
摘 要: 提出了一種基于Adaboost算法和CART算法結(jié)合的分類算法。以特征為節(jié)點(diǎn)生成CART二叉樹,用CART二叉樹代替?zhèn)鹘y(tǒng)Adaboost算法中的弱分類器,再由這些弱分類器生成強(qiáng)分類器。將強(qiáng)分類器對數(shù)字樣本和人臉樣本分類,與傳統(tǒng)Adaboost算法相比,該方法的錯誤率分別減少20%和86.5%。將分類器應(yīng)用于目標(biāo)檢測上,實(shí)現(xiàn)了對這兩種目標(biāo)的快速檢測和定位。結(jié)果表明,改進(jìn)算法既減小了對樣本分類的錯誤率,又保持了傳統(tǒng)Adboost算法對目標(biāo)檢測的快速性。
關(guān)鍵詞: Adaboost;CART;數(shù)據(jù)挖掘;目標(biāo)識別;模式分類
數(shù)據(jù)挖掘是從大量的數(shù)據(jù)中提取出隱含有用信息的過程[1]。分類是數(shù)據(jù)挖掘的一種重要形式,在分類算法中,Adaboost算法和CART(Classification and Regression Tree)算法在對數(shù)據(jù)的分類中都有著重要的作用。Adaboost算法是一種迭代算法,其核心思想是針對同一個分類集訓(xùn)練不同的弱分類器,然后把這些弱分類器結(jié)合起來形成一個強(qiáng)分類器進(jìn)而實(shí)現(xiàn)對數(shù)據(jù)分類,其分類速度快、精度高。2001年,由VIOLA P和JONES M將該算法應(yīng)用于人臉定位[2],算法開始得到快速的發(fā)展。此后,LIENHART R和MAYDT J又用此算法成功實(shí)現(xiàn)了對不同方位人臉的檢測[3]。決策樹算法最早是由HUNT等人于1966年提出的CLS(Concept Learning System)。當(dāng)前,最有影響的決策樹算法是QUINLAN于1986年提出的ID3和1993年提出的C4.5。CART算法是基于以上兩種方法的改進(jìn)算法,它采用一種二分遞歸分割的技術(shù),將當(dāng)前的樣本集分為兩個子樣本集,使得生成的決策樹的每個非葉子節(jié)點(diǎn)都有兩個分支。因此,CART算法生成的決策樹是結(jié)構(gòu)簡潔的二叉樹[4],比ID3和C4.5算法具有更好的抗噪聲性能。
本算法是基于以上兩種算法的改進(jìn)算法,在算法的訓(xùn)練過程中,用CART算法生成的二叉樹代替?zhèn)鹘y(tǒng)Adaboost算法中的弱分類器,然后級聯(lián)成最終的強(qiáng)分類器,最后通過以實(shí)驗(yàn)驗(yàn)證了該算法的可靠性。實(shí)驗(yàn)分別以數(shù)字圖像和人臉圖像為樣本,訓(xùn)練生成分類器,再分別對若干張測試樣本分類并計算出分類誤差及誤差減小率。在目標(biāo)檢測的實(shí)驗(yàn)上,比較了改進(jìn)算法和傳統(tǒng)Adaboost算法的優(yōu)越性,兩種算法都能完全檢測到目標(biāo),且耗時相當(dāng)。
1 Adaboost和CART算法
1.1 Adaboost算法
Adaboost算法的訓(xùn)練過程就是找出若干個弱分類器[5]。設(shè)n個弱分類器(h1,h2,…,hn)是由相同的學(xué)習(xí)算法形成的,每個弱分類器能單獨(dú)對未知樣本分類成正樣本或負(fù)樣本(二分類情況),通過加權(quán)統(tǒng)計弱分類器的分類結(jié)果得出最終的分類結(jié)果。選擇弱分類器的過程中,只要求分類器對樣本的分類能力大于自然選擇就可以了,即分類錯誤率小于0.5。凡是分類錯誤率低于0.5的分類器都可以作為弱分類器,但在實(shí)際的訓(xùn)練過程中,還是選擇錯誤率最低的分類器作為該輪選擇的弱分類器,表示如下:

特征為矩形圖像中白色區(qū)域內(nèi)的像素總和減去黑色區(qū)域的像素總和,它反映了白色區(qū)域到黑色區(qū)域的梯度變化情況。
試驗(yàn)中對特征的提取一般都是基于特征圖的,特征圖可以使計算量大大減少。積分圖就是對要處理的圖像二次積分,表示如下:

