
摘 要: 針對(duì)因特網(wǎng)環(huán)境下并行數(shù)據(jù)庫(kù)實(shí)現(xiàn)多個(gè)大數(shù)據(jù)表關(guān)聯(lián)存在的計(jì)算瓶頸,基于 Hadoop集群設(shè)計(jì)了一個(gè)并行關(guān)聯(lián)多個(gè)大數(shù)據(jù)表的簡(jiǎn)便算法MR_Join。以商業(yè)網(wǎng)站凡客誠(chéng)品的銷售數(shù)據(jù)為例進(jìn)行實(shí)驗(yàn),驗(yàn)證算法的可行性并做出應(yīng)用實(shí)例。實(shí)驗(yàn)結(jié)果表明,MR_Join算法可以有效地實(shí)現(xiàn)大數(shù)據(jù)表的快速關(guān)聯(lián),具有顯著的并行效率。
關(guān)鍵詞: Hadoop集群;Mapreduce 編程模式;MR_Join算法;數(shù)據(jù)表并行關(guān)聯(lián)
近年來(lái),隨著網(wǎng)絡(luò)技術(shù)的飛速發(fā)展,具有價(jià)位合理、購(gòu)買便捷等優(yōu)勢(shì)的電子商務(wù)迎來(lái)了嶄新的春天。商品交易市場(chǎng)正從賣家市場(chǎng)轉(zhuǎn)向買家市場(chǎng),消費(fèi)者面對(duì)種類繁多的商業(yè)網(wǎng)站及產(chǎn)品有更多的選擇性,商家只有把握顧客才能達(dá)到企業(yè)盈利的目的。深層挖掘網(wǎng)站交易數(shù)據(jù)信息有利于營(yíng)銷決策的制定,多個(gè)大數(shù)據(jù)表關(guān)聯(lián)并轉(zhuǎn)換成適合挖掘的形式是必要步驟。常見(jiàn)的方法是使用并行數(shù)據(jù)庫(kù)[1],但由于其架設(shè)和調(diào)優(yōu)難度大、對(duì)異構(gòu)硬件的支持有限、成本高以及需要對(duì)數(shù)據(jù)的存儲(chǔ)進(jìn)行格式定義等缺陷導(dǎo)致了其處理因特網(wǎng)中多個(gè)大數(shù)據(jù)表關(guān)聯(lián)時(shí)使用不便。
Mapreduce是一種分布式并行編程模型,Apache開(kāi)源社區(qū)的Hadoop項(xiàng)目是一個(gè)使用Java語(yǔ)言實(shí)現(xiàn)Mapreduce模型的開(kāi)源平臺(tái)。近年來(lái),基于Hadoop平臺(tái)在Web日志挖掘[2]、微博信息挖掘[3]、搜索引擎用戶行為分析[4]、城市交通碳排放數(shù)據(jù)挖掘研究[5]等方面都有很多應(yīng)用。與并行數(shù)據(jù)庫(kù)相比,Hadoop集群不需要對(duì)數(shù)據(jù)的存儲(chǔ)進(jìn)行格式定義,可將大數(shù)據(jù)表分解到各個(gè)計(jì)算節(jié)點(diǎn),由各節(jié)點(diǎn)并行執(zhí)行,集群監(jiān)控各個(gè)計(jì)算節(jié)點(diǎn)的任務(wù)狀態(tài),具有高容錯(cuò)性和高擴(kuò)展性。同時(shí),Hadoop滿足數(shù)據(jù)的多級(jí)計(jì)算和處理,可有效解決“一個(gè)程序的輸出是另外一個(gè)程序的輸入”這類復(fù)雜的數(shù)據(jù)挖掘。
本文基于Hadoop集群,設(shè)計(jì)了一個(gè)適合多個(gè)大數(shù)據(jù)表并行關(guān)聯(lián)的簡(jiǎn)便算法MR_Join。以商業(yè)網(wǎng)站凡客誠(chéng)品的銷售數(shù)據(jù)表為例進(jìn)行實(shí)驗(yàn),實(shí)驗(yàn)結(jié)果顯示Hadoop具有在處理網(wǎng)絡(luò)下大數(shù)據(jù)表關(guān)聯(lián)的優(yōu)勢(shì),也驗(yàn)證了MR_Join算法的可行性。集群中各個(gè)計(jì)算節(jié)點(diǎn)并行處理,處理速度快、延遲低且易于操作。
