
摘 要:介紹了自適應(yīng)均衡器下的LMS和RLS算法的基本原理,并分析了2種算法中的忘卻因子μ對LMS和RLS算法收斂性能的影響。通過仿真可知,在相同忘卻因子下,RLS算法的收斂速度明顯快于LMS算法,并且誤差也比LMS算法小。
關(guān)鍵詞:自適應(yīng)均衡器;收斂;LMS;RLS;忘卻因子
自適應(yīng)均衡[1]屬于自適應(yīng)信號處理的應(yīng)用范疇,在過去的幾十年中,作為自適應(yīng)信號處理的應(yīng)用之一的自適應(yīng)均衡器得到了深入的研究。各種各樣的自適應(yīng)均衡算法如迫零(ZF)算法、最小均方(LMS)算法、遞歸最小二乘(RLS)算法、變換域均衡算法、Bussgang 算法、高階或循環(huán)統(tǒng)計量算法、基于非線性濾波器或神經(jīng)網(wǎng)絡(luò)的均衡算法等應(yīng)運而生。決定均衡器算法性能的因素有收斂速度、失調(diào)、計算復(fù)雜度和數(shù)值特性等。本文選擇了兩種典型的自適應(yīng)算法:以LMS自適應(yīng)均衡器和RLS自適應(yīng)均衡器為基礎(chǔ),用MATLAB 仿真軟件對LMS和RLS兩種算法進行仿真,比較并分析了兩種算法的性能。
1 自適應(yīng)均衡器
自適應(yīng)均衡器的工作過程包含兩個階段,即訓(xùn)練過程和跟蹤過程。典型的訓(xùn)練序列是偽隨機二進制信號或一個固定的波形信號序列,緊跟在訓(xùn)練序列后面的是用戶消息碼元序列。接收機的自適應(yīng)均衡器采用遞歸算法估計信道特性,調(diào)整濾波器參數(shù),補償信道特性失真,訓(xùn)練序列的選擇應(yīng)滿足接收機均衡器在最惡劣的信道估計條件下也能實現(xiàn)濾波器參數(shù)調(diào)整。所以,訓(xùn)練序列結(jié)束后,均衡器參數(shù)基本上接近最佳值,以保證用戶數(shù)據(jù)的接收,均衡器的訓(xùn)練過程成功了,成為均衡器的收斂。用戶數(shù)據(jù)序列需要被分割成數(shù)據(jù)分組或時隙分段傳送。均衡器通常工作在接收機的基帶或中頻信號部分,基帶信號的復(fù)包絡(luò)含有信道帶通信號的全部信息,所以,均衡器通常在基帶信號完成估計信道沖激響應(yīng)和解調(diào)輸出信號實現(xiàn)自適應(yīng)均衡算法等。無線通信均衡器原理簡圖如圖1所示。
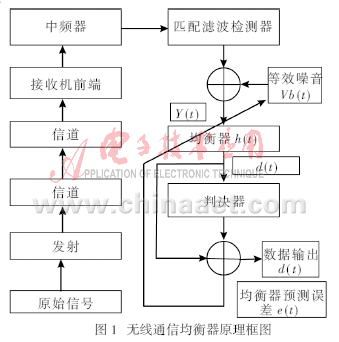
圖1中,原始信號為x(t),h(t)是發(fā)射機、無線信道和接收機射頻/中頻級合在一起的系統(tǒng)等復(fù)合濾波器的沖激響應(yīng),所以均衡器的輸入可表示為:
![]()
式中H*(t)是H(t)的復(fù)共軛,高均衡器機射頻/中頻級合在一起的系統(tǒng)等復(fù)濾波器沖激響應(yīng)。設(shè)均衡器的沖激響應(yīng)是heq(t),均衡器輸出碼元波形可表示為:
![]()
2 自適應(yīng)均衡算法
利用自適應(yīng)均衡器補償未知時變信道的特性,需要采用有效的算法跟蹤信道特性變化來更新均衡器的加權(quán)系數(shù)。而適合自適應(yīng)均衡器的算法有多種,下面就LMS 算法和RLS 算法的原理加以介紹。
2.1 基于LMS的自適應(yīng)均衡算法
LMS算法[1]采用的是最小均方誤差準則,代價函數(shù)是:

