
摘 要: 提出了一種基于CBR的特征屬性權(quán)重選取與自修正方法,即通過構(gòu)建歷史權(quán)重案例庫(kù)和相似性檢索得到與目標(biāo)權(quán)重最相似的權(quán)重來完成權(quán)重的選取,并對(duì)相似權(quán)重與目標(biāo)權(quán)重進(jìn)行差異性分析,基于差異屬性集對(duì)案例庫(kù)進(jìn)行聚類分析,再?gòu)木垲惤Y(jié)果中檢索出與相似權(quán)重最相近的權(quán)重,以實(shí)現(xiàn)權(quán)重的自修正。以突發(fā)大氣環(huán)境污染事故案例推理為例,對(duì)該方法進(jìn)行了試驗(yàn),結(jié)果表明此方法能充分借鑒以往的特征屬性權(quán)重分配經(jīng)驗(yàn),較好地解決了特殊環(huán)境下的復(fù)雜特征屬性權(quán)重選取與調(diào)整問題。
關(guān)鍵詞: 案例推理;權(quán)重選取;權(quán)重自修正
案例特征屬性權(quán)重反映了該屬性相對(duì)于其他屬性的重要程度,以及單個(gè)屬性對(duì)問題解決的貢獻(xiàn)程度[1-2]。案例特征屬性權(quán)重向量的選取將直接影響到檢索出案例的質(zhì)量的好壞,并進(jìn)一步影響到CBR推理的效率和質(zhì)量,同時(shí)也決定了案例復(fù)用與修改的難易。
在傳統(tǒng)的CBR系統(tǒng)中,特征屬性的權(quán)重常采用專家主觀賦權(quán)法[3],即特征屬性的權(quán)重一般事先由領(lǐng)域?qū)<腋鶕?jù)經(jīng)驗(yàn)進(jìn)行主觀判斷給定,并且特征屬性的權(quán)重一旦確定以后,便被永久地固定在系統(tǒng)中,一般很少改變。然而在許多場(chǎng)合下,特征屬性對(duì)問題解決的貢獻(xiàn)程度呈現(xiàn)著一定的波動(dòng)性,即特征屬性的權(quán)重會(huì)隨著環(huán)境、時(shí)間等因素的變化而變化[4]。因此,需要對(duì)特征屬性權(quán)重進(jìn)行動(dòng)態(tài)調(diào)整。
本文在分析現(xiàn)有案例特征屬性權(quán)重調(diào)整方法存在問題的基礎(chǔ)上,充分參考CBR的思想,提出了一種基于CBR的特征屬性權(quán)重選取與自修正方法,充分利用權(quán)重分配的歷史經(jīng)驗(yàn),指導(dǎo)當(dāng)前權(quán)重問題的動(dòng)態(tài)分配與調(diào)整。
1 特征屬性權(quán)重選取基本方法
國(guó)內(nèi)外學(xué)者對(duì)于特征屬性權(quán)重選取做了大量研究,并提出了多種權(quán)重向量選取與調(diào)整方法[5-7],如Pull&Push、遺傳算法、基于時(shí)序等。
1.1 Pull&Push調(diào)整法
Pull&Push調(diào)整[8-9]基于訓(xùn)練樣本成功和失敗的檢索經(jīng)驗(yàn)來調(diào)整特征屬性權(quán)重。當(dāng)源案例被正確檢索出來,如果源案例與目標(biāo)案例對(duì)應(yīng)特征屬性的屬性值相同,系統(tǒng)將自動(dòng)提高該屬性的權(quán)重,否則系統(tǒng)將自動(dòng)降低該屬性的權(quán)重;當(dāng)源案例被錯(cuò)誤檢索出來,如果源案例與目標(biāo)案例對(duì)應(yīng)特征屬性的屬性值不同,系統(tǒng)將自動(dòng)提高該屬性的權(quán)重,否則系統(tǒng)將自動(dòng)降低該屬性的權(quán)重。
特征屬性權(quán)重采用下式來確定每次調(diào)整幅度的大小:

以上這些調(diào)整方法基本都依賴于領(lǐng)域?qū)<沂孪葘?duì)特定問題給出一個(gè)經(jīng)驗(yàn)參考權(quán)重向量,并在此基礎(chǔ)上對(duì)其進(jìn)行不斷地重復(fù)累積調(diào)整,這種累積經(jīng)驗(yàn)對(duì)于相似環(huán)境下的權(quán)重分配需求是有效的,但對(duì)于特殊環(huán)境下的權(quán)重分配需求就顯得難以勝任。