1 MR_Join關(guān)聯(lián)算法設(shè)計(jì)
Hadoop的兩個(gè)核心部分是分布式文件系統(tǒng)HDFS和Mapreduce模型。HDFS為分布式計(jì)算提供了底層存儲(chǔ)支持,易于讀取大規(guī)模的數(shù)據(jù)文件。Hadoop集群由一個(gè)NameNode和一組DataNode組成,采取Master/Slave的架構(gòu)。Mapreduce分布式并行編程模型的基本思想源于函數(shù)式編程語(yǔ)言[6],Map和Reduce是該模型的兩大基本操作。Map函數(shù)指定各分塊數(shù)據(jù)的處理過(guò)程并映射出中間結(jié)果,Reduce函數(shù)指定如何對(duì)中間結(jié)果進(jìn)行歸約并生成最終的處理結(jié)果。其概念可以表達(dá)為:Map<k1,v1>list<k2,v2>;Reduce<k2,list(v2)>list(v2);
1.1 MR_Join大數(shù)據(jù)表并行關(guān)聯(lián)算法
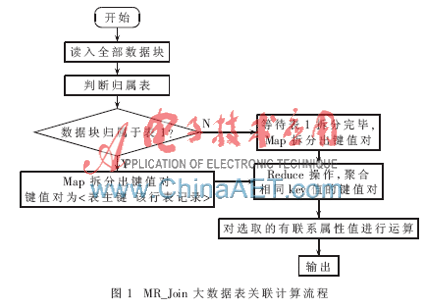
MR_Join算法是一種關(guān)聯(lián)有相同表主鍵的表的關(guān)聯(lián)方法,其計(jì)算流程如圖1所示。算法思路為:被處理的多個(gè)表應(yīng)具有相同的表主鍵,算法首先判斷輸入的數(shù)據(jù)塊歸屬于哪個(gè)表,同一個(gè)表的數(shù)據(jù)塊由同一個(gè)Map處理。Map操作把表數(shù)據(jù)拆分成以表主鍵為Key值的鍵值對(duì),Reduce操作把具有相同Key值的鍵值對(duì)聚合在一起。最后從各個(gè)表中分別選取一個(gè)屬性(選取的屬性之間應(yīng)存在直接聯(lián)系),將屬性值進(jìn)行運(yùn)算得到一個(gè)新屬性的屬性值,在運(yùn)算過(guò)程中實(shí)現(xiàn)數(shù)據(jù)表關(guān)聯(lián)。在Hadoop集群中,NameNode節(jié)點(diǎn)分配計(jì)算任務(wù)給各個(gè)DataNode,多個(gè)DataNode并行執(zhí)行計(jì)算任務(wù),達(dá)到短時(shí)間內(nèi)快速準(zhǔn)確地完成兩個(gè)大數(shù)據(jù)表關(guān)聯(lián)的效果,生成一個(gè)可以有效分析的大數(shù)據(jù)表。本文采用Java語(yǔ)言實(shí)現(xiàn)MR_Join算法。
1.2 MR_Join算法應(yīng)用實(shí)例
本文以消費(fèi)網(wǎng)站凡客誠(chéng)品的商品信息和銷售數(shù)據(jù)為例,數(shù)據(jù)獲取的方式采用Web爬蟲(chóng)方式。Web爬蟲(chóng)通過(guò)訪問(wèn)凡客誠(chéng)品網(wǎng)站的Web頁(yè)面,解析頁(yè)面相關(guān)內(nèi)容和頁(yè)面源代碼,獲取所需的數(shù)據(jù)信息,生成商品屬性Product表和購(gòu)買商品的用戶信息Sale表,并以文本文件的形式輸出數(shù)據(jù)表。兩個(gè)數(shù)據(jù)表的“商品編號(hào)”字段作為主鍵,并根據(jù)Product表的“單價(jià)”和Sale表的“數(shù)量”計(jì)算出“總價(jià)格”,計(jì)算結(jié)果按照“商品編號(hào)”升序排序。兩個(gè)表相連能夠顯現(xiàn)出購(gòu)買每種商品的用戶信息和該用戶的消費(fèi)總價(jià)格,有利于商家對(duì)客戶進(jìn)行歸類及后續(xù)對(duì)應(yīng)的商品營(yíng)銷。Reduce操作按“商品編號(hào)”對(duì)計(jì)算結(jié)果升序排序,同類商品銷售情況一目了然,為下一步的市場(chǎng)營(yíng)銷策劃提供客觀依據(jù)。
