
摘 要: 對(duì)于使用支持NVIDA CUDA程序設(shè)計(jì)模型的GPU的二維一層淺水系統(tǒng),給出了如何加速平衡性良好的有限體積模式的數(shù)值解,同時(shí)給出并實(shí)現(xiàn)了在單雙浮點(diǎn)精度下使用CUDA模型利用潛在數(shù)據(jù)并行的算法。數(shù)值實(shí)驗(yàn)表明,CUDA體系結(jié)構(gòu)的求解程序比CPU并行實(shí)現(xiàn)求解程序高效。
關(guān)鍵詞: GPU;淺水系統(tǒng);OpenMP;CUDA
以具有源項(xiàng)的守恒定律形式表達(dá)的淺水方程廣泛用于引力影響下的一層流體建模,這些模型的數(shù)值解有許多用途,有關(guān)地面水流,如河流或潰壩水流的數(shù)值模擬。由于范圍廣,這些模擬需要大量的計(jì)算,因此需要很有效的求解程序在合理的執(zhí)行時(shí)間內(nèi)求解這些問(wèn)題。
因?yàn)闇\水系統(tǒng)的數(shù)值解有許多可開(kāi)發(fā)的并行性,使用并行硬件可增加數(shù)值模擬速度。參考文獻(xiàn)[1]給出了對(duì)于PC集群模擬淺水系統(tǒng)的數(shù)值模式和該模式的有效并行實(shí)現(xiàn)。參考文獻(xiàn)[2]通過(guò)使用SSE優(yōu)化的軟件模塊,改進(jìn)了這個(gè)并行實(shí)現(xiàn)。盡管這些改進(jìn)能在更快的計(jì)算時(shí)間內(nèi)獲得結(jié)果,但模擬過(guò)程仍需要很長(zhǎng)的運(yùn)行時(shí)間。
現(xiàn)代圖形處理單元GPUs為以并行方式進(jìn)行大規(guī)模浮點(diǎn)操作提供了數(shù)以百計(jì)的優(yōu)化處理單元,GPUs也可成為一種在復(fù)雜計(jì)算任務(wù)中大大提高性能的簡(jiǎn)便而有效的方法[3]。
曾有人建議將淺水?dāng)?shù)值求解程序放在GPU平臺(tái)上。為了模擬一層淺水系統(tǒng),在一個(gè)NVIDIA GeForce 7800 GTX顯卡上實(shí)現(xiàn)了一個(gè)明確的中心迎風(fēng)方法[4],并且相對(duì)于一個(gè)CPU實(shí)現(xiàn),其加速比從15到30。參考文獻(xiàn)[1]在GPUs上所給數(shù)值模式的有效實(shí)現(xiàn)在參考文獻(xiàn)[5]中有相關(guān)描述。 相對(duì)于一個(gè)單處理器實(shí)現(xiàn),在一個(gè)NVIDIA GeForce 8800 Ultra顯卡上得到了兩個(gè)數(shù)量級(jí)的加速。這些先前的建議是基于OpenGL圖形應(yīng)用程序接口[6]和Cg著色語(yǔ)言(動(dòng)畫(huà)著色語(yǔ)言)的[7]。
近來(lái),NVIDIA開(kāi)發(fā)了CUDA程序設(shè)計(jì)工具包,以C語(yǔ)言為開(kāi)發(fā)環(huán)境,對(duì)一般目的的應(yīng)用,使GPU的程序設(shè)計(jì)更為簡(jiǎn)便。
本文目標(biāo)是通過(guò)使用支持CUDA的GPUs加速淺水系統(tǒng)的數(shù)值求解,特別是為了取得更快的響應(yīng)時(shí)間,修改參考文獻(xiàn)[1]和參考文獻(xiàn)[5]中并行化的一層淺水?dāng)?shù)值求解程序,以適應(yīng)CUDA體系結(jié)構(gòu)。
1 數(shù)值模式
一層淺水系統(tǒng)是一個(gè)具有源項(xiàng)的守恒定律系統(tǒng),該系統(tǒng)可以為在引力加速度g作用下的占有一定空間的均勻流動(dòng)的淺水層建模。系統(tǒng)形式如下:
