
作者:Sharad Sinha
博士生
新加坡南洋理工大學(xué)
[email protected]
Vivado HLS配合C語言等高級(jí)語言能幫助您在FPGA上快速實(shí)現(xiàn)算法,。
為了幫助用戶了解Vivado HLS如何工作,,我們不妨以矩陣乘法設(shè)計(jì)為例逐步剖析從設(shè)計(jì)描述(C/C++/SystemC)到FPGA實(shí)現(xiàn)整個(gè)端對(duì)端綜合流程,。矩陣乘法在許多應(yīng)用中都很常見,并廣泛用于圖像和視頻處理,、科學(xué)計(jì)算和數(shù)字通信,。本項(xiàng)目中的所有結(jié)果均使用Vivado HLS 2012.4生成,搭配使用賽靈思 ISE®軟件(14.4版)進(jìn)行物理綜合和布局布線。此外,,這一流程還采用了ModelSim和GCC-4.2.1-mingw32vc9進(jìn)行RTL協(xié)同仿真,。
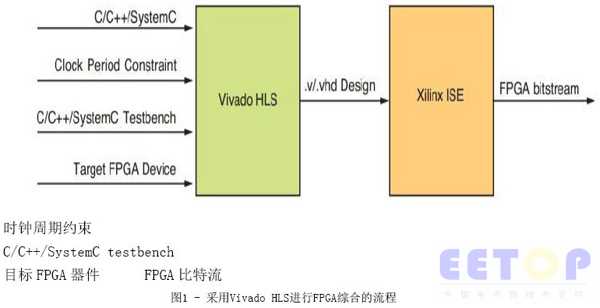
圖1顯示了簡(jiǎn)單的綜合流程,從C/C++/SystemC設(shè)計(jì)開始,。C/C++/SystemC testbench用于驗(yàn)證設(shè)計(jì)功能的正確性,同時(shí)還可用于RTL和C的協(xié)同仿真,。協(xié)同仿真包括驗(yàn)證生成的RTL設(shè)計(jì)(.v或.vhd)功能,,這要使用C/C++/SystemC測(cè)試平臺(tái)而不是RTL測(cè)試平臺(tái)或者采用e或Vera驗(yàn)證語言編寫的測(cè)試平臺(tái)。時(shí)鐘周期約束設(shè)置了設(shè)計(jì)應(yīng)該運(yùn)行的目標(biāo)時(shí)鐘周期,。設(shè)計(jì)將被映射到目標(biāo)FPGA器件——賽靈思FPGA上,。
C語言的矩陣乘法
為了充分利用我們的矩陣乘法實(shí)例,我們將探索矩陣乘法C語言實(shí)現(xiàn)方案的各種修訂版本,,從而展示它們對(duì)綜合設(shè)計(jì)的影響,。這一過程將凸顯您在使用HLS進(jìn)行原型設(shè)計(jì)和實(shí)際設(shè)計(jì)時(shí)需要注意的重要問題。我們將跳過創(chuàng)建工程的有關(guān)步驟,,因?yàn)槟芎芊奖愕卦诠ぞ呶臋n中找到相關(guān)參考材料,。我們將重點(diǎn)介紹設(shè)計(jì)和實(shí)現(xiàn)等方面。
在典型的Vivado HLS流程中,,我們需要三個(gè)C/C++文件:源文件(包括待綜合的C函數(shù)),、頭文件和通過main()函數(shù)調(diào)用描述testbench的文件。
頭文件不僅包括源文件中使用的函數(shù)的聲明,,也包括支持具有特定位寬的用戶定義數(shù)據(jù)類型的指令,。這也使得設(shè)計(jì)人員能夠采用與C/C++所定義標(biāo)準(zhǔn)位寬不同的位寬。舉例來說,,整形數(shù)據(jù)類型(int)在C語言中通常為32位長(zhǎng),,但是在Vivado HLS中您可指定用戶定義的數(shù)據(jù)類型,例如只使用16位的“data”,。
圖2顯示了用于矩陣乘法的簡(jiǎn)單C函數(shù),。兩個(gè)矩陣mat1和mat2進(jìn)行乘法。為了簡(jiǎn)單起見,,兩個(gè)矩陣大小一樣,,都是兩行兩列。

