
摘 要: 介紹操作系統(tǒng)內(nèi)核對(duì)實(shí)時(shí)性能的影響,結(jié)合NT技術(shù),分析信號(hào)量機(jī)制下線程等待隊(duì)列的排隊(duì)策略,提出一種新排隊(duì)策略,并在NT內(nèi)核中實(shí)現(xiàn)該策略,最后對(duì)比幾種策略的實(shí)驗(yàn)數(shù)據(jù)。
關(guān)鍵詞: 實(shí)時(shí)操作系統(tǒng);信號(hào)量;FIFO;LIFO;Priority;NT內(nèi)核
1 操作系統(tǒng)對(duì)實(shí)時(shí)性能的影響
操作系統(tǒng)從誕生發(fā)展到現(xiàn)代經(jīng)歷了批處理系統(tǒng)、分時(shí)系統(tǒng)和實(shí)時(shí)系統(tǒng)等演進(jìn)過(guò)程,具有多樣化特征,派生出不同分支。其中,實(shí)時(shí)性是操作系統(tǒng)的重要特性,它要求在規(guī)定的時(shí)間窗口內(nèi)邏輯正確地完成規(guī)定的任務(wù),具有及時(shí)性、交互性、多路性、獨(dú)立性等特點(diǎn)[1]。操作系統(tǒng)的實(shí)時(shí)性主要取決于I/O管理中的異步方式、內(nèi)存管理中的頁(yè)中斷機(jī)制、線程管理中的內(nèi)核代碼是否可搶占、資源管理中的信號(hào)量策略以及中斷延遲和時(shí)鐘精度等硬件支撐結(jié)構(gòu)[2]。由于多線程系統(tǒng)中線程對(duì)公共資源的爭(zhēng)奪,資源的有效管理成為提升系統(tǒng)實(shí)時(shí)性能的重要因素,而信號(hào)量是管理公共資源的經(jīng)典方式,所以,信號(hào)量設(shè)計(jì)是影響系統(tǒng)實(shí)時(shí)性的基礎(chǔ)設(shè)計(jì)。本文重點(diǎn)論述信號(hào)量策略對(duì)實(shí)時(shí)性能的影響,并以NT內(nèi)核為研究對(duì)象和實(shí)現(xiàn)平臺(tái),分析現(xiàn)有幾種信號(hào)量策略的優(yōu)、缺點(diǎn),提出了一種新策略,在保證系統(tǒng)通用性前提下提升了系統(tǒng)實(shí)時(shí)性。
2 信號(hào)量策略對(duì)實(shí)時(shí)性能的影響
荷蘭科學(xué)家設(shè)計(jì)的信號(hào)量算法為線程使用共享資源提供了有效的同步和互斥機(jī)制,NT內(nèi)核中,信號(hào)量(KSEMAPHORE)通過(guò)封裝DISPATCHER_HEADER結(jié)構(gòu)實(shí)現(xiàn)計(jì)數(shù)器和等待隊(duì)列,其數(shù)據(jù)結(jié)構(gòu)struct _KSEMA-PHORE{DISPATCHER_HEADER Header LONG Limit}在參考文獻(xiàn)[3]中有詳細(xì)描述,上述結(jié)構(gòu)可簡(jiǎn)略為:
struct _KSEMAPHORE{LONG SignalState //信號(hào)量
計(jì)數(shù)器變量
LIST_ENTRY WaitList} //線程等待隊(duì)列鏈表
它的操作有創(chuàng)建(CreateSemaphore)、刪除(CloseHandle)、請(qǐng)求(WaitForSingleObject)和釋放(ReleaseSemaphore)信號(hào)量等。
