
多核多線程已經(jīng)成為當(dāng)下一個時髦的話題,而無鎖編程更是這個時髦話題中的熱點(diǎn)話題。Linux 內(nèi)核可能是當(dāng)今最大最復(fù)雜的并行程序之一,為我們分析多核多線程提供了絕佳的范例。內(nèi)核設(shè)計者已經(jīng)將最新的無鎖編程技術(shù)帶進(jìn)了 2.6 系統(tǒng)內(nèi)核中,本文以 2.6.10 版本為藍(lán)本,帶領(lǐng)您領(lǐng)略多核多線程編程的真諦,窺探無鎖編程的奧秘 ,體味大師們的高雅設(shè)計!
非阻塞型同步 (Non-blocking Synchronization) 簡介
如何正確有效的保護(hù)共享數(shù)據(jù)是編寫并行程序必須面臨的一個難題,通常的手段就是同步。同步可分為阻塞型同步(Blocking Synchronization)和非阻塞型同步( Non-blocking Synchronization)。
阻塞型同步是指當(dāng)一個線程到達(dá)臨界區(qū)時,因另外一個線程已經(jīng)持有訪問該共享數(shù)據(jù)的鎖,從而不能獲取鎖資源而阻塞,直到另外一個線程釋放鎖。常見的同步原語有 mutex、semaphore 等。如果同步方案采用不當(dāng),就會造成死鎖(deadlock),活鎖(livelock)和優(yōu)先級反轉(zhuǎn)(priority inversion),以及效率低下等現(xiàn)象。
為了降低風(fēng)險程度和提高程序運(yùn)行效率,業(yè)界提出了不采用鎖的同步方案,依照這種設(shè)計思路設(shè)計的算法稱為非阻塞型算法,其本質(zhì)特征就是停止一個線程的執(zhí)行不會阻礙系統(tǒng)中其他執(zhí)行實(shí)體的運(yùn)行。
當(dāng)今比較流行的 Non-blocking Synchronization 實(shí)現(xiàn)方案有三種:
Wait-free
Wait-free 是指任意線程的任何操作都可以在有限步之內(nèi)結(jié)束,而不用關(guān)心其它線程的執(zhí)行速度。 Wait-free 是基于 per-thread 的,可以認(rèn)為是 starvation-free 的。非常遺憾的是實(shí)際情況并非如此,采用 Wait-free 的程序并不能保證 starvation-free,同時內(nèi)存消耗也隨線程數(shù)量而線性增長。目前只有極少數(shù)的非阻塞算法實(shí)現(xiàn)了這一點(diǎn)。
Lock-free
Lock-Free 是指能夠確保執(zhí)行它的所有線程中至少有一個能夠繼續(xù)往下執(zhí)行。由于每個線程不是 starvation-free 的,即有些線程可能會被任意地延遲,然而在每一步都至少有一個線程能夠往下執(zhí)行,因此系統(tǒng)作為一個整體是在持續(xù)執(zhí)行的,可以認(rèn)為是 system-wide 的。所有 Wait-free 的算法都是 Lock-Free 的。
Obstruction-free
Obstruction-free 是指在任何時間點(diǎn),一個孤立運(yùn)行線程的每一個操作可以在有限步之內(nèi)結(jié)束。只要沒有競爭,線程就可以持續(xù)運(yùn)行。一旦共享數(shù)據(jù)被修改,Obstruction-free 要求中止已經(jīng)完成的部分操作,并進(jìn)行回滾。 所有 Lock-Free 的算法都是 Obstruction-free 的。
綜上所述,不難得出 Obstruction-free 是 Non-blocking synchronization 中性能最差的,而 Wait-free 性能是最好的,但實(shí)現(xiàn)難度也是最大的,因此 Lock-free 算法開始被重視,并廣泛運(yùn)用于當(dāng)今正在運(yùn)行的程序中,比如 linux 內(nèi)核。
一般采用原子級的 read-modify-write 原語來實(shí)現(xiàn) Lock-Free 算法,其中 LL 和 SC 是 Lock-Free 理論研究領(lǐng)域的理想原語,但實(shí)現(xiàn)這些原語需要 CPU 指令的支持,非常遺憾的是目前沒有任何 CPU 直接實(shí)現(xiàn)了 SC 原語。根據(jù)此理論,業(yè)界在原子操作的基礎(chǔ)上提出了著名的 CAS(Compare - And - Swap)操作來實(shí)現(xiàn) Lock-Free 算法,Intel 實(shí)現(xiàn)了一條類似該操作的指令:cmpxchg8。