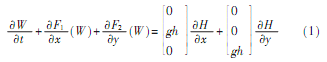
其中,



將在GPU上執(zhí)行的每個(gè)處理步驟分配到同一個(gè)CUDA核,核是在GPU上執(zhí)行的一個(gè)函數(shù),其在執(zhí)行中形成并行運(yùn)算的線程塊[9],算法實(shí)現(xiàn)步驟如下:
(1)建立數(shù)據(jù)結(jié)構(gòu)
對(duì)于每個(gè)體積,存儲(chǔ)它的狀態(tài)(h、qx、qy)和高度H。定義一個(gè)float4類(lèi)型的數(shù)組,其中每個(gè)元素表示一個(gè)體積并且包含了以前的參數(shù),因?yàn)槊總€(gè)邊(線程)僅需要它的兩個(gè)相鄰的體積的數(shù)據(jù),將數(shù)組存儲(chǔ)為一個(gè)二維紋理,紋理存儲(chǔ)器特別適合每個(gè)線程在它周?chē)h(huán)境進(jìn)行存取。另一方面,當(dāng)每個(gè)線程需要存取位于全局內(nèi)存的許多鄰近元素時(shí),每個(gè)共享內(nèi)存塊更適合,每個(gè)線程塊將這些元素的一小部分裝入共享內(nèi)存。欲實(shí)現(xiàn)兩個(gè)版本(使用二維紋理和使用共享內(nèi)存),用二維紋理可使執(zhí)行時(shí)間更短。
體積區(qū)域和垂直水平邊的長(zhǎng)度需要預(yù)先計(jì)算,并傳遞到需要它們的CUDA核。運(yùn)行時(shí)通過(guò)檢查網(wǎng)格中線程的位置,能知道一個(gè)邊或體積是否是一個(gè)邊界和一個(gè)邊的?濁ij值。
(2)處理垂直邊和水平邊
將邊分成垂直邊和水平邊進(jìn)行處理。垂直邊?濁ij,y=0,水平邊?濁ij,x=0。在垂直和水平邊處理中,每個(gè)線程分別代表一個(gè)垂直和水平邊,計(jì)算它對(duì)鄰近體積的貢獻(xiàn)在2.1節(jié)已描述。
當(dāng)借助于存儲(chǔ)在全局內(nèi)存的兩個(gè)累加器驅(qū)動(dòng)一個(gè)特定的體積時(shí),邊(即線程)彼此相互同步,并且每個(gè)邊都是float4類(lèi)型的數(shù)組元素。每個(gè)累加器的大小就是體積值。累加器的每個(gè)元素存儲(chǔ)邊對(duì)體積的貢獻(xiàn)(一個(gè)3×1向量Mi和一個(gè)float值Zi)。在垂直邊的處理中,每個(gè)邊將貢獻(xiàn)寫(xiě)入第一個(gè)累加器的右面體積和第二個(gè)累加器的左面體積。水平邊的處理與垂直邊處理類(lèi)似,只是加入累加器的貢獻(xiàn)不同。圖2和圖3分別顯示了垂直邊和水平邊的處理情況。
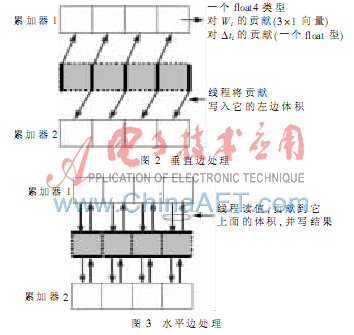
(3)為每個(gè)體積計(jì)算?駐ti
每個(gè)線程代表一個(gè)體積,正像2.1節(jié)描述的計(jì)算體積Vi的局部值Δti。最終將通過(guò)把存儲(chǔ)在兩個(gè)累加器中的相應(yīng)體積Vi位置的兩個(gè)float值相加獲得Zi值。
(4)獲得最小Δt
通過(guò)在GPU上應(yīng)用規(guī)約算法尋找體積的局部?駐ti的最小值,所應(yīng)用的規(guī)約算法是CUDA軟件開(kāi)發(fā)工具中所包含的規(guī)約樣例的核7(最優(yōu)化的一個(gè))。
(5)為每個(gè)體積計(jì)算Win+1
在這一步,每個(gè)線程代表一個(gè)體積,正如2.1節(jié)描述的修改體積Vi的狀態(tài)Wi。通過(guò)兩個(gè)3×1向量相加求出Mi的最終值,這兩個(gè)向量存儲(chǔ)在與兩個(gè)累加器的體積Vi相稱的位置。因?yàn)橐粋€(gè)CUDA的核函數(shù)不能直接寫(xiě)進(jìn)紋理,需要通過(guò)將結(jié)果寫(xiě)進(jìn)一個(gè)臨時(shí)數(shù)組來(lái)修改紋理,然后將這個(gè)數(shù)組復(fù)制到綁定紋理的CUDA數(shù)組。