線程使用資源前需要請(qǐng)求保護(hù)該資源的信號(hào)量,若信號(hào)量計(jì)數(shù)器減1后小于0,內(nèi)核阻塞線程并將其排在信號(hào)量的線程等待隊(duì)列中,同時(shí)啟動(dòng)線程調(diào)度程序?qū)⒂?jì)算資源交給等待運(yùn)行的線程,執(zhí)行請(qǐng)求操作的線程沒(méi)有陷入“忙等”,而是“讓權(quán)等待”。若擁有信號(hào)量的線程釋放資源使得計(jì)數(shù)器加1后還小于等于0,則喚醒線程等待隊(duì)列中的等待線程并送線程調(diào)度隊(duì)列。因此,在資源緊張情況下,請(qǐng)求和釋放信號(hào)量會(huì)涉及資源等待隊(duì)列和線程調(diào)度隊(duì)列兩個(gè)隊(duì)列。本文討論資源等待隊(duì)列,對(duì)于資源請(qǐng)求,采用什么策略將線程放入隊(duì)列;對(duì)于資源釋放,采用什么策略把線程從隊(duì)列中取出并放入調(diào)度隊(duì)列。考慮放入與取出線程時(shí)同時(shí)采用策略的復(fù)雜性,固定取出策略從隊(duì)列頭部取出線程,請(qǐng)求時(shí)采取策略將線程放入隊(duì)列,目前有以下三種策略[1]:
(1)后進(jìn)先出LIFO(Last In First Out),線程請(qǐng)求資源后,若信號(hào)量計(jì)數(shù)器小于0,將線程排在線程等待隊(duì)列的隊(duì)頭。該策略易于實(shí)現(xiàn),線程等待隊(duì)列只需一個(gè)單鏈表即可,這種“后來(lái)先服務(wù)”的方式還可以利用CPU緩存TLB(Tanslation Lookaside Buffer)中存在的剛被掛起線程的頁(yè)表數(shù)據(jù),不必更新緩存,提高了運(yùn)行速度。但是,后進(jìn)先出方式讓最先被掛起的線程鮮有被服務(wù),若獲得資源的線程高頻率請(qǐng)求資源,會(huì)導(dǎo)致最先請(qǐng)求資源的線程由于長(zhǎng)時(shí)間處在隊(duì)尾得不到服務(wù)導(dǎo)致“餓死”(Starva-
tion),使得一些線程頻繁調(diào)度,而一些線程很少被調(diào)度。
(2)先進(jìn)先出FIFO(First In First Out),線程請(qǐng)求資源后,若信號(hào)量計(jì)數(shù)器小于0,將線程排在線程等待隊(duì)列的隊(duì)尾。該策略克服了線程的“餓死”現(xiàn)象,對(duì)資源有請(qǐng)求的線程都能公平地占有資源,請(qǐng)求隊(duì)列調(diào)度均衡化,從策略角度來(lái)看,所有線程都整齊劃一無(wú)差別。這種先來(lái)先服務(wù)的方式?jīng)]有考慮線程的其他因素,例如,對(duì)時(shí)間緊要程度的要求不同,有實(shí)時(shí)線程和一般線程之分,如果對(duì)實(shí)時(shí)線程和一般線程都采用先進(jìn)先出方式,那么實(shí)時(shí)線程的實(shí)時(shí)性將大幅降低,特別在等待隊(duì)列中已有很多線程的情況下,實(shí)時(shí)線程只有等待前面所有線程釋放信號(hào)量后才能得到調(diào)度,造成不必要的延時(shí)。信號(hào)量的數(shù)據(jù)結(jié)構(gòu)和操作也要復(fù)雜一些,需要一個(gè)隊(duì)尾指針。
(3)基于優(yōu)先級(jí)隊(duì)列Priority,線程請(qǐng)求資源后,若信號(hào)量計(jì)數(shù)器小于0,則將線程根據(jù)其優(yōu)先級(jí)排在線程等待隊(duì)列的相應(yīng)位置。該策略克服了先進(jìn)先出的均衡化調(diào)度缺點(diǎn),使優(yōu)先級(jí)高的線程始終處在隊(duì)列的隊(duì)首,搶占優(yōu)先級(jí)低的線程;線程可根據(jù)時(shí)間特性來(lái)確定它的優(yōu)先級(jí)并排隊(duì),提高了線程的實(shí)時(shí)性。然而這種方式也有其不足,優(yōu)先級(jí)低的線程始終得不到調(diào)度,同樣會(huì)導(dǎo)致“餓死”。如果系統(tǒng)中有大量線程爭(zhēng)搶稀有資源,排隊(duì)過(guò)程還會(huì)引入隊(duì)列的搜索時(shí)間。