CAS 原語負(fù)責(zé)將某處內(nèi)存地址的值(1 個字節(jié))與一個期望值進(jìn)行比較,如果相等,則將該內(nèi)存地址處的值替換為新值,CAS 操作偽碼描述如下:
清單 1. CAS 偽碼
Bool CAS(T* addr, T expected, T newValue)
{
if( *addr == expected )
{
*addr = newValue;
return true;
}
else
return false;
}
在實(shí)際開發(fā)過程中,利用 CAS 進(jìn)行同步,代碼如下所示:
清單 2. CAS 實(shí)際操作
do{
備份舊數(shù)據(jù);
基于舊數(shù)據(jù)構(gòu)造新數(shù)據(jù);
}while(!CAS( 內(nèi)存地址,備份的舊數(shù)據(jù),新數(shù)據(jù) ))
就是指當(dāng)兩者進(jìn)行比較時,如果相等,則證明共享數(shù)據(jù)沒有被修改,替換成新值,然后繼續(xù)往下運(yùn)行;如果不相等,說明共享數(shù)據(jù)已經(jīng)被修改,放棄已經(jīng)所做的操作,然后重新執(zhí)行剛才的操作。容易看出 CAS 操作是基于共享數(shù)據(jù)不會被修改的假設(shè),采用了類似于數(shù)據(jù)庫的 commit-retry 的模式。當(dāng)同步?jīng)_突出現(xiàn)的機(jī)會很少時,這種假設(shè)能帶來較大的性能提升。
加鎖的層級
根據(jù)復(fù)雜程度、加鎖粒度及運(yùn)行速度,可以得出如下圖所示的鎖層級:
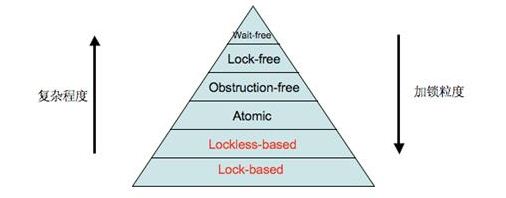
圖 1. 加鎖層級
其中標(biāo)注為紅色字體的方案為 Blocking synchronization,黑色字體為 Non-blocking synchronization。Lock-based 和 Lockless-based 兩者之間的區(qū)別僅僅是加鎖粒度的不同。圖中最底層的方案就是大家經(jīng)常使用的 mutex 和 semaphore 等方案,代碼復(fù)雜度低,但運(yùn)行效率也最低。
Linux 內(nèi)核中的無鎖分析
Linux 內(nèi)核可能是當(dāng)今最大最復(fù)雜的并行程序之一,它的并行主要來至于中斷、內(nèi)核搶占及 SMP 等。內(nèi)核設(shè)計者們?yōu)榱瞬粩嗵岣?Linux 內(nèi)核的效率,從全局著眼,逐步廢棄了大內(nèi)核鎖來降低鎖的粒度;從細(xì)處下手,不斷對局部代碼進(jìn)行優(yōu)化,用無鎖編程替代基于鎖的方案,如 seqlock 及 RCU 等;不斷減少鎖沖突程度、降低等待時間,如 Double-checked locking 和原子鎖等。
無論什么時候當(dāng)臨界區(qū)中的代碼僅僅需要加鎖一次,同時當(dāng)其獲取鎖的時候必須是線程安全的,此時就可以利用 Double-checked Locking 模式來減少鎖競爭和加鎖載荷。目前 Double-checked Locking 已經(jīng)廣泛應(yīng)用于單例 (Singleton) 模式中。內(nèi)核設(shè)計者基于此思想,巧妙的將 Double-checked Locking 方法運(yùn)用于內(nèi)核代碼中。
當(dāng)一個進(jìn)程已經(jīng)僵死,即進(jìn)程處于 TASK_ZOMBIE 狀態(tài),如果父進(jìn)程調(diào)用 waitpid() 系統(tǒng)調(diào)用時,父進(jìn)程需要為子進(jìn)程做一些清理性的工作,代碼如下所示:
清單 3. 少鎖操作
984 static int wait_task_zombie(task_t *p, int noreap,
985 struct siginfo __user *infop,
986 int __user *stat_addr, struct rusage __user *ru)
987 {
……
1103 if (p->real_parent != p->parent) {
1104 write_lock_irq(&tasklist_lock);
1105 /* Double-check with lock held. */
1106 if (p->real_parent != p->parent) {
1107 __ptrace_unlink(p);
1108 // TODO: is this safe?