MR_Join算法處理數(shù)據(jù)基本流程如圖2所示。
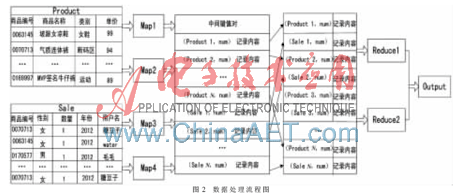
(1)定義Product ID為商品表的“商品編號(hào)”字段,Sale ID為用戶表的“商品編號(hào)”字段。num為用戶表的“數(shù)量”字段,在Product表中num值為0。“總價(jià)格”是通過(guò)“單價(jià)”和“數(shù)量”之間的運(yùn)算得到的新字段。
(2)算法默認(rèn)逐行讀取表記錄并將記錄偏移量及該行記錄內(nèi)容映射為初始鍵值對(duì)。Map操作對(duì)初始鍵值對(duì)進(jìn)行處理,提取出“商品編號(hào)”形成中間鍵值對(duì),生成<(Product ID,num)記錄內(nèi)容>或<(Sale ID,num)記錄內(nèi)容>。
(3)Shuffle和Sort操作把具有相同鍵值的鍵值對(duì)合并分組,其結(jié)果作為Reduce操作的輸入鍵值對(duì)。
(4)Reduce操作將相同鍵值的鍵值對(duì)聚集,由于Web爬蟲(chóng)在爬取信息記錄時(shí),消費(fèi)數(shù)量是生成相同數(shù)量的相同消費(fèi)記錄,所以Reduce過(guò)程先對(duì)Sale表的鍵值對(duì)進(jìn)行For循環(huán)計(jì)算“數(shù)量”,再用For循環(huán)作相乘運(yùn)算計(jì)算“總價(jià)格”。總價(jià)格=(Sale表)num×(Product表)單價(jià)。
2 實(shí)驗(yàn)結(jié)果及分析
2.1 實(shí)驗(yàn)環(huán)境
本實(shí)驗(yàn)運(yùn)行在4臺(tái)PC機(jī)搭建的Hadoop集群上,均為同等配置。各節(jié)點(diǎn)名分別為Master、Slave01、Slave02和Salve03。各個(gè)節(jié)點(diǎn)均安裝了Hadoop-0.20.2和JDK。在Hadoop搭建的集群系統(tǒng)上運(yùn)行了本文開(kāi)發(fā)的MR_Join算法。本實(shí)驗(yàn)分別在單機(jī)、多個(gè)節(jié)點(diǎn)集群中運(yùn)行。實(shí)驗(yàn)數(shù)據(jù)是利用Web爬蟲(chóng)在凡客誠(chéng)品網(wǎng)站獲取的2012年4月份的商品信息和銷售數(shù)據(jù)。
2.2 實(shí)驗(yàn)內(nèi)容及結(jié)果分析
(1)單節(jié)點(diǎn)測(cè)試。分別執(zhí)行了200 MB、500 MB、1.1 GB和1.5 GB 4種大小不同的商品屬性表和用戶信息表的關(guān)聯(lián)。通過(guò)圖3可以發(fā)現(xiàn),200 MB表文件的執(zhí)行時(shí)間比500 MB表文件的執(zhí)行時(shí)間長(zhǎng),之后隨著表文件規(guī)模的增大,算法執(zhí)行的時(shí)間也相應(yīng)地增加。說(shuō)明當(dāng)數(shù)據(jù)規(guī)模較低時(shí),由于Hadoop框架啟動(dòng)時(shí)間長(zhǎng)、開(kāi)銷較大,執(zhí)行效率低。當(dāng)數(shù)據(jù)規(guī)模增大時(shí),執(zhí)行效率逐漸增大。