1.1.2 特征生成
特征生成即是將樣本圖像表示成矢量的形式。以24×24樣本圖為例,生成積分圖之后,選擇有效的Haar-Like特征模板,在積分圖中移動,并保存特征值。當(dāng)一次移動完之后,改變模板大小繼續(xù)移動取特征值,然后將所有特征按先后順序排列成一維向量成為代表樣本的特征向量。由于模板是在積分圖上移動的,因此,每次只需要知道模板的4個頂點(diǎn)坐標(biāo)就可以通過加減法輕松計算出特征值。生成的特征數(shù)量相對較多,參考文獻(xiàn)[3]具體分析了每個模板對應(yīng)的特征的個數(shù)及其計算公式,統(tǒng)計了所有模板在24×24圖像上移動生成的特征總數(shù)為117 941個,即以117 941維的矢量表示一個樣本圖。
1.2 CART算法
CART算法是決策樹的一種,所不同的是,它的分支始終是二分的。用變量y表示分類結(jié)果,用X表示p維特征,該算法首先找出p維特征中對分類有效的某個特征x,將樣本分成兩個本集子樣,以樹的左右枝表示,并將此特征作為根節(jié)點(diǎn)。接下來判斷左右子樣本集是否只包含純樣本(全部正樣本或全部負(fù)樣本),如果是,則將此樣本集定義為葉子;否則,再次在此子樣本集中找出有效特征,繼續(xù)將子樣本集空間劃分成左右枝,直到被劃分的子樣本集中只包含純樣本為止。在同一等級的節(jié)點(diǎn)中,可以選取相同屬性的特征作為節(jié)點(diǎn),這個劃分是以遞歸方式實(shí)現(xiàn)的,最終形成一棵二叉樹,形狀如圖3所示。
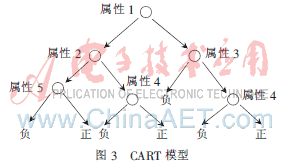
從根節(jié)點(diǎn)到每一個葉子節(jié)點(diǎn),都對應(yīng)一個規(guī)則。分類時,將待測樣本的對應(yīng)特征逐一在此樹上從上到下搜索,直到葉子節(jié)點(diǎn),此時,就將該樣本的屬性劃分為該葉節(jié)點(diǎn)所表征的類(正樣本或負(fù)樣本)。
在決策樹的分支中,常用的分支準(zhǔn)則為信息熵法和信息增益法。其中,信息熵是ID3算法中常用的分支方法,而信息增益法主要是C4.5和CART中常用的分支方法。
信息熵本為通信電路攜帶信息量的大小,在這里反映的是某一個特征閾值對樣本的劃分準(zhǔn)確率。對于訓(xùn)練例集U,假設(shè)有m個類別,全局信息熵表示為:

由于噪聲的存在,決策樹往往出現(xiàn)枝葉過于茂盛或者樹干過長的情況,在分類的過程中,這會導(dǎo)致對訓(xùn)練數(shù)據(jù)過度擬合,使分類的錯誤率升高,反而不能對驗(yàn)證數(shù)據(jù)很好地分類。所以,一棵優(yōu)秀的決策樹應(yīng)該包含剪枝的過程,即用驗(yàn)證數(shù)據(jù)將樹的葉子或節(jié)點(diǎn)修剪,防止其對訓(xùn)練數(shù)據(jù)的過度擬合。剪枝算法有多種,常見的有前向剪枝和后向剪枝兩種,CART算法采用的是后向剪枝算法。
2 改進(jìn)算法
2.1 算法原理
Adaboost算法在每一輪的訓(xùn)練過程中都會判斷某一單獨(dú)特征對訓(xùn)練樣本的分類能力,然后加大被錯誤分類樣本的權(quán)重,減少被正確分類樣本的權(quán)重。由于權(quán)重在每一輪訓(xùn)練完成之后都在改變,因此,每次選擇的特征并不一定是最好特征,只是在當(dāng)前權(quán)值條件下分類最好的特征。為了改善弱分類器對樣本的分類能力,選擇一棵具有3個節(jié)點(diǎn)的二叉樹代替原來的弱分類器,即每輪訓(xùn)練都找出3個對分類最優(yōu)的特征,構(gòu)成一棵樹。弱分類器的分類結(jié)果由這3個特征共同決定,比起只用單獨(dú)特征分類的弱分類器而言,它對樣本的分類能力更高。由于每個弱分類器對樣本的分類能力提高了,因此,最終的強(qiáng)分類器的分類能力也將提高。為了與Adaboost算法中的弱分類器h區(qū)別,改進(jìn)算法中的弱分類器用H表示。圖4描述了本算法形成的分類器模型。