1109 p->exit_state = EXIT_ZOMBIE;
……
1120 }
1121 write_unlock_irq(&tasklist_lock);
1122 }
……
1127 }
如果將 write_lock_irq 放置于 1103 行之前,鎖的范圍過大,鎖的負(fù)載也會加重,影響效率;如果將加鎖的代碼放到判斷里面,且沒有 1106 行的代碼,程序會正確嗎?在單核情況下是正確的,但在雙核情況下問題就出現(xiàn)了。一個非主進(jìn)程在一個 CPU 上運(yùn)行,正準(zhǔn)備調(diào)用 exit 退出,此時主進(jìn)程在另外一個 CPU 上運(yùn)行,在子進(jìn)程調(diào)用 release_task 函數(shù)之前調(diào)用上述代碼。子進(jìn)程在 exit_notify 函數(shù)中,先持有讀寫鎖 tasklist_lock,調(diào)用 forget_original_parent。主進(jìn)程運(yùn)行到 1104 處,由于此時子進(jìn)程先持有該鎖,所以父進(jìn)程只好等待。在 forget_original_parent 函數(shù)中,如果該子進(jìn)程還有子進(jìn)程,則會調(diào)用 reparent_thread(),將執(zhí)行 p->parent = p->real_parent; 語句,導(dǎo)致兩者相等,等非主進(jìn)程釋放讀寫鎖 tasklist_lock 時,另外一個 CPU 上的主進(jìn)程被喚醒,一旦開始執(zhí)行,繼續(xù)運(yùn)行將會導(dǎo)致 bug。
嚴(yán)格的說,Double-checked locking 不屬于無鎖編程的范疇,但由原來的每次加鎖訪問到大多數(shù)情況下無須加鎖,就是一個巨大的進(jìn)步。同時從這里也可以看出一點(diǎn)端倪,內(nèi)核開發(fā)者為了降低鎖沖突率,減少等待時間,提高運(yùn)行效率,一直在持續(xù)不斷的進(jìn)行改進(jìn)。
原子操作可以保證指令以原子的方式執(zhí)行——執(zhí)行過程不被打斷。內(nèi)核提供了兩組原子操作接口:一組針對于整數(shù)進(jìn)行操作,另外一組針對于單獨(dú)的位進(jìn)行操作。內(nèi)核中的原子操作通常是內(nèi)聯(lián)函數(shù),一般是通過內(nèi)嵌匯編指令來完成。對于一些簡單的需求,例如全局統(tǒng)計、引用計數(shù)等等,可以歸結(jié)為是對整數(shù)的原子計算。
1. Lock-free 應(yīng)用場景一 —— Spin Lock
Spin Lock 是一種輕量級的同步方法,一種非阻塞鎖。當(dāng) lock 操作被阻塞時,并不是把自己掛到一個等待隊列,而是死循環(huán) CPU 空轉(zhuǎn)等待其他線程釋放鎖。 Spin lock 鎖實(shí)現(xiàn)代碼如下:
清單 4. spin lock 實(shí)現(xiàn)代碼
static inline void __preempt_spin_lock(spinlock_t *lock)
{
……
do {
preempt_enable();
while (spin_is_locked(lock))
cpu_relax();
preempt_disable();
} while (!_raw_spin_trylock(lock));
}
static inline int _raw_spin_trylock(spinlock_t *lock)
{
char oldval;
__asm__ __volatile__(
"xchgb %b0,%1"
:"=q" (oldval), "=m" (lock->lock)
:"0" (0) : "memory");
return oldval > 0;
}
匯編語言指令 xchgb 原子性的交換 8 位 oldval( 存 0) 和 lock->lock 的值,如果 oldval 為 1(lock 初始值為 1),則獲取鎖成功,反之,則繼續(xù)循環(huán),接著 relax 休息一會兒,然后繼續(xù)周而復(fù)始,直到成功。
對于應(yīng)用程序來說,希望任何時候都能獲取到鎖,也就是期望 lock->lock 為 1,那么用 CAS 原語來描述 _raw_spin_trylock(lock) 就是 CAS(lock->lock,1,0);
如果同步操作總是能在數(shù)條指令內(nèi)完成,那么使用 Spin Lock 會比傳統(tǒng)的 mutex lock 快一個數(shù)量級。Spin Lock 多用于多核系統(tǒng)中,適合于鎖持有時間小于將一個線程阻塞和喚醒所需時間的場合。