2 基于CBR的特征屬性權(quán)重選取與自修正方法
CBR核心思想是充分借鑒以往專家經(jīng)驗(yàn)來指導(dǎo)新問題的求解[13-14]。在這種思想的啟發(fā)下,對(duì)于特征屬性權(quán)重的選取和調(diào)整問題,同樣可以嘗試用CBR的思想來解決。即將以往任何一次專家的屬性權(quán)重分配經(jīng)驗(yàn)作為案例存入歷史權(quán)重庫(kù)中,運(yùn)用歷史權(quán)重庫(kù)中歷史權(quán)重來指導(dǎo)目標(biāo)權(quán)重的選取與調(diào)整。
根據(jù)事物發(fā)展的規(guī)律性和重現(xiàn)性,即相同或相似的問題具有相同或相似的解法,相同或相似的問題會(huì)重復(fù)發(fā)生,每一個(gè)權(quán)重分配案例都是某種特定需求環(huán)境下的成功經(jīng)驗(yàn)記錄,對(duì)將來類似問題具有重要的參考借鑒作用,同時(shí)歷史權(quán)重分配經(jīng)驗(yàn)直接以新案例的形式進(jìn)行保存,避免了特定需求環(huán)境下的成功分配經(jīng)驗(yàn)的二次修改難以適應(yīng)原始需求環(huán)境。
歷史權(quán)重庫(kù)收集了以往各種不同需求的權(quán)重分配案例,積累了豐富的經(jīng)驗(yàn)和知識(shí),同時(shí)CBR具有自學(xué)習(xí)能力,隨著權(quán)重庫(kù)的不斷積累,理想情況下將會(huì)覆蓋到各種不同環(huán)境下的權(quán)重分配問題。因此,通過權(quán)重庫(kù)來解決權(quán)重分配問題是可行的也是有效的,這樣不僅能夠滿足相似環(huán)境下的權(quán)重分配需求,同時(shí)也可以處理特殊異常環(huán)境下的權(quán)重分配需求。
2.1 基于CBR的特征屬性權(quán)重選取
參考CBR基本過程,即4R(Retrieve、Reuse、Revise、Retain)[13-14],基于CBR的特征屬性權(quán)重自學(xué)習(xí)與調(diào)整策略可分為4個(gè)過程,如圖1所示。
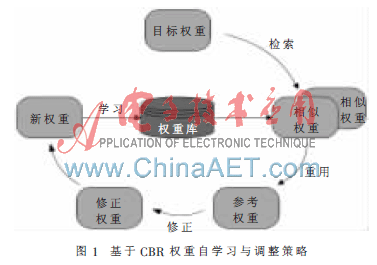
(1)權(quán)重檢索:根據(jù)目標(biāo)權(quán)重和歷史權(quán)重相似性度量標(biāo)準(zhǔn),通過合適的檢索匹配算法,從歷史權(quán)重庫(kù)中找出與目標(biāo)權(quán)重最相似的權(quán)重。
(2)權(quán)重重用:將最相似的權(quán)重作為參考權(quán)重,指導(dǎo)目標(biāo)權(quán)重的分配。
(3)權(quán)重修正:分析參考權(quán)重與目標(biāo)權(quán)重間的差異部分,通過合適的權(quán)重修正策略,并結(jié)合實(shí)際情況,對(duì)參考權(quán)重加以調(diào)整與修正。
(4)權(quán)重學(xué)習(xí):根據(jù)制定的學(xué)習(xí)策略,把新權(quán)重存儲(chǔ)到權(quán)重庫(kù)中。
基于CBR的特征屬性權(quán)重選取思想的具體實(shí)現(xiàn):
(1)結(jié)合領(lǐng)域應(yīng)用背景,收集以往專家的特征屬性權(quán)重分配經(jīng)驗(yàn),將其作為權(quán)重案例,存入歷史權(quán)重庫(kù)中以構(gòu)建領(lǐng)域問題權(quán)重參考庫(kù);
(2)對(duì)于一個(gè)新的權(quán)重分配問題,制定局部權(quán)重相似性度量標(biāo)準(zhǔn),選擇合適的權(quán)重案例相似性檢索算法,結(jié)合權(quán)重分配需求條件,對(duì)歷史權(quán)重庫(kù)進(jìn)行相似性檢索,找出相似度最高的歷史權(quán)重,即為與目標(biāo)權(quán)重最相似的權(quán)重;
(3)結(jié)合實(shí)際應(yīng)用需要,采用合適的權(quán)重調(diào)整策略,對(duì)最相似權(quán)重進(jìn)行修正,以適應(yīng)新問題;
