
摘 要: 最大匹配算法是中文分詞中最常用的方法,但其有著過(guò)分依賴(lài)于詞典的弊端。對(duì)最大匹配算法進(jìn)行了深入探討與研究,使用n-gram技術(shù)更新詞典解決其弊端,從而提高分詞效果。最后通過(guò)雙向匹配算法與n-gram相結(jié)合的實(shí)驗(yàn)驗(yàn)證了該方案的可行性,并對(duì)該方案進(jìn)行了總結(jié)。
關(guān)鍵詞: 中文分詞;最大匹配;n-gram;詞頻;雙向匹配
作為計(jì)算機(jī)信息處理中最基礎(chǔ)、最關(guān)鍵的技術(shù),中文分詞一直是人們研究的熱點(diǎn)。中文分詞就是將連續(xù)的漢字序列按照一定的規(guī)律分割成一個(gè)個(gè)單獨(dú)的詞的過(guò)程[1]。在英文句子中,單詞之間是以空格作為自然分界符的,所以英文分詞比較簡(jiǎn)單;而中文以字為基本單位,將一序列字串聯(lián)在一起形成句子,從而表達(dá)意思,中文的句和段能通過(guò)明顯的分界符來(lái)劃分,但是詞沒(méi)有一個(gè)形式上的分界符,所以中文分詞比英文分詞相對(duì)困難許多。中文分詞方法總結(jié)起來(lái)大致可分為三大類(lèi):基于詞典直接匹配的分詞方法、基于規(guī)則和理解的分詞方法和基于統(tǒng)計(jì)模型的分詞方法[2]。本文主要討論基于詞典匹配算法中的最大匹配算法,針對(duì)其過(guò)分依賴(lài)詞典這一弊端進(jìn)行了探討并提出了對(duì)策。
1 最大匹配算法
最大匹配算法是最常用也是最基本的字符串匹配算法之一。它能夠保證切分出來(lái)的詞長(zhǎng)度最大,同時(shí)易于實(shí)現(xiàn)[3]。最大匹配算法包括正向最大匹配算法、逆向最大匹配算法和雙向最大匹配算法。
1.1 正向最大匹配算法
正向最大匹配算法流程[4]如圖1所示。
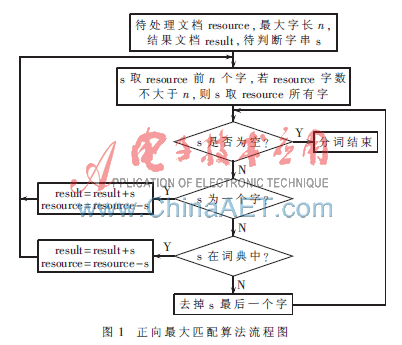
以“中華人民共和國(guó)簡(jiǎn)稱(chēng)中國(guó)”為例,設(shè)定取詞長(zhǎng)度n為8,待匹配字符串為s,按照上述步驟處理過(guò)程為:
(1)s為“中華人民共和國(guó)簡(jiǎn)”,查找詞典進(jìn)行匹配操作,發(fā)現(xiàn)沒(méi)有該詞;
(2)s去掉最后一個(gè)字,變?yōu)?ldquo;中華人民共和國(guó)”,查找詞典進(jìn)行匹配操作,發(fā)現(xiàn)該詞,將該詞存入結(jié)果文檔中;
(3)更新s,發(fā)現(xiàn)剩余的字“簡(jiǎn)稱(chēng)中國(guó)”長(zhǎng)度不足8,所以s為“簡(jiǎn)稱(chēng)中國(guó)”,查找詞典進(jìn)行匹配操作,發(fā)現(xiàn)沒(méi)有該詞;
(4)s去掉最后一個(gè)字,變?yōu)?ldquo;簡(jiǎn)稱(chēng)中”,查找詞典進(jìn)行匹配操作,發(fā)現(xiàn)沒(méi)有該詞;
(5)s去掉最后一個(gè)字,變?yōu)?ldquo;簡(jiǎn)稱(chēng)”,查找詞典進(jìn)行匹配操作,發(fā)現(xiàn)該詞,將其存入結(jié)果文檔中;
(6)更新s,發(fā)現(xiàn)剩余的字“中國(guó)”長(zhǎng)度不足8,所以s為“中國(guó)”,查找詞典進(jìn)行匹配操作,發(fā)現(xiàn)該詞,將其存入結(jié)果文檔中;