在HLS流程中執(zhí)行的步驟如下:
• 第一步:創(chuàng)建工程
• 第二步:測(cè)試功能
• 第三步:綜合
• 第四步:RTL協(xié)同仿真
• 第五步:導(dǎo)出RTL / RTL實(shí)現(xiàn)
第一步編譯工程并在不同的設(shè)計(jì)文件中測(cè)試語法錯(cuò)誤等,。第二步測(cè)試待實(shí)現(xiàn)的函數(shù)(在源文件中)功能是否正確,。在這一步驟中您將使用testbench執(zhí)行函數(shù)調(diào)用,驗(yàn)證其功能是否正確,。如果功能驗(yàn)證失敗,,您就需要返回來修改設(shè)計(jì)文件。
第三步進(jìn)行綜合,Vivado HLS綜合源文件中定義的函數(shù),。這一步的輸出包括C函數(shù)的Verilog和VHDL代碼(RTL設(shè)計(jì)),,也包括目標(biāo)FPGA的資源利用率估算和時(shí)鐘周期估算。此外,,Vivado HLS還可生成latency估算和回路相關(guān)的度量指標(biāo)等,。
第四步是使用C testbench仿真生成的RTL。這一步叫做RTL協(xié)同仿真,,因?yàn)楣ぞ卟捎玫木褪侵坝糜隍?yàn)證C源代碼的testbench,,現(xiàn)在則測(cè)試RTL的功能正確性。要成功完成這一步,,您系統(tǒng)(Windows或Linux)中的PATH環(huán)境變量應(yīng)包含ModelSim安裝的路徑,。此外,您還應(yīng)在ModelSim安裝文件夾中包含GCC-4.2.1-mingw32vc9套件,。
最后,,第五步就要將RTL導(dǎo)出為IP模塊,用于更大的設(shè)計(jì)中,,并由其它賽靈思工具進(jìn)行處理,。您可將RTL導(dǎo)出為IP-XACT格式的IP模塊,也可導(dǎo)出為System Generator IP模塊或pcore格式的IP模塊,,進(jìn)而用于賽靈思嵌入式設(shè)計(jì)套件,。導(dǎo)出Vivado生成的RTL時(shí),您可以選擇工具的“評(píng)估”選項(xiàng)來評(píng)估布局布線后的性能并且運(yùn)行RTL實(shí)現(xiàn),。在此情況下,, Vivado HLS工具會(huì)調(diào)用賽靈思ISE工具。要實(shí)現(xiàn)這一目的,,您的系統(tǒng)PATH環(huán)境變量需包括ISE安裝路徑,,Vivado HLS將會(huì)搜索ISE安裝。
當(dāng)然,,您也不一定非要將Vivado生成的RTL導(dǎo)出為以上三種格式之一的IP模塊不可,。導(dǎo)出的格式文件可放在三個(gè)不同路徑下:
//impl/
或project_directory>//impl/或
//impl/。此外,,您也可在較大設(shè)計(jì)中使用Vivado生成的RTL,,或者將其本身用作頂層設(shè)計(jì)。當(dāng)較大設(shè)計(jì)中例化導(dǎo)出的RTL時(shí),,您應(yīng)注意相關(guān)接口要求,。
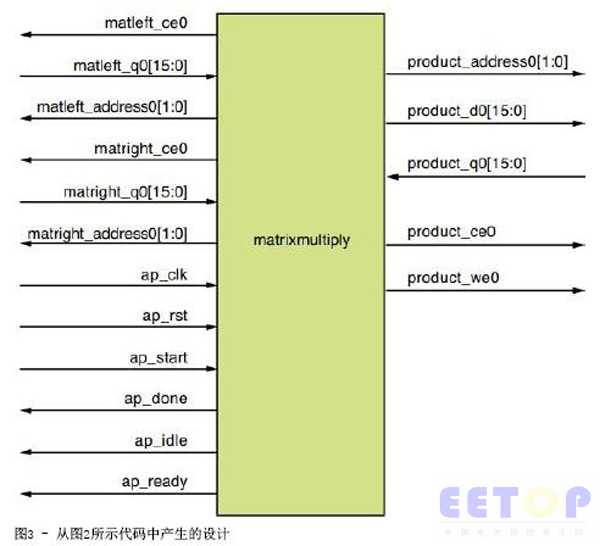