(4)將調(diào)整后的新權(quán)重存入歷史權(quán)重庫(kù)中以豐富權(quán)重庫(kù)的經(jīng)驗(yàn),提高權(quán)重庫(kù)解決問題的能力。
2.2 基于CBR的特征屬性權(quán)重自修正
基于CBR相似性檢索得到的參考權(quán)重,可能不完全適合于當(dāng)前的權(quán)重分配需求,需要對(duì)其進(jìn)行修正。一般特征屬性權(quán)重修正規(guī)則和知識(shí)獲取十分困難,而歷史權(quán)重案例庫(kù)中儲(chǔ)備了豐富的實(shí)際經(jīng)驗(yàn)和顯性知識(shí),同時(shí)也蘊(yùn)含了大量的隱性知識(shí),這些知識(shí)對(duì)于特征屬性權(quán)重修正有一定的幫助。
基于CBR的特征屬性權(quán)重自修正的基本思想是直接從權(quán)重案例庫(kù)中得到權(quán)重修正知識(shí)。即首先從權(quán)重案例庫(kù)中檢索出與目標(biāo)權(quán)重最相似的權(quán)重案例;通過比較目標(biāo)權(quán)重和最相似的權(quán)重,得出存在差異的權(quán)重所對(duì)應(yīng)的特征屬性集合;根據(jù)這些差異特征屬性集合對(duì)權(quán)重案例庫(kù)進(jìn)行聚類,得出一個(gè)新的權(quán)重案例庫(kù);最后從新的權(quán)重案例庫(kù)中再次檢索出和上次得到的最相似權(quán)重最接近的權(quán)重組合,將這個(gè)權(quán)重組合作為參考來指導(dǎo)當(dāng)前的特征屬性權(quán)重分配。
整個(gè)修正方法在權(quán)重修正過程中應(yīng)用CBR思想,根據(jù)重用失敗的原因,找到最終的解決方案,如圖2所示。整個(gè)屬性權(quán)重修正過程不需要依賴領(lǐng)域知識(shí)。
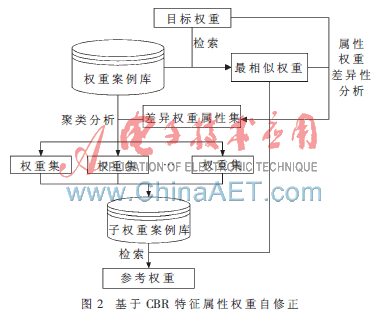
基于CBR的特征屬性權(quán)重自修正算法描述如下:
(1)假設(shè)權(quán)重案例庫(kù)為WC,目標(biāo)權(quán)重為A,先從權(quán)重案例庫(kù)WC中檢索出與A最相似的權(quán)重B。
(2)對(duì)A和B進(jìn)行特征屬性權(quán)重差異性分析,找出兩者之間的特征屬性權(quán)重差異。假設(shè)A有m個(gè)特征屬性,其中i(0≤i≤m)個(gè)特征屬性權(quán)重存在差異,如果i=0,表示沒有差異,算法結(jié)束。
(3)根據(jù)這些差異特征D1,D2,…,Di對(duì)權(quán)重案例庫(kù)進(jìn)行聚類分析。即針對(duì)每一個(gè)差異特征,從權(quán)重案例庫(kù)WC中找到和A中該特征屬性的權(quán)重值相同的案例,將其聚成一類。這樣可以得到分類D1(C),D2(C),…,Di(C),其構(gòu)成一個(gè)新權(quán)重案例庫(kù)WCnew。
(4)從WCnew中檢索出和B最相似的權(quán)重案例,并將其作為最佳權(quán)重分配參考方案。根據(jù)相似性的傳遞性原理,此權(quán)重案例不僅與目標(biāo)權(quán)重A具有較高的相似性,同時(shí)兼顧了權(quán)重案例B中部分屬性權(quán)重不能滿足目標(biāo)權(quán)重A分配的需求。
3 應(yīng)用實(shí)例
本文提出的方法在突發(fā)性大氣環(huán)境污染事故案例推理系統(tǒng)中進(jìn)行了應(yīng)用。突發(fā)性大氣環(huán)境污染事故對(duì)事故現(xiàn)場(chǎng)環(huán)境依賴性特別強(qiáng),不同環(huán)境背景下,各特征屬性表現(xiàn)出來的重要程度存在很大的差異性。以往的固定屬性權(quán)重難以滿足特殊環(huán)境下屬性權(quán)重分配的需要,而基于CBR的特征屬性權(quán)重選取與自修正方法可以很好地解決不同環(huán)境條件下的特征屬性權(quán)重分配需求。