這就需要一種策略,對(duì)于具有很強(qiáng)時(shí)效性的實(shí)時(shí)線程使用優(yōu)先級(jí)排隊(duì),對(duì)于一般線程按照先進(jìn)先出排隊(duì)。由于實(shí)時(shí)線程很少,配合哈希(Hash)表分類實(shí)時(shí)線程(如圖1虛直線上部分所示)基本不會(huì)引入搜索時(shí)間。
3 基于Priority和FIFO結(jié)合的信號(hào)量策略
針對(duì)優(yōu)先級(jí)隊(duì)列過(guò)分強(qiáng)調(diào)高優(yōu)先級(jí)線程的缺點(diǎn)和先進(jìn)先出隊(duì)列過(guò)分強(qiáng)調(diào)平均的缺點(diǎn),本文提出基于優(yōu)先級(jí)和先進(jìn)先出隊(duì)列結(jié)合的排隊(duì)策略,同時(shí)兼顧實(shí)時(shí)線程的強(qiáng)實(shí)時(shí)要求和一般線程的公平要求。
NT內(nèi)核將用戶線程以一對(duì)一方式映射到內(nèi)核中,并基于優(yōu)先級(jí)調(diào)度內(nèi)核線程,內(nèi)核將優(yōu)先級(jí)從低到高分為32級(jí),0~15級(jí)為一般線程,16~31級(jí)為實(shí)時(shí)線程。本文將這種線程調(diào)度隊(duì)列的分級(jí)方式見(jiàn)之于信號(hào)量的等待隊(duì)列,如圖1虛直線上部分所示,把線程等待隊(duì)列構(gòu)造成一個(gè)長(zhǎng)度為17、類型為L(zhǎng)IST_ENTRY的哈希(Hash)指針數(shù)組,數(shù)組1~16根據(jù)優(yōu)先級(jí)排列同一級(jí)別的實(shí)時(shí)線程,數(shù)組0根據(jù)先進(jìn)先出排列一般線程。線程請(qǐng)求資源后,若信號(hào)量計(jì)數(shù)器小于0,且線程優(yōu)先級(jí)小于16,則將該線程按照先進(jìn)先出策略排在線程等待隊(duì)列的隊(duì)尾;若線程優(yōu)先級(jí)大于等于16,則按照優(yōu)先級(jí)排列該線程。當(dāng)線程釋放資源時(shí),若信號(hào)量計(jì)數(shù)器小于0,內(nèi)核應(yīng)先從優(yōu)先級(jí)隊(duì)列中搜索掛起線程,再?gòu)南冗M(jìn)先出隊(duì)列中搜索掛起線程。

4 新信號(hào)量策略在NT內(nèi)核中的實(shí)現(xiàn)及結(jié)果分析
為了兼容操作系統(tǒng)上層軟件,本文僅修改“請(qǐng)求”函數(shù)的代碼而不改變現(xiàn)有信號(hào)量的數(shù)據(jù)結(jié)構(gòu),將圖1虛直線上部分描述的新信號(hào)量策略映射到虛直線下,把優(yōu)先級(jí)隊(duì)列和先進(jìn)先出隊(duì)列融合到一個(gè)隊(duì)列中,隊(duì)列的前半部分是優(yōu)先級(jí)隊(duì)列,由指針FLINK指定,后半部分為先進(jìn)先出隊(duì)列,由指針BLINK指定,這種復(fù)合型隊(duì)列同時(shí)具備優(yōu)先級(jí)和先進(jìn)先出隊(duì)列的優(yōu)點(diǎn),體現(xiàn)了“一個(gè)隊(duì)列兩種策略”。