當(dāng)綜合圖2中的C函數(shù)時(shí),您將獲得如圖3所示的RTL級(jí)實(shí)現(xiàn)方案,。您會(huì)發(fā)現(xiàn),,實(shí)現(xiàn)方案中的矩陣1和矩陣2的元素被讀取到函數(shù),,并且積矩陣的元素被寫出。這樣,,實(shí)現(xiàn)方案假定“矩陣乘法”實(shí)體以外的存儲(chǔ)器能用來存儲(chǔ)矩陣1,、矩陣2和乘積矩陣的元素。表1介紹了信號(hào)描述,,表2則介紹了設(shè)計(jì)度量指標(biāo),。
表2:用于圖3所示設(shè)計(jì)的設(shè)計(jì)度量指標(biāo)
|
設(shè)計(jì)度量指標(biāo) |
器件:XC6VCX75TFF784-2 |
|
DSP48E |
1 |
|
查找表 |
44 |
|
觸發(fā)器 |
61 |
|
實(shí)現(xiàn)的最佳時(shí)鐘周期(ns) |
2.856 |
|
時(shí)延 |
69 |
|
吞吐量(初始間隔) |
69 |
表1:面向圖3中設(shè)計(jì)的信號(hào)描述
|
信號(hào) |
描述 |
|
matleft_ce0 |
矩陣1存儲(chǔ)器的芯片使能 |
|
matleft_q0[15:0] |
矩陣1的16位元素 |
|
matleft_address[1:0] |
矩陣1存儲(chǔ)器的讀地址 |
|
matright_ce0 |
矩陣2存儲(chǔ)器的芯片使能 |
|
matright_q0[15:0] |
矩陣2的16位元素 |
|
matright_address[1:0] |
矩陣2存儲(chǔ)器的讀地址 |
|
product_ce0 |
積矩陣的存儲(chǔ)器的芯片使能 |
|
product_we0 |
積矩陣的存儲(chǔ)器的寫使能 |
|
product_d0[15:0] |
積矩陣存儲(chǔ)器的寫數(shù)據(jù) |
|
product_q0[15:0] |
積矩陣存儲(chǔ)器的讀數(shù)據(jù) |
|
product_address0[1:0] |
積矩陣要讀寫數(shù)據(jù)的地址 |
|
ap_clk |
設(shè)計(jì)的時(shí)鐘信號(hào) |
|
ap_rst |
設(shè)計(jì)的高有效同步復(fù)位信號(hào) |
|
ap_start |
開始計(jì)算的開始信號(hào) |
|
ap_done |
計(jì)算結(jié)束和輸出就緒的完成信號(hào) |
|
ap_idle |
表示實(shí)體(設(shè)計(jì))空閑的空閑信號(hào) |
|
ap_ready |
表示設(shè)計(jì)為新輸入數(shù)據(jù)做好準(zhǔn)備,與ap_idle配合使用 |
在表1中,,start,、done和idle信號(hào)與設(shè)計(jì)中控制數(shù)據(jù)路徑的有限狀態(tài)機(jī)(FSM)有關(guān)。您會(huì)發(fā)現(xiàn),,Vivado HLS生成的Verilog假定運(yùn)算始于start信號(hào),并且輸出數(shù)據(jù)在ap_done信號(hào)從低變高開始有效,。Vivado HLS生成的Verilog/VHDL將始終保持至少三個(gè)基本信號(hào):ap_start,、ap_done和ap_idle,此外還有ap_clk信號(hào),。這意味著不管您使用Vivado HLS實(shí)現(xiàn)什么設(shè)計(jì),,設(shè)計(jì)latency都會(huì)限制您的流吞吐量。圖2中的設(shè)計(jì)latency為69個(gè)時(shí)鐘周期,,目標(biāo)時(shí)鐘周期為3納秒,。這意味著在此特定案例中,所有積矩陣元素需要69個(gè)時(shí)鐘周期可輸出,。這樣,,您在至少69個(gè)時(shí)鐘周期前不能為設(shè)計(jì)提供新一組的輸入矩陣。