在突發(fā)性環(huán)境污染事故案例推理系統(tǒng)中,對(duì)于特征屬性權(quán)重的選取與調(diào)整的實(shí)現(xiàn)問題,首先收集以往權(quán)重分配經(jīng)驗(yàn)并初步建立權(quán)重案例庫(kù);其次根據(jù)當(dāng)前的環(huán)境條件,確定特征屬性的重要程度,并給所關(guān)注特征屬性分配一定的權(quán)重,對(duì)于非特別關(guān)注或重要程度難以確定的特征屬性,其權(quán)重缺省為0,即目標(biāo)權(quán)重為OC(0.2,-,-,0.15,0.15,0.15,-,-,0.2),依據(jù)特征屬性權(quán)重相似性檢索算法,對(duì)權(quán)重庫(kù)進(jìn)行相似性檢索。

表1給出了目標(biāo)權(quán)重與部分歷史權(quán)重之間基于指數(shù)法和K-NN算法的相似性檢索結(jié)果,其中歷史權(quán)重案例6是與目標(biāo)權(quán)重最相似的權(quán)重。

若歷史權(quán)重案例6的權(quán)重分配滿足當(dāng)前權(quán)重分配的需要,直接將其作為目標(biāo)權(quán)重分配問題的解決方案;若對(duì)歷史權(quán)重案例6的權(quán)重分配結(jié)果不滿意,則對(duì)其執(zhí)行自修正操作。即對(duì)歷史權(quán)重案例6的參考權(quán)重與目標(biāo)權(quán)重進(jìn)行差異性分析,得到差異屬性集合{氣象條件,應(yīng)急措施},其對(duì)應(yīng)的目標(biāo)權(quán)重為{0.15,0.2};根據(jù)污染物質(zhì)、應(yīng)急決策兩個(gè)特征屬性的目標(biāo)權(quán)重對(duì)權(quán)重庫(kù)進(jìn)行聚類分析,得到兩個(gè)權(quán)重案例集{5,8}和{1,2,4,7},并構(gòu)成一個(gè)新的子權(quán)重庫(kù){1,2,4,5,7,8};再次利用屬性權(quán)重相似性檢索算法,從子權(quán)重庫(kù)中檢索出與歷史權(quán)重案例6中的參考權(quán)重最相似的權(quán)重,即為歷史權(quán)重案例5,并將其作為當(dāng)前目標(biāo)權(quán)重分配問題的參考解決方案。
依據(jù)相似性的傳遞性,歷史權(quán)重案例5不僅與目標(biāo)權(quán)重具有較高的相似性,同時(shí)彌補(bǔ)了歷史權(quán)重案例6部分屬性權(quán)重不能滿足目標(biāo)權(quán)重分配需求的不足。若對(duì)歷史權(quán)重案例5不滿意,可對(duì)其進(jìn)行人工局部調(diào)整,并將調(diào)整結(jié)果存入到權(quán)重庫(kù)中以備下次重用。
這樣不僅解決了當(dāng)前權(quán)重分配問題,同時(shí)也豐富了權(quán)重案例庫(kù)的經(jīng)驗(yàn),擴(kuò)大了權(quán)重案例庫(kù)的覆蓋面,增強(qiáng)了其解決問題的能力。
傳統(tǒng)案例屬性的靜態(tài)權(quán)重已難以滿足需要,而案例屬性權(quán)重選取與動(dòng)態(tài)調(diào)整是當(dāng)前研究的一大難題,本文嘗試借鑒CBR思想,提出了一種基于CBR的特征屬性權(quán)重選取與自修正方法,為特征屬性權(quán)重分配與調(diào)整提供了一種新的思路。基于CBR的特征屬性權(quán)重選取與自修正方法直接援引以前積累的經(jīng)驗(yàn)和知識(shí)來解決當(dāng)前特征屬性權(quán)重的選取與調(diào)整問題,具有操作實(shí)現(xiàn)簡(jiǎn)單、進(jìn)行知識(shí)積累和重用等優(yōu)點(diǎn),特別適合特殊環(huán)境下復(fù)雜問題的特征屬性權(quán)重選取與調(diào)整。
參考文獻(xiàn)
[1] LEAKE D B,KINLEY A,WILSON D.Learning to integrate multiple knowledge sources for case-based reasoning[C]. Proceedings of the Fifteenth International Joint Conference on Artificial Intelligence, Morgan Kaufmann,San Francisco,1997:246-251.