(7)更新s,發(fā)現(xiàn)s為空,至此分詞操作結(jié)束。
分詞結(jié)果為“中華人民共和國(guó)/簡(jiǎn)稱(chēng)/中國(guó)”。
1.2 逆向最大匹配算法
逆向最大匹配算法與正向最大匹配算法流程相似[5],只是取詞操作與待匹配字串更新操作不同。逆向最大匹配算法從文檔末尾開(kāi)始進(jìn)行取詞,匹配不成功刪除的是待匹配字符串的第一個(gè)字而不是最后一個(gè)。
1.3 雙向最大匹配算法
將正向最大匹配算法與逆向最大匹配算法相結(jié)合所產(chǎn)生的算法即是雙向最大匹配算法,它能夠選取正向最大匹配算法和逆向最大匹配算法中分詞效果較好的一方,以提高分詞效果。
1.4 最大匹配算法的問(wèn)題
最大匹配算法存在以下問(wèn)題:(1)待匹配字符串最大長(zhǎng)度的設(shè)定困難,過(guò)長(zhǎng)易造成效率低,過(guò)短則造成分詞不精確;(2)對(duì)詞典依賴(lài)程度過(guò)大,分詞效果取決于詞典。
2 n-gram技術(shù)
隨著時(shí)間推移,肯定有大量新詞產(chǎn)生。為了豐富詞典,本實(shí)驗(yàn)采用n-gram技術(shù)擴(kuò)充詞典。n-gram就是對(duì)一個(gè)字序列進(jìn)行分割,分割產(chǎn)生的字符串是該字序列的子串[6]。例如:對(duì)“中華人民共和國(guó)簡(jiǎn)稱(chēng)中國(guó)”進(jìn)行n-gram 2元切分,得到2元組:中華|華人|人民|民共|共和|和國(guó)|國(guó)簡(jiǎn)|簡(jiǎn)稱(chēng)|稱(chēng)中|中國(guó)。
本實(shí)驗(yàn)中,n-gram擴(kuò)充詞典步驟[7]如下:
(1)選擇語(yǔ)料庫(kù),本次實(shí)驗(yàn)選擇2010年10月14日~18日參考消息作為預(yù)料庫(kù);
(2)對(duì)語(yǔ)料庫(kù)進(jìn)行預(yù)處理,將數(shù)字、標(biāo)點(diǎn)、字母等全部刪掉,只剩下漢字;
(3)進(jìn)行切分并統(tǒng)計(jì)詞頻,本次實(shí)驗(yàn)最大詞長(zhǎng)為8,所以切分為2元組至8元組,詞頻統(tǒng)計(jì)如表1所示。

(4)選取候選詞。如圖2所示,根據(jù)觀察,當(dāng)設(shè)置使用詞頻大于5的詞作為候選詞時(shí),可靠性較高。所以本次實(shí)驗(yàn)設(shè)定候選詞的詞頻數(shù)大于5。

(5)使用候選詞對(duì)詞典進(jìn)行更新。
3 實(shí)驗(yàn)
為了提高分詞效果,本次實(shí)驗(yàn)采用雙向匹配算法同時(shí)使用n-gram技術(shù)來(lái)負(fù)責(zé)詞典的更新操作。
由于逆向最大匹配算法比正向最大匹配算法有更高的精度[8],所以本次實(shí)驗(yàn)中雙向匹配算法的選擇策略是:當(dāng)正向最大匹配分詞所分出的詞數(shù)小于逆向最大匹配算法所分出的詞數(shù)時(shí),分詞結(jié)果采用正向最大匹配所得結(jié)果;否則使用逆向最大匹配算法所得結(jié)果。