圖3中所示的實(shí)現(xiàn)方案現(xiàn)在可能并不是您在FPGA上實(shí)現(xiàn)矩陣乘法時(shí)所預(yù)想的結(jié)果,。您或許希望一款實(shí)現(xiàn)方案能讓您輸入矩陣,,并在內(nèi)部進(jìn)行存儲(chǔ)和計(jì)算,隨后讀取積矩陣元素,。這顯然是圖2所示實(shí)現(xiàn)方案無法做到的,。該實(shí)現(xiàn)方案需要外部存儲(chǔ)器提供矩陣數(shù)據(jù)的輸入和輸出。
調(diào)整代碼
圖4中的代碼能夠滿足您的需求,,它是源文件的一部分,,應(yīng)該屬于C++文件而非此前的C文件。您應(yīng)在頭文件matrixmultiply.h中包含另外兩個(gè)相關(guān)頭文件:hls_stream.h和ap_int.h,。請(qǐng)注意,,在圖2中,當(dāng)源文件為C文件時(shí),,頭文件包含了ap_cint.h,。頭文件ap_int.h和ap_cint.h有助于分別為C++和C源文件定義用戶定義的任意位寬的數(shù)據(jù)類型。需要頭文件hls_stream.h來充分利用流接口,并且只有在源文件為C++語言時(shí)才能使用,。

圖4:用于矩陣乘法的重組源代碼
為了讓設(shè)計(jì)只接收輸入矩陣流,,并輸出積矩陣流,您應(yīng)在代碼中實(shí)現(xiàn)讀和寫數(shù)據(jù)流,。流接口就像FIFO,。默認(rèn)情況下這個(gè)FIFO的深度為1。
表3 - 圖5中設(shè)計(jì)的信號(hào)描述
|
信號(hào) |
|
描述 |
|
d_mat1_V_read |
|
設(shè)計(jì)為矩陣1(左側(cè)矩陣)輸入做好準(zhǔn)備時(shí)的信號(hào) |
|
d_mat1_V_dout [15:0] |
|
矩陣1的16位流元素 |
|
d_mat1_V_empty |
|
通知設(shè)計(jì)矩陣1沒有更多元素的信號(hào) |
|
d_mat2_V_read |
|
設(shè)計(jì)為矩陣2(右側(cè)矩陣)輸入做好準(zhǔn)備時(shí)的信號(hào) |
|
d_mat2_V_dout [15:0] |
|
矩陣2的16位流元素 |
|
d_mat2_V_empty |
|
通知設(shè)計(jì)矩陣2沒有更多元素的信號(hào) |
|
d_product_V_din [15:0] |
|
積矩陣的16位輸出元素 |
|
d_product_V_full_n |
|
通知設(shè)計(jì)積矩陣應(yīng)該被寫入的信號(hào) |
|
d_product_V_write |
|
顯示積矩陣正在被寫入數(shù)據(jù)的信號(hào) |
|
ap_clk |
|
設(shè)計(jì)的時(shí)鐘信號(hào) |
|
ap_rst |
|
設(shè)計(jì)的高有效同步復(fù)位信號(hào) |
|
ap_start |
|
開始計(jì)算的開始信號(hào) |
|
ap_done |
|