線程請(qǐng)求資源后,若信號(hào)量計(jì)數(shù)器小于0,且線程的優(yōu)先級(jí)小于16,按照先進(jìn)先出策略將線程排在BLINK指向的先進(jìn)先出隊(duì)列隊(duì)尾;若線程的優(yōu)先級(jí)大于等于16,則將線程按照優(yōu)先級(jí)策略在FLINK指向的優(yōu)先級(jí)隊(duì)列中搜索相應(yīng)的位置,找到小于優(yōu)先級(jí)隊(duì)列中的線程并放在該線程之后。當(dāng)線程釋放資源時(shí),若信號(hào)量計(jì)數(shù)器小于0,由于線程已經(jīng)根據(jù)策略放入恰當(dāng)?shù)奈恢茫瑑?nèi)核只需要從KSEMAPHORE→WaitList→FLINK取出第一個(gè)線程送往線程調(diào)度隊(duì)列即可。為了最小化修改范圍,用下述代碼替換內(nèi)核\base\ntos\ke\wait.c文件中KeWaitForSingleObject()函數(shù)的部分代碼以實(shí)現(xiàn)新策略:
if (KeQueryPriorityThread(Thread) < 16)
{InsertTailList(&Objectx->Header.WaitListHead,
&WaitBlock->WaitListEntry);}
else {ListHead1 = &Objectx->Header.WaitListHead;
WaitEntry1 = ListHead1->Flink;
while(WaitEntry1 != ListHead1) {
WaitBlock1 = CONTAINING_RECORD(WaitEntry1,
KWAIT_BLOCK, WaitListEntry);
if(KeQueryPriorityThread(Thread) >
KeQueryPriorityThread(WaitBlock1->Thread))
{break;}
WaitEntry1 = WaitEntry1->Flink;}
InsertTailList(WaitEntry1, &WaitBlock->
WaitListEntry);}
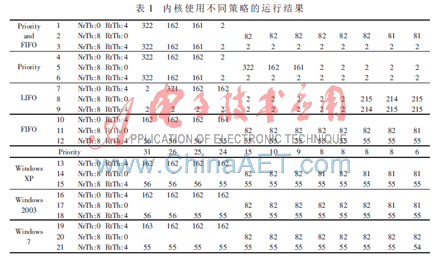
根據(jù)C規(guī)范[4]設(shè)計(jì)一個(gè)應(yīng)用程序測(cè)試內(nèi)核修改后的性能指標(biāo),由于NT內(nèi)核對(duì)于一個(gè)特定的進(jìn)程只能有一個(gè)特定的優(yōu)先級(jí)類,進(jìn)程內(nèi)的所有線程只能屬于該優(yōu)先級(jí),程序應(yīng)該第一次進(jìn)程化為實(shí)時(shí)類型的主控進(jìn)程,生成信號(hào)量和掛在信號(hào)量上的實(shí)時(shí)線程,第二次進(jìn)程化為一般類型的客戶進(jìn)程,生成掛在信號(hào)量上的一般線程,主線程釋放實(shí)時(shí)線程和一般線程。應(yīng)用程序中有4個(gè)參量:一般線程數(shù)NrTh、實(shí)時(shí)線程數(shù)RtTh;信號(hào)量Seph及資源爭(zhēng)奪時(shí)間RunT。實(shí)驗(yàn)中,固定Seph=1,RunT=10 000 ms,改變NrTh和RtTh的值,分別在表1所列的內(nèi)核上運(yùn)行,結(jié)果如表1所示。