本次實(shí)驗(yàn)代碼采用java編寫(xiě),分詞算法中使用的方法主要有:(1)public StringBuffer result(String s,Set<String> dic)。用一個(gè)StringBuffer來(lái)存儲(chǔ)結(jié)果,并返回。參數(shù)s表示從待分詞文檔中讀到的行字符串,dic表示詞典。(2)public void segment(String max,String s, Set<String> dic)。參數(shù)max表示待匹配字符串。(3)public void n_gram()。n_gram的實(shí)現(xiàn),主要使用HashMap<String,Integer>,其中String用來(lái)存儲(chǔ)詞,Integer存儲(chǔ)詞頻。
在未進(jìn)行詞典更新操作之前,對(duì)“胡錦濤提出了科學(xué)發(fā)展觀”進(jìn)行分詞操作得到的結(jié)果是“胡錦濤/提出/了/科學(xué)發(fā)展/觀”;進(jìn)行詞典更新之后,“科學(xué)發(fā)展觀”成為單獨(dú)一詞,結(jié)果為“胡錦濤/提出/了/科學(xué)發(fā)展觀”,說(shuō)明使用n-gram對(duì)詞典進(jìn)行更新的確能起到提高分詞效果的作用。
本文首先對(duì)最大匹配算法進(jìn)行了詳細(xì)的闡述,繼而提出最大匹配算法的不足之處,即對(duì)詞典依賴(lài)程度過(guò)大,詞典的好壞直接決定了分詞的質(zhì)量。為解決該問(wèn)題,提出使用n-gram技術(shù)來(lái)進(jìn)行詞典的自我更新,提高詞典質(zhì)量,從而提高最大匹配算法分詞效果。通過(guò)實(shí)驗(yàn)驗(yàn)證了該方法的可行性。但是仍有不足之處:第一是對(duì)用來(lái)更新詞典的語(yǔ)料庫(kù)要求較高,語(yǔ)料庫(kù)必須具有代表性,能包含當(dāng)前社會(huì)所使用的主流詞語(yǔ);其次語(yǔ)料庫(kù)必須足夠大才能得到更好的效果;再次更新詞典對(duì)計(jì)算機(jī)性能消耗較大,必須選擇合理的時(shí)間進(jìn)行更新操作。
參考文獻(xiàn)
[1] 周宏宇,張政.中文分詞技術(shù)綜述[J].安陽(yáng)師范學(xué)院學(xué)報(bào),2010(2):54-56.
[2] 劉春輝.基于優(yōu)化最大匹配的中文分詞方法研究[D].秦皇島:燕山大學(xué),2009.
[3] 林浩,韓冰,楊樂(lè)華.一種基于改進(jìn)最大匹配快速中文分詞算法[J].科技創(chuàng)新導(dǎo)報(bào),2009(9):248.
[4] 趙源.基于最大匹配的中文分詞改進(jìn)算法研究[J].科技信息,2010(35):487,496.
[5] 王瑞雷,欒靜,潘曉花,等.一種改進(jìn)的中文分詞正向最大匹配算法[J].計(jì)算機(jī)應(yīng)用與軟件,2011,28(3):195-197.
[6] 吳勝遠(yuǎn).一種漢語(yǔ)分詞方法[J].計(jì)算機(jī)研究與發(fā)展,1996,33(4):306-311.
[7] 李文,洪親,滕忠堅(jiān),等.基于n-gram的字符串分割技術(shù)的算法實(shí)現(xiàn)[J].計(jì)算機(jī)與現(xiàn)代化,2010(9):85-87.
[8] 張磊,張代遠(yuǎn).中文分詞算法解析[J].電腦知識(shí)與技術(shù),2009,5(1):192-193.