計(jì)算結(jié)束和準(zhǔn)備好信號(hào)輸出的完成信號(hào) |
|
ap_idle |
|
表明實(shí)體(設(shè)計(jì))空閑的空閑信號(hào) |
|
ap_ready |
|
表示設(shè)計(jì)為新輸入數(shù)據(jù)做好準(zhǔn)備,,與ap_idle配合使用 |
表4:圖5所示設(shè)計(jì)的設(shè)計(jì)度量指標(biāo)
|
器件:XC6VCX75TFF784-2 |
|||
|
設(shè)計(jì)參數(shù) |
無BRAM 或無分布式RAM存儲(chǔ)矩陣 |
單端口BRAM存儲(chǔ)矩陣 |
分布式RAM(LUT實(shí)現(xiàn))存儲(chǔ)矩陣 |
|
DSP48E |
1 |
1 |
1 |
|
查詢表 |
185 |
109 |
179 |
|
觸發(fā)器 |
331 |
102 |
190 |
|
BRAM |
0 |
3 |
0 |
|
實(shí)現(xiàn)的最佳時(shí)鐘周期(納秒) |
2.886 |
3.216 |
2.952 |
|
時(shí)延 |
84 |
116 |
104 |
|
吞吐量(初始間隔) |
84 |
116 |
104 |
為了讓設(shè)計(jì)只接受輸入矩陣流,,并輸出積矩陣流,您應(yīng)在代碼中實(shí)現(xiàn)讀和寫數(shù)據(jù)流,。代碼hls::stream<> stream_name用于為讀和寫數(shù)據(jù)流命名,。這樣,d_mat1和d_mat2為讀取流而d_product為寫入流,。流接口就像FIFO那樣工作,。默認(rèn)情況下,F(xiàn)IFO的深度為1,。您應(yīng)在Vivado HLS指令面板中通過選擇定義的數(shù)據(jù)流設(shè)置深度,。對(duì)于圖4中的代碼而言,每個(gè)數(shù)據(jù)流的深度都為4個(gè)數(shù)據(jù)單元,。請(qǐng)注意,,這里的(i,j)回路在(p,q)回路之前執(zhí)行,這是C++代碼的順序特性使然,。因此,,d_mat2數(shù)據(jù)流會(huì)在d_mat1數(shù)據(jù)流之后填滿。
完成數(shù)據(jù)流接口后,,您可應(yīng)用指令RESOURCE并通過指令面板選擇一個(gè)核,,從而選擇將矩陣映射到BRAM。否則將用觸發(fā)器和查找表(LUT)實(shí)現(xiàn)矩陣,。請(qǐng)注意,,指令面板只有當(dāng)源文件在綜合視圖中保持有效時(shí)才是有效的。
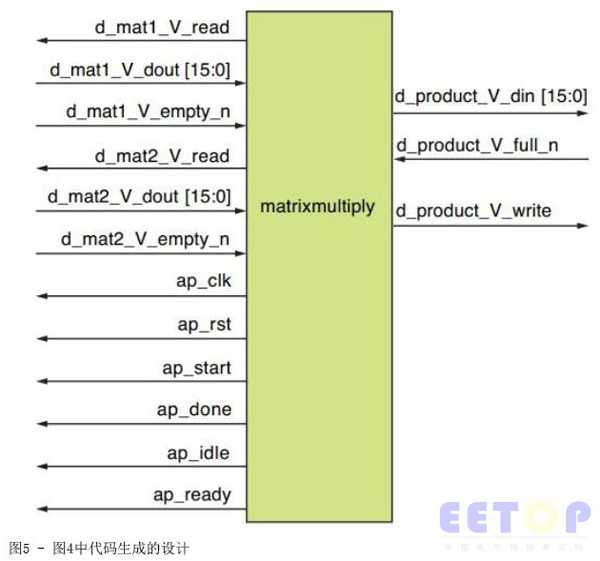
圖5顯示了圖4中代碼的設(shè)計(jì)實(shí)現(xiàn)情況,。表3介紹了設(shè)計(jì)接口上可用的信號(hào)情況,。在表3中,d_product_V_full_n是低有效信號(hào),,當(dāng)需要通知內(nèi)核積矩陣已滿時(shí)該信號(hào)為低,。但在實(shí)現(xiàn)方案中通常不需要這樣。