這個(gè)CUDA算法的雙精度(double)版本已實(shí)現(xiàn),以上所描述的有關(guān)實(shí)現(xiàn)的差別是需要使用兩個(gè)double2類(lèi)型元素的數(shù)組存儲(chǔ)體積數(shù)據(jù),并需要使用double2類(lèi)型元素的4個(gè)累加器。

數(shù)值模式運(yùn)行在不同的網(wǎng)格。在[0,1]時(shí)間間隔內(nèi),執(zhí)行模擬系統(tǒng)。CFL參數(shù)是?酌=0.9,并且需要考慮墻壁邊界條件(q·η)。
已經(jīng)實(shí)現(xiàn)了CUDA算法的一個(gè)串行和四核CPU并行版本(使用OpenMP[8]),兩個(gè)版本都使用C++實(shí)現(xiàn),且使用矩陣操作本征庫(kù)[10],在CPU上已經(jīng)使用了double數(shù)據(jù)類(lèi)型。將CUDA實(shí)現(xiàn)與參考文獻(xiàn)[5]中描述的Cg程序進(jìn)行比較。
所有程序都是在一個(gè)具有4 GB內(nèi)存的酷睿i7920處理器上執(zhí)行,所使用的顯卡是GeForece GTX260和GeForce GTX280。表1顯示了所有網(wǎng)格和程序的執(zhí)行時(shí)間(由于沒(méi)有足夠的內(nèi)存,有些情況不能執(zhí)行)。
在具有兩種顯卡的所有情況下,單精度CUDA程序(CUSP)的執(zhí)行時(shí)間超過(guò)Cg程序的執(zhí)行時(shí)間。使用一個(gè)GeForce GTX280,相對(duì)于單核版本,CUSP實(shí)現(xiàn)了超過(guò)140的加速。對(duì)于復(fù)雜問(wèn)題在兩種顯卡下,雙精度CUDA程序(CUDP)比CUSP程序的執(zhí)行速度慢7倍。正如預(yù)期的一樣,相對(duì)于單核版本,OpenMP版本僅實(shí)現(xiàn)了不足4倍的加速(OpenMP版本的執(zhí)行速度比單核版本快不到4倍)。
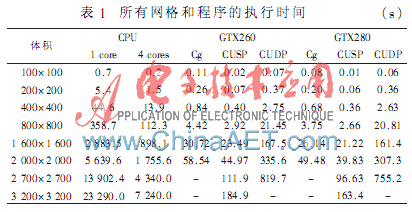
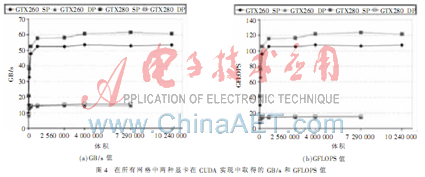
圖4以圖形的方式顯示了兩種顯卡在CUDA實(shí)現(xiàn)中取得的GB/s和GFLOPS值。用GTX280顯卡,對(duì)于大的網(wǎng)格,CUSP達(dá)到了61 GB/s和123 GFLOPS。理論最大值是:對(duì)于GTX280顯卡,GB/s和GFLOPS值分別為141.7 GB/s、933.1 GFLOPS(單精度)、77.8 GFLOPS(雙精度);對(duì)于GTX260顯卡,GB/s和GFLOPS值分別為111.9 GB/s、804.8 GFLOPS(單精度)、67.1 GFLOPS(雙精度)。
比較了在單核和CUDA程序求得的數(shù)值解,計(jì)算出了全部網(wǎng)格(t=1.0時(shí))在CPU和GPU中得出的解之間的不同L1范數(shù)。使用CUSP的L1范數(shù)的數(shù)量級(jí)在10-2~10-4之間變化,而使用CUDP所得到的數(shù)量級(jí)在10-13~10-14之間變化,這反映了在GPU上使用單雙精度計(jì)算數(shù)值解的不同精度。