pthread 庫已經(jīng)提供了對 spin lock 的支持,所以用戶態(tài)程序也能很方便的使用 spin lock 了,需要包含 pthread.h 。在某些場景下,pthread_spin_lock 效率是 pthread_mutex_lock 效率的一倍多。美中不足的是,內(nèi)核實(shí)現(xiàn)了讀寫 spin lock 鎖,但 pthread 未能實(shí)現(xiàn)。
2. Lock -free 應(yīng)用場景二 —— Seqlock
手表最主要最常用的功能是讀時間,而不是校正時間,一旦后者成了最常用的功能,消費(fèi)者肯定不會買賬。計算機(jī)的時鐘也是這個功能,修改時間是小概率事件,而讀時間是經(jīng)常發(fā)生的行為。以下代碼摘自 2.4.34 內(nèi)核:
清單 5. 2.4.34 seqlock 實(shí)現(xiàn)代碼
443 void do_gettimeofday(struct timeval *tv)
444 {
……
448 read_lock_irqsave(&xtime_lock, flags);
……
455 sec = xtime.tv_sec;
456 usec += xtime.tv_usec;
457 read_unlock_irqrestore(&xtime_lock, flags);
……
466 }
468 void do_settimeofday(struct timeval *tv)
469 {
470 write_lock_irq(&xtime_lock);
……
490 write_unlock_irq(&xtime_lock);
491 }
不難發(fā)現(xiàn)獲取時間和修改時間采用的是 spin lock 讀寫鎖,讀鎖和寫鎖具有相同的優(yōu)先級,只要讀持有鎖,寫鎖就必須等待,反之亦然。
Linux 2.6 內(nèi)核中引入一種新型鎖——順序鎖 (seqlock),它與 spin lock 讀寫鎖非常相似,只是它為寫者賦予了較高的優(yōu)先級。也就是說,即使讀者正在讀的時候也允許寫者繼續(xù)運(yùn)行。當(dāng)存在多個讀者和少數(shù)寫者共享一把鎖時,seqlock 便有了用武之地,因為 seqlock 對寫者更有利,只要沒有其他寫者,寫鎖總能獲取成功。根據(jù) lock-free 和時鐘功能的思想,內(nèi)核開發(fā)者在 2.6 內(nèi)核中,將上述讀寫鎖修改成了順序鎖 seqlock,代碼如下:
清單 6. 2.6.10 seqlock 實(shí)現(xiàn)代碼
static inline unsigned read_seqbegin(const seqlock_t *sl)
{
unsigned ret = sl->sequence;
smp_rmb();
return ret;
}
static inline int read_seqretry(const seqlock_t *sl, unsigned iv)
{
smp_rmb();
return (iv & 1) | (sl->sequence ^ iv);
}
static inline void write_seqlock(seqlock_t *sl)
{
spin_lock(&sl->lock);
++sl->sequence;
smp_wmb();
}
void do_gettimeofday(struct timeval *tv)
{
unsigned long seq;
unsigned long usec, sec;
unsigned long max_ntp_tick;
……
do {
unsigned long lost;
seq = read_seqbegin(&xtime_lock);
……
sec = xtime.tv_sec;
usec += (xtime.tv_nsec / 1000);
} while (read_seqretry(&xtime_lock, seq));
……
tv->tv_sec = sec;
tv->tv_usec = usec;
}
int do_settimeofday(struct timespec *tv)
{
……
write_seqlock_irq(&xtime_lock);
……
write_sequnlock_irq(&xtime_lock);
clock_was_set();
return 0;
}