表4顯示了3納秒時(shí)鐘周期約束下布局布線后的不同設(shè)計(jì)度量指標(biāo),,包含了矩陣陣列映射到BRAM或分布式RAM的情況和未映射的情況,。您從表4中可以看到,,矩陣映射到單端口BRAM時(shí),設(shè)計(jì)無法滿足3納秒的時(shí)序約束,。表中專門包含了這個(gè)結(jié)果,,說明您可用這種方法生成具有不同面積—時(shí)序參數(shù)的各種設(shè)計(jì)。此外,,您也可從表1看出,,雖然圖2中代碼的時(shí)延為69個(gè)時(shí)鐘周期,低于圖4中調(diào)整后的代碼的設(shè)計(jì)方案,,但這種設(shè)計(jì)需要矩陣乘法實(shí)體以外的存儲(chǔ)器,,這一點(diǎn)我們?cè)谏厦嬉呀?jīng)解釋過了。
實(shí)現(xiàn)方案的精度
就這里顯示的結(jié)果而言,,我將“data”這種數(shù)據(jù)類型定義為16位寬,。因此,所有矩陣元素(左,、右和積矩陣)都為16位寬,。矩陣乘法和加法運(yùn)算不能實(shí)現(xiàn)全精度。您可選擇在頭文件中定義另一種32位寬的數(shù)據(jù)類型data_t1,,積矩陣的所有元素都采用這種數(shù)據(jù)類型,,因?yàn)?6位數(shù)(左側(cè)矩陣元素)乘以另一個(gè)16位數(shù)(右側(cè)矩陣元素)最多得到32位寬,。這樣,,資源利用率和時(shí)序結(jié)果將不同于表1和表4中的結(jié)果。
調(diào)整后的源代碼顯示出同樣的源文件會(huì)帶來多種不同設(shè)計(jì)解決方案,。在本例中,,一個(gè)設(shè)計(jì)解決方案采用BRAM,而另一個(gè)沒有采用,。在每個(gè)Vivado HLS工程目錄中,,您會(huì)看到Vivado HLS為不同的解決方案生成了不同的目錄。在每個(gè)解決方案目錄中都有一個(gè)名叫impl(也就是implementation,,實(shí)現(xiàn)方案)的子目錄,。在這個(gè)子目錄中,您會(huì)看到名為Verilog或VHDL的目錄,,具體取決于RTL實(shí)現(xiàn)階段使用什么樣的源代碼,。這個(gè)子目錄中也包含賽靈思ISE工程文件(文件擴(kuò)展名為.xise)。如果Vivado HLS生成的設(shè)計(jì)是您的頂層設(shè)計(jì),,那么您可以雙擊這個(gè)文件來啟動(dòng)賽靈思ISE運(yùn)行這個(gè)解決方案,,并生成用于門級(jí)時(shí)序和功能仿真的布局布線后模型。但您在Vivado HLS中不能做這種仿真,。
在ISE中啟動(dòng)解決方案后,,您應(yīng)給設(shè)計(jì)分配I/O引腳,。隨后您可在ISE Project Navigator中選擇“Generating Programming File”以生成比特流。
在這一練習(xí)中,,我們一步步完成了Vivado HLS一個(gè)實(shí)際的端對(duì)端流程,,并在FPGA上實(shí)現(xiàn)算法。對(duì)于Vivado HLS中的許多高級(jí)特性而言,,您應(yīng)了解您需要什么樣的硬件架構(gòu),,從而進(jìn)行源代碼的調(diào)整。如需了解更多詳情,,《Vivado高層次綜合教程》(UG871; http://www.xilinx.com/support/documentation/sw_manuals/xilinx2012_2/ug87... )和《Vivado設(shè)計(jì)套件用戶指南》(UG002; http://www.xilinx.com/support/documentation/sw_manuals/xil-inx2012_2/ug9... )這兩個(gè)技術(shù)文檔對(duì)您大有裨益,。