從表1可以看出:1~12行的調(diào)度結(jié)果和前述分析的各種策略的優(yōu)缺點(diǎn)一致,對(duì)于FIFO,無(wú)論不同優(yōu)先級(jí)線程的比例是多少,它們被調(diào)度的次數(shù)幾乎完全相同。對(duì)于LIFO,從數(shù)據(jù)可以看出,兩個(gè)優(yōu)先級(jí)為8、一個(gè)優(yōu)先級(jí)為6和優(yōu)先級(jí)為26、25、24的線程處在等待隊(duì)列的前端,而且?guī)缀趺看味际沁@幾個(gè)線程被調(diào)度。對(duì)于Priority,無(wú)論是否有實(shí)時(shí)類線程,只要優(yōu)先級(jí)高,被調(diào)度的次數(shù)就多。對(duì)于新策略(Priority and FIFO),有實(shí)時(shí)線程就按優(yōu)先級(jí)調(diào)度,若只有一般線程就按照FIFO調(diào)度,既有FIFO的特性(比較第2行和第11行)也有Priority的特性(比較第1行和第4行),而其他策略則只具有一種特性。應(yīng)用程序在其他操作系統(tǒng)測(cè)試結(jié)果見(jiàn)14~22行,比較可以看出,14~22行的數(shù)據(jù)與10~12行的數(shù)據(jù)幾乎完全一致,由此可以推斷Windows 7操作系統(tǒng)的信號(hào)量等待隊(duì)列也是先進(jìn)先出策略。
研究發(fā)現(xiàn),提升系統(tǒng)實(shí)時(shí)性應(yīng)該具備兩個(gè)條件[5]:(1)不同任務(wù)可統(tǒng)一,包括將中斷任務(wù)和線程任務(wù)按不同特征統(tǒng)一映射到一個(gè)優(yōu)先級(jí)隊(duì)列中,內(nèi)核根據(jù)這個(gè)優(yōu)先級(jí)隊(duì)列統(tǒng)一調(diào)度任務(wù),中斷線程化為上述兩種任務(wù)的統(tǒng)一提供了可能;(2)所有資源可搶占,計(jì)算資源可搶占可行且易實(shí)現(xiàn),而內(nèi)存資源和I/O資源可搶占需進(jìn)一步研究,一個(gè)占有共享資源(如臨界區(qū))的低優(yōu)先級(jí)線程被一般優(yōu)先級(jí)線程搶占計(jì)算資源,而該線程又被高優(yōu)先級(jí)的線程搶占計(jì)算資源,高優(yōu)先級(jí)的線程又因請(qǐng)求已被低優(yōu)先級(jí)線程占有的資源而掛起,只有等待一般優(yōu)先級(jí)線程放棄計(jì)算資源后由低優(yōu)先級(jí)線程運(yùn)行并釋放共享資源,才能使高優(yōu)先級(jí)線程得以運(yùn)行,雖然通過(guò)優(yōu)先級(jí)繼承避免優(yōu)先級(jí)反轉(zhuǎn)可以提高實(shí)時(shí)性,但若高優(yōu)先級(jí)線程能像搶占計(jì)算資源那樣搶占線程的其他資源,實(shí)時(shí)性將大幅提升。
參考文獻(xiàn)
[1] 湯子瀛,哲鳳屏,湯小丹.計(jì)算機(jī)操作系統(tǒng)[M].西安:西安電子科技大學(xué)出版社,2001.
[2] 俸遠(yuǎn)楨,閻慧娟,羅克露.計(jì)算機(jī)組成原理[M].北京:電子工業(yè)出版社,1996.
[3] SOLOMON D A,RUSSINOVICH M E.Microsoft Windows Internals Fourth Edition[M].DigitalCopy,Microsoft Press,2004.
[4] KERNIGHAN B W,RITCHIE D M.The C programming language[M].DigitalCopy,Prentice-Hall,1988.
[5] 王波,崔喆.基于新DPC機(jī)制的實(shí)時(shí)提升技術(shù)[J].計(jì)算機(jī)應(yīng)用研究,2011,28(Z):110-111.