Seqlock 實(shí)現(xiàn)原理是依賴一個序列計數(shù)器,當(dāng)寫者寫入數(shù)據(jù)時,會得到一把鎖,并且將序列值加 1。當(dāng)讀者讀取數(shù)據(jù)之前和之后,該序列號都會被讀取,如果讀取的序列號值都相同,則表明寫沒有發(fā)生。反之,表明發(fā)生過寫事件,則放棄已進(jìn)行的操作,重新循環(huán)一次,直至成功。不難看出,do_gettimeofday 函數(shù)里面的 while 循環(huán)和接下來的兩行賦值操作就是 CAS 操作。
采用順序鎖 seqlock 好處就是寫者永遠(yuǎn)不會等待,缺點(diǎn)就是有些時候讀者不得不反復(fù)多次讀相同的數(shù)據(jù)直到它獲得有效的副本。當(dāng)要保護(hù)的臨界區(qū)很小,很簡單,頻繁讀取而寫入很少發(fā)生(WRRM--- Write Rarely Read Mostly)且必須快速時,就可以使用 seqlock。但 seqlock 不能保護(hù)包含有指針的數(shù)據(jù)結(jié)構(gòu),因為當(dāng)寫者修改數(shù)據(jù)結(jié)構(gòu)時,讀者可能會訪問一個無效的指針。
3. Lock -free 應(yīng)用場景三 —— RCU
在 2.6 內(nèi)核中,開發(fā)者還引入了一種新的無鎖機(jī)制 -RCU(Read-Copy-Update),允許多個讀者和寫者并發(fā)執(zhí)行。RCU 技術(shù)的核心是寫操作分為寫和更新兩步,允許讀操作在任何時候無阻礙的運(yùn)行,換句話說,就是通過延遲寫來提高同步性能。RCU 主要應(yīng)用于 WRRM 場景,但它對可保護(hù)的數(shù)據(jù)結(jié)構(gòu)做了一些限定:RCU 只保護(hù)被動態(tài)分配并通過指針引用的數(shù)據(jù)結(jié)構(gòu),同時讀寫控制路徑不能有睡眠。以下數(shù)組動態(tài)增長代碼摘自 2.4.34 內(nèi)核:
清單 7. 2.4.34 RCU 實(shí)現(xiàn)代碼
其中 ipc_lock 是讀者,grow_ary 是寫者,不論是讀或者寫,都需要加 spin lock 對被保護(hù)的數(shù)據(jù)結(jié)構(gòu)進(jìn)行訪問。改變數(shù)組大小是小概率事件,而讀取是大概率事件,同時被保護(hù)的數(shù)據(jù)結(jié)構(gòu)是指針,滿足 RCU 運(yùn)用場景。以下代碼摘自 2.6.10 內(nèi)核:
清單 8. 2.6.10 RCU 實(shí)現(xiàn)代碼
#define rcu_read_lock() preempt_disable()
#define rcu_read_unlock() preempt_enable()
#define rcu_assign_pointer(p, v) ({ \
smp_wmb(); \
(p) = (v); \
})
struct kern_ipc_perm* ipc_lock(struct ipc_ids* ids, int id)
{
……
rcu_read_lock();
entries = rcu_dereference(ids->entries);
if(lid >= entries->size) {
rcu_read_unlock();
return NULL;
}
out = entries->p[lid];
if(out == NULL) {
rcu_read_unlock();
return NULL;
}
……
return out;
}
static int grow_ary(struct ipc_ids* ids, int newsize)
{
struct ipc_id_ary* new;
struct ipc_id_ary* old;
……
new = ipc_rcu_alloc(sizeof(struct kern_ipc_perm *)*newsize +
sizeof(struct ipc_id_ary));
if(new == NULL)
return size;
new->size = newsize;
memcpy(new->p, ids->entries->p, sizeof(struct kern_ipc_perm *)*size
+sizeof(struct ipc_id_ary));
for(i=size;i
}
old = ids->entries;
/*
* Use rcu_assign_pointer() to make sure the memcpyed contents
* of the new array are visible before the new array becomes visible.