在訓(xùn)練步驟(c)中,考慮了分類錯誤率和信息熵增益兩個因素對分類的影響。算法在每一輪訓(xùn)練中都選擇了對分類錯誤率最小的3個特征,然后再從其中計算信息熵增益最大的特征作為節(jié)點(diǎn)。這樣的選擇保證了弱分類器也能有較小的分類誤差,因此最終的強(qiáng)分類器也有較小的分類誤差。
3 實(shí)驗(yàn)結(jié)果與分析
3.1 實(shí)驗(yàn)描述
為了說明改進(jìn)算法的效果,在相同條件下得出了兩種算法的實(shí)驗(yàn)結(jié)果并進(jìn)行了比較。實(shí)驗(yàn)一以人民幣圖像中的數(shù)字0作為樣本,樣本圖像均由人工采集,在不同面額的人民幣圖像上采集得到正樣本圖像和負(fù)樣本圖像各500張。實(shí)驗(yàn)二以人臉圖像作為樣本,樣本來源于AR(AR Face Database.http://cobweb.ecn.purdue.edu/~aleix/aleix_face_DB.html)人臉數(shù)據(jù)庫,正負(fù)樣本各1 000張。
實(shí)驗(yàn)均選擇以圖2(a)和圖2(b)的Haar-Like模板生成特征。實(shí)驗(yàn)過程采用交叉驗(yàn)證的方式完成,所有實(shí)驗(yàn)均在同一條件下進(jìn)行。實(shí)驗(yàn)條件:PC機(jī)采用AMD AthlonTMII x2220 2.81 GHz處理器和2 GB內(nèi)存;代碼執(zhí)行平臺為MATLAB7.0。
3.2 實(shí)驗(yàn)結(jié)果
訓(xùn)練樣本的數(shù)量越大,越能夠反映真實(shí)樣本的分布情況,在訓(xùn)練的過程中,也更能提取出對分類有效的特征。實(shí)驗(yàn)首先以數(shù)字圖像樣本為研究對象,以不同數(shù)量的樣本訓(xùn)練分類器,然后將生成的分類器對200個測試樣本分類,得到圖5。可以明顯看出,隨著訓(xùn)練樣本數(shù)量的增加,分類誤差呈現(xiàn)下降的趨勢,其下降的速率先快后慢,最后基本穩(wěn)定在某一數(shù)值。實(shí)驗(yàn)還發(fā)現(xiàn),當(dāng)訓(xùn)練樣本數(shù)量遠(yuǎn)遠(yuǎn)大于測試樣本時,能夠使測試樣本的分類誤差達(dá)到最小。試驗(yàn)中,在選取900個訓(xùn)練樣本、100個測試樣本的條件下,能夠?qū)?00個測試樣本完全分開,分類準(zhǔn)確率達(dá)到100%。

由以上實(shí)驗(yàn)結(jié)果可知,當(dāng)訓(xùn)練樣本數(shù)量高于300個時,其分類誤差基本保持在某一數(shù)值。為此,實(shí)驗(yàn)中將全部1 000個樣本分成500個訓(xùn)練樣本和500個測試樣本(訓(xùn)練樣本和測試樣本中均各含250個正樣本和負(fù)樣本),分別用傳統(tǒng)的Adabost算法和改進(jìn)算法生成強(qiáng)分類器,對測試樣本分類。圖6顯示了兩種分類器的分類誤差隨著訓(xùn)練次數(shù)的變化情況。

