)核
同樣,在這種情況下,用戶不得對函數(shù)進(jìn)行任何更改,只能指定何時(shí)從GPU內(nèi)存移動(dòng)和檢索數(shù)據(jù)以及使用arrayfun命令調(diào)用函數(shù)。TaylorFun函數(shù)會(huì)在A_gpu矢量的各個(gè)元素上執(zhí)行,充分利用數(shù)據(jù)并行化。
直接從MATLAB調(diào)用CUDA代碼
為了進(jìn)一步擴(kuò)展在GPU上執(zhí)行的集合函數(shù),可以從CUDA或PTX代碼中創(chuàng)建一個(gè)MATLAB可調(diào)用的GPU內(nèi)核。第三種編程模式可以讓用戶輕松地從MATLAB直接調(diào)用已有CUDA代碼,使非CUDA專家同樣能夠進(jìn)行代碼重用。
這種編程模式同樣有助于CUDA開發(fā)人員的工作,因?yàn)樗峁┝酥苯訌腗ATLAB進(jìn)行CUDA代碼測試的整體解決方案,無需使用GPU在環(huán)配置進(jìn)行基于文件的數(shù)據(jù)交換。此外,用戶還可以直接從MATLAB試用有關(guān)線程塊大小和共享內(nèi)存的參數(shù)。
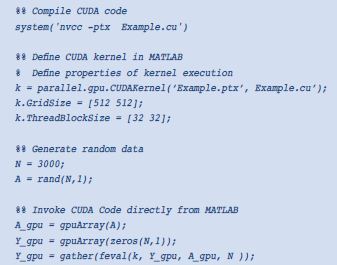
MATLAB代碼示例3,直接從MATLAB調(diào)用CUDA代碼
對于精通CUDA的程序員而言,這種方法可實(shí)現(xiàn)輕松混合串行與高度并行代碼的可能,從而獲得最優(yōu)的性能,而無需開發(fā)整個(gè)應(yīng)用程序的C語言代碼。
在編譯代碼并生成ptx文件之后,用戶可向MATLAB聲明該內(nèi)核,設(shè)置有關(guān)線程塊大小的屬性,并直接對數(shù)據(jù)調(diào)用內(nèi)核。同樣,在這種情況下,用戶可以決定何時(shí)在主機(jī)內(nèi)存與設(shè)備之間移動(dòng)數(shù)據(jù),以盡可能減少數(shù)據(jù)傳輸?shù)拈_銷。
GPU和CPU間的執(zhí)行權(quán)衡
相比多核處理器,GPU可顯著地加速高度并行操作的執(zhí)行。實(shí)踐證明,GPU的大規(guī)模并行體系結(jié)構(gòu)有助于從金融計(jì)算到分子動(dòng)力學(xué)等許多領(lǐng)域的密集科學(xué)計(jì)算。通過將計(jì)算密集型內(nèi)核映射到GPU并在CPU上運(yùn)行應(yīng)用程序的順序部分,可以將整體執(zhí)行加速5倍到超過100倍(參考文獻(xiàn)2)。
MATLAB GPU支持可以通過無縫方式為大規(guī)模并行復(fù)雜應(yīng)用程序提速,而不損失精度。通過支持1.3或更高版本的CUDA,MathWorks解決方案可完全實(shí)現(xiàn)GPU上的雙浮點(diǎn)精度計(jì)算,從而保證不因任何速度權(quán)衡而損失精度。
可使用GPU實(shí)現(xiàn)的加速主要取決于主機(jī)內(nèi)存和GPU設(shè)備間數(shù)據(jù)傳輸?shù)拈_銷。計(jì)算密集型并行應(yīng)用程序可減少數(shù)據(jù)傳輸量,將能體驗(yàn)更快的程序執(zhí)行。同樣,以上考慮明顯適用于在GPU上執(zhí)行的MATLAB應(yīng)用程序(參見圖 1)。
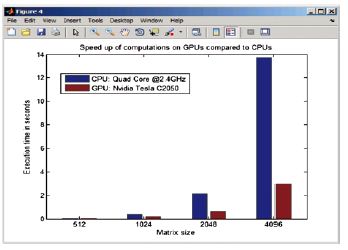
圖1,使用雙浮點(diǎn)精度實(shí)現(xiàn)矩陣除法的計(jì)算加速見MATLAB代碼示例1所述。注意:對于小型矩陣而言,設(shè)備與主機(jī)間的數(shù)據(jù)傳輸開銷是最主要的,因此可能不會(huì)發(fā)生任何加速,或者GPU上的程序執(zhí)行甚至可能會(huì)比在CPU上的執(zhí)行還要慢
根據(jù)計(jì)算復(fù)雜度和并行程度的不同,在所有GPU和CPU上執(zhí)行復(fù)雜應(yīng)用程序時(shí),可以體驗(yàn)到最佳的加速效果。這視程序員的經(jīng)驗(yàn)和水平而異,要看他是否能確定最佳的執(zhí)行平臺(tái)。基于這些原因,很難估計(jì)使用GPU可獲得的最大加速效果。根據(jù)可用的硬件平臺(tái)和應(yīng)用程序的復(fù)雜性,程序員可以使用MATLAB配置代碼以實(shí)現(xiàn)最快執(zhí)行,并作出目標(biāo)平臺(tái)的最佳選擇(圖2)。

圖2,計(jì)算不同內(nèi)核大小的泰勒級數(shù)所需的執(zhí)行時(shí)間見MATLAB代碼示例2所述。注意:當(dāng)在四核處理器上執(zhí)行該函數(shù)時(shí),MATLAB隱式多線程已對其進(jìn)行了加速,無需修改應(yīng)用程序代碼。當(dāng)計(jì)算加速大于數(shù)據(jù)傳輸?shù)拈_銷時(shí),GPU對復(fù)雜函數(shù)更有幫助。GPU計(jì)算時(shí)間幾乎與內(nèi)核復(fù)雜度無關(guān)
結(jié)論
為了實(shí)現(xiàn)GPU的最大靈活性和易用性,MathWorks提供了不同的編程模式來更好地滿足開發(fā)人員的偏好。有了MATLAB GPU支持,用戶便可以一種無縫且不費(fèi)力的方式加速其應(yīng)用程序。此外,GPU支持已集成在Parallel Computing Toolbox中,因此可以對所有具有并行性的應(yīng)用程序進(jìn)行加速,無論其位于GPU上還是CPU上,并可最終擴(kuò)展到集群。因此,MATLAB GPU支持只需最少的編程工作,便可將 MATLAB的任務(wù)與數(shù)據(jù)并行化功能擴(kuò)展到更多硬件平臺(tái)。