*/
rcu_assign_pointer(ids->entries, new);
ipc_rcu_putref(old);
return newsize;
}
縱觀整個流程,寫者除內(nèi)核屏障外,幾乎沒有一把鎖。當(dāng)寫者需要更新數(shù)據(jù)結(jié)構(gòu)時,首先復(fù)制該數(shù)據(jù)結(jié)構(gòu),申請 new 內(nèi)存,然后對副本進(jìn)行修改,調(diào)用 memcpy 將原數(shù)組的內(nèi)容拷貝到 new 中,同時對擴(kuò)大的那部分賦新值,修改完畢后,寫者調(diào)用 rcu_assign_pointer 修改相關(guān)數(shù)據(jù)結(jié)構(gòu)的指針,使之指向被修改后的新副本,整個寫操作一氣呵成,其中修改指針值的操作屬于原子操作。在數(shù)據(jù)結(jié)構(gòu)被寫者修改后,需要調(diào)用內(nèi)存屏障 smp_wmb,讓其他 CPU 知曉已更新的指針值,否則會導(dǎo)致 SMP 環(huán)境下的 bug。當(dāng)所有潛在的讀者都執(zhí)行完成后,調(diào)用 call_rcu 釋放舊副本。同 Spin lock 一樣,RCU 同步技術(shù)主要適用于 SMP 環(huán)境。
環(huán)形緩沖區(qū)是生產(chǎn)者和消費(fèi)者模型中常用的數(shù)據(jù)結(jié)構(gòu)。生產(chǎn)者將數(shù)據(jù)放入數(shù)組的尾端,而消費(fèi)者從數(shù)組的另一端移走數(shù)據(jù),當(dāng)達(dá)到數(shù)組的尾部時,生產(chǎn)者繞回到數(shù)組的頭部。
如果只有一個生產(chǎn)者和一個消費(fèi)者,那么就可以做到免鎖訪問環(huán)形緩沖區(qū)(Ring Buffer)。寫入索引只允許生產(chǎn)者訪問并修改,只要寫入者在更新索引之前將新的值保存到緩沖區(qū)中,則讀者將始終看到一致的數(shù)據(jù)結(jié)構(gòu)。同理,讀取索引也只允許消費(fèi)者訪問并修改。
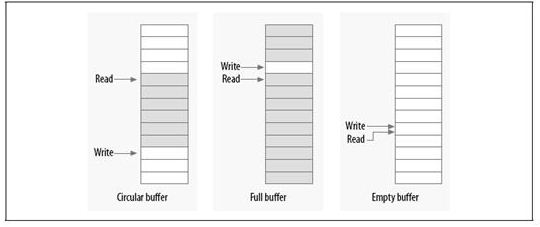
圖 2. 環(huán)形緩沖區(qū)實(shí)現(xiàn)原理圖
如圖所示,當(dāng)讀者和寫者指針相等時,表明緩沖區(qū)是空的,而只要寫入指針在讀取指針后面時,表明緩沖區(qū)已滿。
清單 9. 2.6.10 環(huán)形緩沖區(qū)實(shí)現(xiàn)代碼
/*
* __kfifo_put - puts some data into the FIFO, no locking version
* Note that with only one concurrent reader and one concurrent
* writer, you don't need extra locking to use these functions.
*/
unsigned int __kfifo_put(struct kfifo *fifo,
unsigned char *buffer, unsigned int len)
{
unsigned int l;
len = min(len, fifo->size - fifo->in + fifo->out);
/* first put the data starting from fifo->in to buffer end */
l = min(len, fifo->size - (fifo->in & (fifo->size - 1)));
memcpy(fifo->buffer + (fifo->in & (fifo->size - 1)), buffer, l);
/* then put the rest (if any) at the beginning of the buffer */
memcpy(fifo->buffer, buffer + l, len - l);
fifo->in += len;
return len;
}
/*
* __kfifo_get - gets some data from the FIFO, no locking version
* Note that with only one concurrent reader and one concurrent
* writer, you don't need extra locking to use these functions.
*/
unsigned int __kfifo_get(struct kfifo *fifo,
unsigned char *buffer, unsigned int len)
{
unsigned int l;
len = min(len, fifo->in - fifo->out);
/* first get the data from fifo->out until the end of the buffer */
l = min(len, fifo->size - (fifo->out & (fifo->size - 1)));
memcpy(buffer, fifo->buffer + (fifo->out & (fifo->size - 1)), l);
/* then get the rest (if any) from the beginning of the buffer */
memcpy(buffer + l, fifo->buffer, len - l);
fifo->out += len;
return len;
}
以上代碼摘自 2.6.10 內(nèi)核,通過代碼的注釋(斜體部分)可以看出,當(dāng)只有一個消費(fèi)者和一個生產(chǎn)者時,可以不用添加任何額外的鎖,就能達(dá)到對共享數(shù)據(jù)的訪問。
總結(jié)
通過對比 2.4 和 2.6 內(nèi)核代碼,不得不佩服內(nèi)核開發(fā)者的智慧,為了提高內(nèi)核性能,一直不斷的進(jìn)行各種優(yōu)化,并將業(yè)界最新的 lock-free 理念運(yùn)用到內(nèi)核中。
在實(shí)際開發(fā)過程中,進(jìn)行無鎖設(shè)計時,首先進(jìn)行場景分析,因為每種無鎖方案都有特定的應(yīng)用場景,接著根據(jù)場景分析進(jìn)行數(shù)據(jù)結(jié)構(gòu)的初步設(shè)計,然后根據(jù)先前的分析結(jié)果進(jìn)行并發(fā)模型建模,最后在調(diào)整數(shù)據(jù)結(jié)構(gòu)的設(shè)計,以便達(dá)到最優(yōu)。