使用CUDA框架為一層淺水系統(tǒng)建立和實(shí)現(xiàn)了一個(gè)有效的一階良好有限體積求解程序。為了在CUDA體系結(jié)構(gòu)上有效地并行數(shù)值模式,這個(gè)求解程序?qū)崿F(xiàn)了優(yōu)化技術(shù)。在一個(gè)GeForce GTX280顯卡上使用單精度執(zhí)行的模擬達(dá)到了61 GB/s和123 GFLOPS,比一個(gè)單核版本的求解程序快了2個(gè)數(shù)量級(jí),也比一個(gè)基于圖形語(yǔ)言的GPU版本速度快。這些模擬也顯示了用求解程序所得到的數(shù)值解對(duì)于實(shí)際應(yīng)用是足夠精確的,用雙精度比用單精度求得的解更精確。對(duì)于未來(lái)的工作,我們提出了在不規(guī)則網(wǎng)格上進(jìn)行有效模擬的擴(kuò)展策略,給出兩層淺水系統(tǒng)的模擬。
參考文獻(xiàn)
[1] CASTRO M J,GARCFA-RODRIGUEZ J A.A parallel 2D finite volume scheme for solving systems of balance laws with nonconservative products:application to shallow flows[J]. Comput Methods Appl Mech Eng,2006,195(19):2788-2815.
[2] CASTRO M J,GARCFA-RODRIGUEZ J A.Solving shallow water systems in 2D domains using finite volume methods and multimedia SSE instructions[J].Comput Appl Math,2008,221(1):16-32.
[3] RUMPF M,STRZODKA R.Graphics processor units:new prospects for parallel computing[J].Lecture notes in computational science and engineering,2006,51(1):89-132.
[4] HAGEN T R,HJELMERVIK J M,LIE K-A.Visual simulation of shallow-water waves[J].Simul Model Pract Theory,2005,13(8):716-726.
[5] LASTRA M,MANTAS J M,URENA C.Simulation of shallow water systems using graphics processing units[J].Math Comput Simul,2009,80(3):598-618.
[6] SHREINER D,WOO M,NEIDER J.OpenGL programming guide:the official guide to learning OpenGL,Version2.1[M]. ddison-Wesley Professional,2007.
[7] FERNANDO R,KILGARD M J.The Cg tutorial:the definitive guide to programmable real-time graphics[M].Addison Wesley,2003.
[8] CHAPMAN B,JOST G,DAVID J.Using OpenMP:portable shared memory parallel programming[M].The MIT Press,Cambridge 2007.
[9] NVIDIA.CUDA Zone[EB/OL].[2009-09-10].http://www.nvidia.com/object/cuda_home.html.
[10] Eigen2.0.9[EB/OL].[2009-09-10].http://eigen.tuxfamily.org.