(2)多節(jié)點(diǎn)并行測(cè)試。圖3為單節(jié)點(diǎn)環(huán)境與雙節(jié)點(diǎn)環(huán)境下MR_Join算法執(zhí)行時(shí)間對(duì)比,表1為MR_Join算法多節(jié)點(diǎn)并行執(zhí)行效果分析表。P為集群節(jié)點(diǎn)數(shù)目。

實(shí)驗(yàn)結(jié)果顯示出3對(duì)不同規(guī)模的大數(shù)據(jù)表關(guān)聯(lián)時(shí),并行效率與集群的節(jié)點(diǎn)數(shù)目成正比,且隨著表數(shù)據(jù)規(guī)模的增大而增大。當(dāng)表數(shù)據(jù)規(guī)模較低時(shí),利用Hadoop集群執(zhí)行大數(shù)據(jù)表關(guān)聯(lián)效率低。當(dāng)表數(shù)據(jù)規(guī)模較大時(shí),利用Hadoop集群并行執(zhí)行計(jì)算,在節(jié)點(diǎn)數(shù)為4時(shí)可達(dá)到78.2%的并行效率。說(shuō)明在表數(shù)據(jù)規(guī)模和Hadoop集群節(jié)點(diǎn)數(shù)目選擇適當(dāng)?shù)那闆r下,本文設(shè)計(jì)的MR_Join算法可以取得良好的并行效率。
大數(shù)據(jù)表關(guān)聯(lián)后產(chǎn)生的數(shù)據(jù)表是企業(yè)數(shù)據(jù)挖掘和營(yíng)銷決策制定的重要數(shù)據(jù)基礎(chǔ)。本文設(shè)計(jì)的MR_Join算法以商業(yè)網(wǎng)站凡客誠(chéng)品的商品銷售數(shù)據(jù)為例進(jìn)行實(shí)驗(yàn),成功實(shí)現(xiàn)了大數(shù)據(jù)表關(guān)聯(lián)。實(shí)驗(yàn)結(jié)果表明,Hadoop集群對(duì)于并行執(zhí)行計(jì)算任務(wù)的高容錯(cuò)性及高度可擴(kuò)展性使得大數(shù)據(jù)表關(guān)聯(lián)的結(jié)果準(zhǔn)確且并行效率顯著,避免了并行數(shù)據(jù)庫(kù)在因特網(wǎng)環(huán)境下實(shí)現(xiàn)表關(guān)聯(lián)的弊端,可以在電子商務(wù)的商業(yè)應(yīng)用中體現(xiàn)更高的價(jià)值。現(xiàn)今Hadoop已經(jīng)被廣泛應(yīng)用于海量數(shù)據(jù)存儲(chǔ)和分析、互聯(lián)網(wǎng)服務(wù)、搜索引擎等。本文針對(duì)Hadoop下的大數(shù)據(jù)表關(guān)聯(lián)作了有益的嘗試,本文的算法也可以用于其他相關(guān)應(yīng)用中。
參考文獻(xiàn)
[1] 王珊,王會(huì)舉,覃雄派,等.架構(gòu)大數(shù)據(jù):挑戰(zhàn)、現(xiàn)狀與展望[J].計(jì)算機(jī)學(xué)報(bào),2011,34(10):1741-1751.
[2] 程苗,陳華平.基于Hadoop的Web日志挖掘[J].計(jì)算機(jī)工程,2011,37(11):37-39.
[3] 林大云.基于Hadoop的微博信息挖掘[J].計(jì)算機(jī)光盤(pán)軟件與應(yīng)用,2012(1):7-8.
[4] 王振宇,郭力.基于Hadoop搜索引擎用戶行為分析[J].計(jì)算機(jī)工程與科學(xué),2011,33(4):115-120.
[5] 朱鑰,賈思奇,張俊魁,等.基于Hadoop的城市交通碳排放數(shù)據(jù)挖掘研究[J].計(jì)算機(jī)應(yīng)用研究,2011,28(11):4213-4215.
[6] 謝桂蘭,羅省賢.基于Hadoop Mapreduce模型的應(yīng)用研究[J].微型機(jī)與應(yīng)用,2010,29(8):4-7.