2.2 基于RLS的自適應(yīng)均衡算法
RLS算法[3]所采用的準則是最小二乘準則,其代價函數(shù)為:

3 仿真結(jié)果分析
利用MATLAB仿真工具對基于LMS和RLS的自適應(yīng)均衡算法進行相關(guān)仿真分析,進而對兩類算法的性能作比較。
為了更直觀地描述,考慮一個線性自適應(yīng)均衡器。隨機數(shù)據(jù)產(chǎn)生雙極性的隨機序列x[n],它隨機地取+1和-1。隨機信號通過一個信道傳輸,信道性質(zhì)可由一個三系數(shù)FIR濾波器刻畫,濾波器系數(shù)分別是0.3、0.9、0.3。在信道輸出加入方差為σ平方的高斯白噪聲,設(shè)計一個有11個權(quán)系數(shù)的FIR結(jié)構(gòu)的自適應(yīng)均衡器,令均衡器的期望響應(yīng)為x[n-7],選擇幾個合理的白噪聲方差σ平方(不同信噪比)[4]。
采用基于LMS和RLS的自適應(yīng)均衡算法分別進行實驗,畫出一次實驗的誤差平方的收斂曲線,給出最后設(shè)計濾波器系數(shù)。一次實驗的訓(xùn)練序列長度為500。進行20次獨立實驗,畫出誤差平方的收斂曲線。采用基于LMS的自適應(yīng)均衡算法,在相同信噪比,忘卻因子分別為μ=1.5、μ=1和μ=0.4的情況下,20次實驗誤差平方的值曲線分別如圖2、圖3和圖4所示。采用RLS法,在相同信噪比,忘卻因子分別為μ=1、μ=0.8和μ=0.6的情況下,20次實驗誤差平方的均值曲線分別如圖5、圖6和圖7所示。
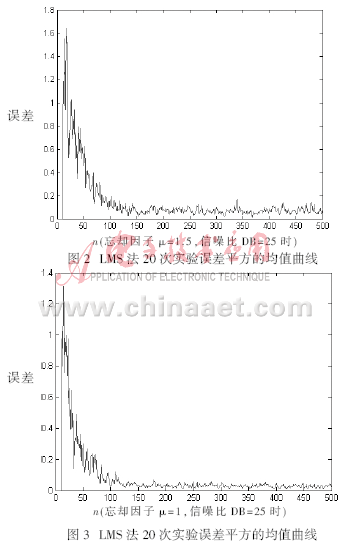

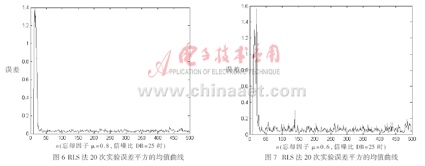
通過上述仿真結(jié)果可以看出,觀察三個不同步長情況下的平均誤差曲線,步長越小,平均誤差越小,但收斂速度越慢,為了好的精度,必然犧牲收斂速度。RLS算法的收斂速度明顯比LMS算法快,并且誤差也比LMS算法小。當(dāng)忘卻因子趨于0時,RLS算法也就是LMS算法。
通過仿真可以看出相同忘卻因子下,RLS算法的收斂速度明顯比LMS算法快,并且誤差也比LMS算法小。當(dāng)忘卻因子趨于0時,RLS算法也就是LMS算法。LMS和RLS都還有很多改進的算法,進一步的工作就是繼續(xù)分析這些算法,并且不斷完善系統(tǒng)模型。
參考文獻
[1] 何振亞.自適應(yīng)信號處理[M]. 北京:科學(xué)出版社,2002: 1-6.
[2] 張賢達.現(xiàn)代信號處理[M].北京:清華大學(xué)出版社,2002:206-210.
[3] LI Jun Ping,MA Jie,LIU Shou Yin.RLS channel estimation with superimposed training sequence in OFDM systems[C].2008 11th IEEE International on Communication Technology Proceedings.
[4] SOLIET E A. RLS solution for the adaptive recursive filter[C]. Radio Science Confere-nce,1996,Cario,Egypt.Thirteenth Nationa l19-21 March 1996:451 - 458.