由圖6可以看出,隨著訓(xùn)練次數(shù)的增加,兩種分類器對測試樣本的分類誤差逐漸減小。在訓(xùn)練次數(shù)高于某個數(shù)值之后,改進(jìn)算法的錯誤率明顯低于普通的Adaboost算法,說明改進(jìn)算法的分類能力較強(qiáng)。由于實(shí)驗(yàn)中所選樣本的可分性較強(qiáng),因此,無論是傳統(tǒng)的Adaboost算法還是改進(jìn)算法,其分類誤差都比較低(小于1%)。
為了驗(yàn)證算法魯棒性,實(shí)驗(yàn)從AR人臉庫中得到正負(fù)人臉樣本各1 000張,再次比較兩種算法的分類情況,如圖7所示。從圖中可以看出,改進(jìn)算法對特征不明顯的人臉圖像分類照樣能達(dá)到較高的分類精度(99.3%),高于普通的Adaboost算法(94.8%),這說明本算法的魯棒性較強(qiáng)。

從表1可以看出,改進(jìn)算法對不同的目標(biāo)樣本分類能力均有所提高,并且提高的程度有所不同。數(shù)字樣本的Harr-like特征較明顯,所以,無論是改進(jìn)算法還是普通的Adaboost算法,分類誤差都較小,而且誤差減小率也相對較小。而從兩種算法對人臉樣本的分類可以看出,改進(jìn)算法能明顯減小分類誤差,提高分類器的分類能力。
將生成的分類器應(yīng)用于目標(biāo)檢測,能夠快速檢測出目標(biāo)在圖像中的位置。由于改進(jìn)算法的實(shí)現(xiàn)過程保留了傳統(tǒng)Adaboost算法中以Haar-Like模板提取特征的過程,因此兩種算法耗時相當(dāng)。圖8(b)和圖8(d)分別是以上生成的數(shù)字分類器和人臉分類器對兩種目標(biāo)的檢測結(jié)果。

本文以Adaboost算法和CART算法為基礎(chǔ),提出了將這兩種算法相結(jié)合的改進(jìn)算法,從理論上詳細(xì)闡述了算法的原理和步驟。算法的關(guān)鍵在于,在訓(xùn)練樣本的每一輪訓(xùn)練中尋找出對分類最有利的3個特征,形成二叉樹,用來代替?zhèn)鹘y(tǒng)Adaboost算法中的弱分類器。樹的形狀是根據(jù)CART算法改進(jìn)的,提高了單個弱分類器對樣本的分類能力,由于強(qiáng)分類器由弱分類構(gòu)成,因此,強(qiáng)分類器的分類能力也得到提高。最后以人民幣圖像上的數(shù)字0和人臉圖像為樣本,驗(yàn)證了本算法的可靠性和魯棒性。較普通的Adaboost算法而言,改進(jìn)算法對數(shù)字樣本和人臉樣本的分類誤差率分別減少20%和86.5%,說明算法對樣本的分類能力有所提高。改進(jìn)算法的每輪訓(xùn)練都要生成有3個節(jié)點(diǎn)的二叉樹,其訓(xùn)練過程將更加耗時,約等于普通算法的3倍。可以說,改進(jìn)算法是以更長的訓(xùn)練耗時換取更高的分類精確度。由于改進(jìn)算法在特征提取過程中保持了傳統(tǒng)Adaboost算法的步驟,因此兩種算法在目標(biāo)檢測的應(yīng)用中耗時是相當(dāng)?shù)摹?br />
參考文獻(xiàn)
[1] 毛國君. 數(shù)據(jù)挖掘的概念、系統(tǒng)結(jié)構(gòu)和方法[J]. 計算機(jī)工程與設(shè)計, 2002,23(8):13-17.
[2] VIOLA P, JONES M. Rapid object detection using a boosted cascade of simple features[C]. Accepted Conference on Computer Vision and Pattern Recognition, 2001(5):511-518.
[3] LIENHART R, MAYDT J. An extended set of Haar-like features for rapid object detection[C]. IEEE ICIP 2002, 2002, 1:900-903.
[4] YOHANNES Y, HODDINOTT J. Classification and regression trees: an introduction[C]. International Food Policy Research Institute 2033 K Street, N.W. Washington, D.C. 20006 U.S.A, 1999.
[5] HORE U W. Comparative implementation of colour analysis based methods for face detection algorithm[C]. Emerging Trends in Engineering and Technology (ICETET), 2010(3):176-179.
[6] LISU L. Research on face detection classifier using an improved adaboost algorithm[C]. International Symposium on Computer Science, 2009(2):199-204.
[7] FREUND Y, SCHAPIRE R E. Experiments with a new boosting algorithm[C]. Machine Learning: Proceedings of the Thirteenth International Conference, San Francisco, 1996(5):148-156.