[2] 章曙光,蔡慶生.一種基于屬性組合的權(quán)重向量選取模型[J].微機(jī)發(fā)展,2004,14(11):13-15.
[3] 艾芳菊.基于實(shí)例推理系統(tǒng)中的權(quán)重分析[J].計(jì)算機(jī)應(yīng)用,2005,25(5):1022-1025.
[4] AHA D W.The omnipresence of case-based reasoning in science and application[J].Knowledge-Based Systems,1998,11(5):261-273.
[5] SKALAK D B.Prototype and feature selection by sampling and random mutation hill climbing algorithms[C].Proceedings of the 1994 International Conference on Machine Learning,293-301.
[6] MOHRI T,TANAKA H.An optimal weighting criterion of case indexing for both numeric and symbolic attributes[C]. AAAI Technical Report WS-94-01, Case-Based Reasoning:Papers from the 1994 Workshop.Menlo Park,CA:AAAI Press.
[7] LING C X,WANG H.Computing optimal attribute weight setting fot nearest neighbor algorithms[J].Artificial Intelligence Review,1997,11(1-5):255-272.
[8] SALZBERG S.A nearest hyperrectangle learning method[J]. Machine Learning,1991(6):251-276.
[9] BONZANO A,CUNNINGHAM P,SMYTH B.Using introspective learning to improve retrieval in CBR:a case study in air traffic control[C].Proceedings of the 2nd International Conference on Case-Based Reasoning,Providence RI,USA:Springer,1997:291-302.
[10] SHIN K S,HAN I.Case-based reasoning supported by genetic algorithms for corporate bond rating[J].Expert Systems with Applications,1999(16):85-95.
[11] 章曙光,汪淼,張永,等.一種基于遺傳算法的權(quán)重向量選取模型[J].微機(jī)發(fā)展,2005,15(12):87-89.
[12] 楊健,楊曉光,劉曉彬,等.一種基于K-NN的案例相似度權(quán)重調(diào)整算法[J].計(jì)算機(jī)工程與應(yīng)用,2007,43(23): 8-11.
[13] WATSON I,MARIR F.Case-based reasoning:a review[J].The knowledge engineering review,1994,9(4):327-354.
[14] CUNNINGHAM P,SMYTH B.Case-based reasoning in scheduling:reusing solution components[J].International Journal of Production Research,1997,35(11):2947-2962.